I’ve been trying to figure out what makes a Reddit submission “good” for years. If we assume the number of upvotes on a submission is a fair proxy for submission quality, optimizing a statistical model for Reddit data with submission score as a response variable might lead to interesting (and profitable) insights when transferred into other domains, such as Facebook Likes and Twitter Favorites.
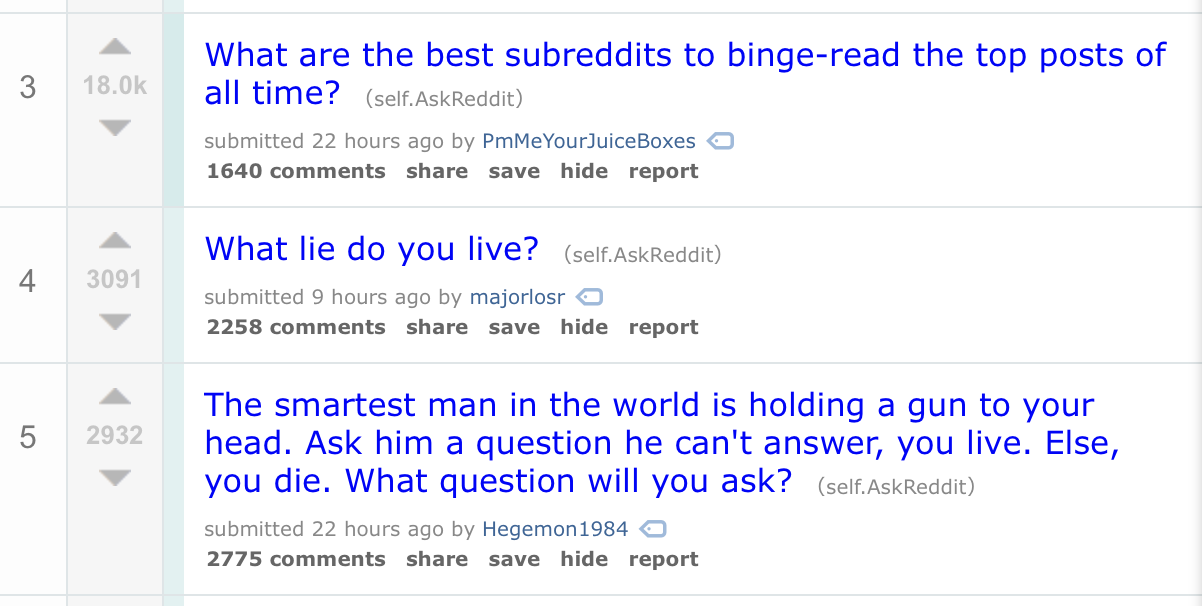
An important part of a Reddit submission is the submission title. Like news headlines, a catchy title will make a user more inclined to engage with a submission and potentially upvote.
Additionally, the time when the submission is made is important; submitting when user activity is the highest tends to lead to better results if you are trying to maximize exposure.
The actual content of the Reddit submission such as images/links to a website is likewise important, but good content is relatively difficult to optimize.
Can the magic of deep learning reconcile these concepts and create a model which can predict if a submission is a good submission? Thanks to Keras, performing deep learning on a very large number of Reddit submissions is actually pretty easy. Performing it well is a different story.
Getting the Data + Feature Engineering
It’s difficult to retrieve the content of millions of Reddit submissions at scale (ethically), so let’s initially start by building a model using submissions on /r/AskReddit: Reddit’s largest subreddit which receives 8,000+ submissions each day. /r/AskReddit is a self-post only subreddit with no external links, allowing us to focus on only the submission title and timing.
