In my last post on Reddit data (I strongly suggest you read that first if you haven’t already), I noted that analyzing the words used in Reddit submissions may be useful in quantifying the relationship of those keywords in the success of a Reddit submission. Indeed, if we can find out which topics Reddit users tend to upvote, we can identify what keywords are most attractive to the Reddit “hivemind.”
First, I gathered some preliminary statistics about all submissions to the top 500 subreddits on Reddit, again using the BigQuery data dump compiled by Jason Baumgartner and Felipe Hoffa, in order to establish a good base for the analysis:
SELECT subreddit,
COUNT(*) AS num_submissions,
ROUND(AVG(score), 1) as avg_score,
NTH(25, quantiles(score,1000)) AS lower_95,
NTH(500, quantiles(score,1000)) AS median,
NTH(975, quantiles(score,1000)) AS upper_95
FROM [fh-bigquery:reddit_posts.full_corpus_201509]
GROUP BY subreddit
ORDER BY num_submissions DESC
LIMIT 500
Which results in this output. The “lower95” and and the “upper_95” columns represent the 2.5% and the 97.5% percentile respectively, which could be