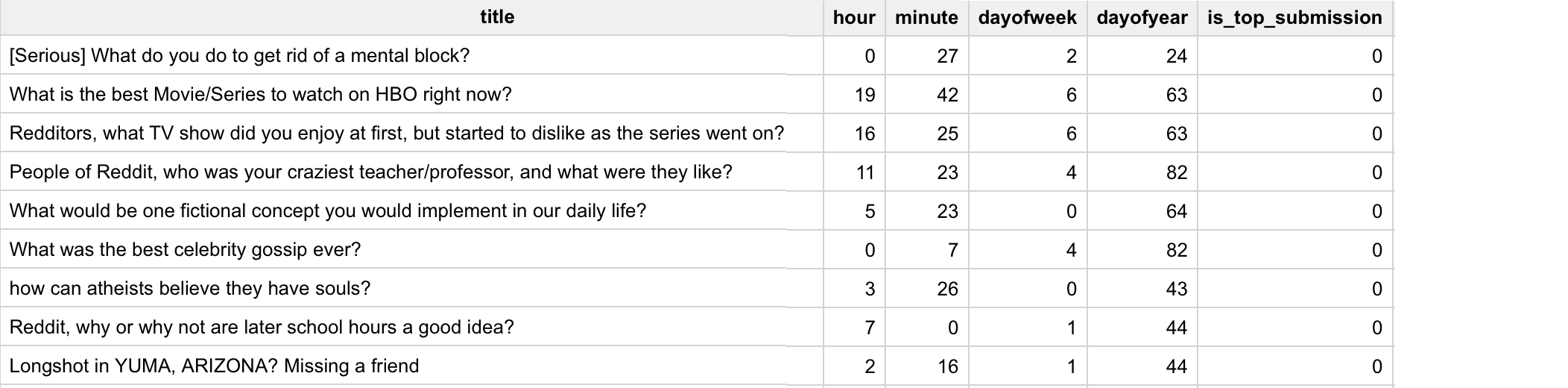
As always, we can collect large amounts of Reddit data from the public Reddit dataset on BigQuery. The submission title is available by default. The raw timestamp of the submission is also present, allowing us to extract the hour of submission (adjusted to Eastern Standard Time) and dayofweek, as used in the heatmap above. But why stop there? Since /r/AskReddit receives hundreds of submissions every hour on average, we should look at the minute level to see if there are any deeper trends (e.g. there are only 30 slots available on the first page of /new and since there is so much submission activity, it might be more advantageous to submit during off-peak times). Lastly, to account for potential changes in behavior as the year progresses, we should add a dayofyear feature, where January 1st = 1, January 2nd = 2, etc which can also account for variance due to atypical days like holidays.
Instead of predicting the raw number on upvotes of the Reddit submission (as the distribution of submission scores is heavily skewed), we should predict whether or not the submission is good, shaping the problem as a logistic regression. In this case, let’s define a “good submission” as one whose score is equal to or above the 50th percentile (median) of all submissions in /r/AskReddit. Unfortunately, the median score ends up being 2 points; although “one upvote” might be a low threshold for a “good” submission, it splits the dataset into 64% bad submissions, 36% good submissions, and setting the percentile threshold higher will result in a very unbalanced dataset for model training (a score of 2+ also implies that the submission did not get downvoted to death, which is useful).
Gathering all 976,538 /r/AskReddit submissions from January 2017 to April 2017 should be enough data for this project. Here’s the final BigQuery:
#standardSQL
SELECT id, title,
CAST(FORMAT_TIMESTAMP('%H', TIMESTAMP_SECONDS(created_utc), 'America/New_York') AS INT64) AS hour,
CAST(FORMAT_TIMESTAMP('%M', TIMESTAMP_SECONDS(created_utc), 'America/New_York') AS INT64) AS minute,
CAST(FORMAT_TIMESTAMP('%w', TIMESTAMP_SECONDS(created_utc), 'America/New_York') AS INT64) AS dayofweek,
CAST(FORMAT_TIMESTAMP('%j', TIMESTAMP_SECONDS(created_utc), 'America/New_York') AS INT64) AS dayofyear,
IF(PERCENT_RANK() OVER (ORDER BY score ASC) >= 0.50, 1, 0) as is_top_submission
FROM `fh-bigquery.reddit_posts.*`
WHERE (_TABLE_SUFFIX BETWEEN '2017_01' AND '2017_04')
AND subreddit = 'AskReddit'
Model Architecture
If you want to see the detailed data transformations and Keras code examples/outputs for this post, you can view this Jupyter Notebook.
Text processing is a good use case for deep learning, as it can identify relationships between words where older methods like tf-idf can’t. Keras, a high level deep-learning framework on top of lower frameworks like TensorFlow, can easily convert a list of texts to a padded sequence of index tokens that can interact with deep learning models, along with many other benefits. Data scientists often use recurrent neural networks that can “learn” for classifying text. However fasttext, a newer algorithm from researchers at Facebook, can perform classification tasks at an order of magnitude faster training time than RNNs, with similar predictive performance.
fasttext works by averaging word vectors. In this Reddit model architecture inspired by the official Keras fasttext example, each word in a Reddit submission title (up to 20) is mapped to a 50-dimensional vector from an Embeddings layer of up to 40,000 words. The Embeddings layer is initialized with GloVe word embeddings pre-trained on billions of words to give the model a good start. All the word vectors for a given Reddit submission title are averaged together, and then a Dense fully-connected layer outputs a probability the given text is a good submission. The gradients then backpropagate and improve the word embeddings for future batches during training.
Keras has a convenient utility to visualize deep learning models:
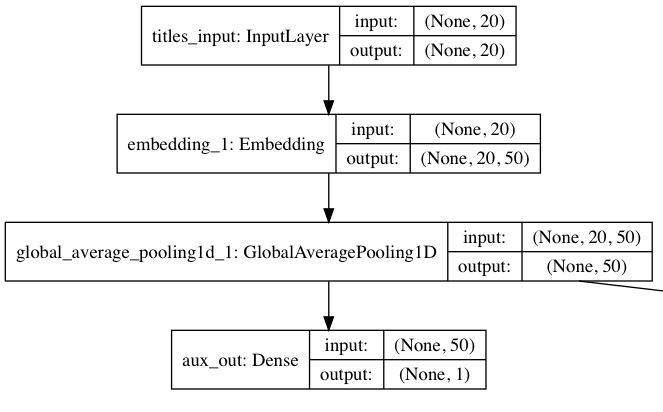
However, the first output above is the auxiliary output for regularizing the word embeddings; we still have to incorporate the submission timing data into the model.
Each of the four timing features (hour, minute, day of week, day of year) receives its own Embeddings layer, outputting a 64D vector. This allows the features to learn latent characteristics which may be missed using traditional one-hot encoding for categorical data in machine learning problems.

The 50D word average vector is concatenated with the four vectors above, resulting in a 306D vector. This combined vector is connected to another fully-connected layer which can account for hidden interactions between all five input features (plus batch normalization, which improves training speed for Dense layers). Then the model outputs a final probability prediction: the main output.
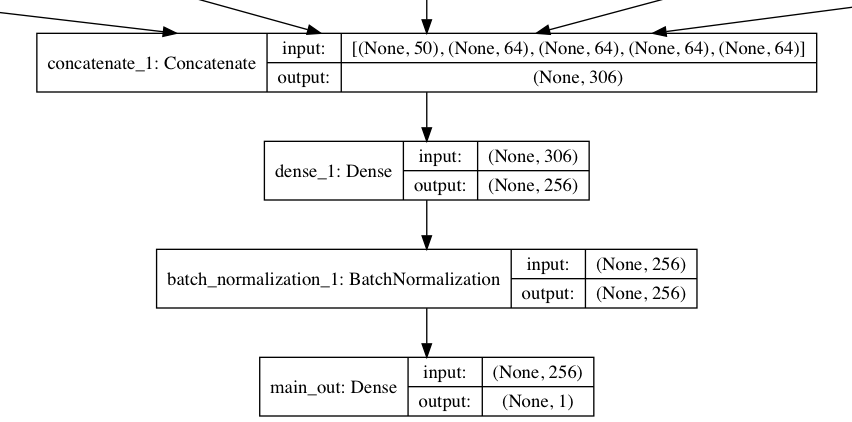
The final model:
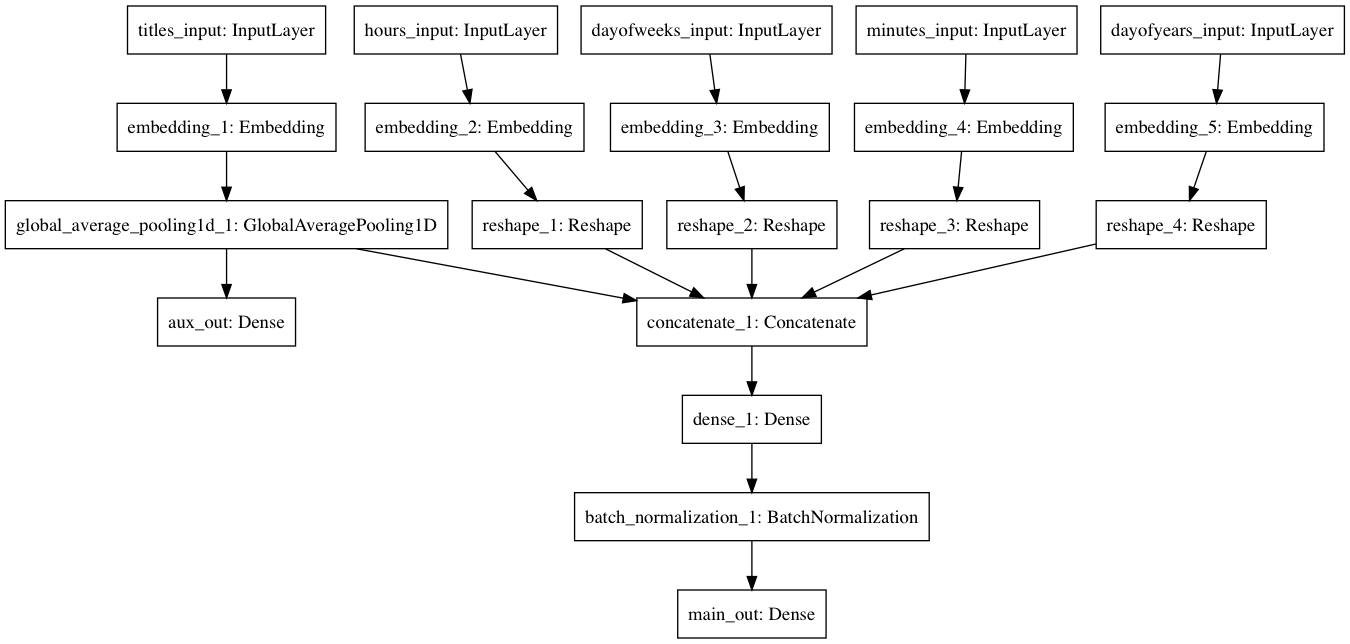
All of this sounds difficult to implement, but Keras’s functional API ensures that adding each layer and linking them together can be done in a single line of code each.
Training Results
Because the model uses no recurrent layers, it trains fast enough on a CPU despite the large dataset size.
We split the full dataset into 80%/20% training/test datasets, training the model on the former and testing the model against the latter. Keras trains a model with a simple fit command and trains for 20 epochs, where one epoch represents an entire pass of the training set.

There’s a lot happening in the console output due to the architecture, but the main metrics of interest are the main_out_acc, the accuracy of the training set through the main output, and val_main_out_acc, the accuracy of the test set. Ideally, the accuracy of both should increase as training progresses. However, the test accuracy must be better than the 64% baseline (if we just say all /r/AskReddit submissions are bad), otherwise this model is unhelpful.
Keras’s CSVLogger trivially logs all these metrics to a CSV file. Plotting the results of the 20 epochs:
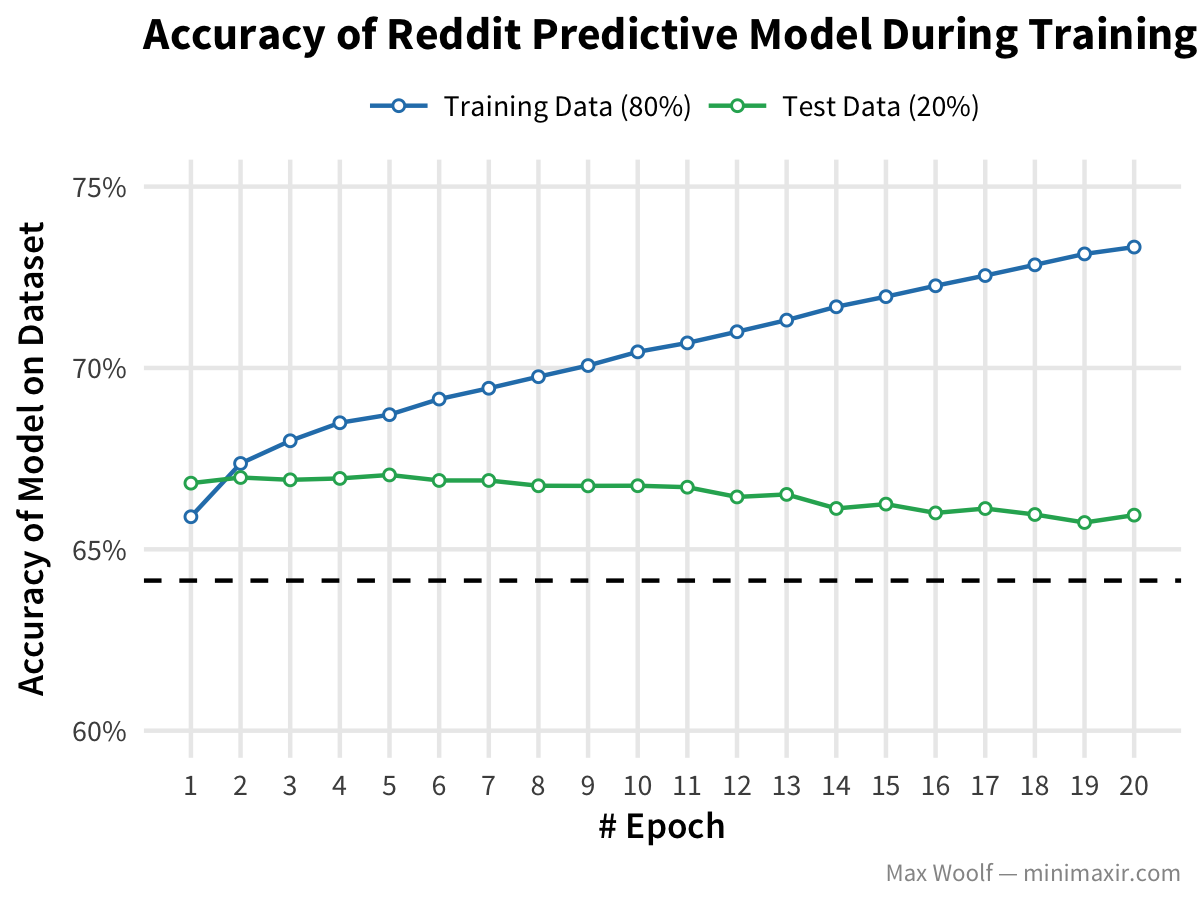
The test accuracy does indeed beat the 64% baseline; however, test accuracy decreases as training progresses. This is a sign of overfitting, possibly due to the potential disparity between texts in the training and test sets. In deep learning, you can account for overfitting by adding Dropout to relevant layers, but in my testing it did not help.
Using The Model To Optimize Reddit Submissions
At the least, we now have a model that understands the latent characteristics of an /r/AskReddit submission. But how do you apply the model in practical, real-world situations?
Let’s take a random /r/AskReddit submission: Which movie’s plot would drastically change if you removed a letter from its title?, submitted Monday, January 16th at 3:46 PM EST and receiving 4 upvotes (a “good” submission in context of this model). Plugging those input variables into the trained model results in a 0.669 probability of it being considered a good submission, which is consistent with the true results.
But what if we made minor, iterative changes to the title while keeping the time submitted unchanged? Can we improve this probability?
“Drastically” is a silly adjective; removing it and using the title Which movie’s plot would change if you removed a letter from its title? results in a greater probability of 0.682.
“Removed” is grammatically incorrect; fixing the issue and using the title Which movie’s plot would change if you remove a letter from its title? results in a greater probability of 0.692.
“Which” is also grammatically incorrect; fixing the issue and using the title What movie’s plot would change if you remove a letter from its title? results in a greater probability of 0.732.
Although adjectives are sometimes redundant, they can add an intriguing emphasis; adding a “single” and using the title What movie’s plot would change if you remove a single letter from its title? results in a greater probability of 0.753.
Not bad for a little workshopping!
Now that we have an improved title, we can find an optimal time to make the submission through brute force by calculating the probabilities for all combinations of hour, minute, and day of week (and offsetting the day of year appropriately). After doing so, I discovered that making the submission on the previous Sunday at 10:55 PM EST results in the maximum probability possible of being a good submission at 0.841 (the other top submission times are at various other minutes during that hour; the best time on a different day is the following Tuesday at 4:05 AM EST with a probability of 0.823).
In all, this model of Reddit submission success prediction is a proof of concept; there are many, many optimizations that can be done on the feature engineering side and on the data collection side (especially if we want to model subreddits other than /r/AskReddit). Predicting which submissions go viral instead of just predicting which submissions receive atleast one upvote is another, more advanced problem entirely.
Thanks to the high-level abstractions and utility functions of Keras, I was able to prototype the initial model in an afternoon instead of the weeks/months required for academic papers and software applications in this area. At the least, this little experiment serves as an example of applying Keras to a real-world dataset, and the tradeoffs that result when deep learning can’t magically solve everything. But that doesn’t mean my experiments on the Reddit data were unproductive; on the contrary, I now have a few new clever ideas how to fix some of the issues discovered, which I hope to implement soon.
Again, I strongly recommend reading the data transformations and Keras code examples in this Jupyter Notebook for more information into the methodology, as building modern deep learning models is more intuitive and less arcane than what thought pieces on Medium imply.
You can view the R and ggplot2 code used to visualize the model data in this R Notebook, including 2D projections of the Embedding layers not in this article. You can also view the images/data used for this post in this GitHub repository.
You are free to use the data visualizations/model architectures from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
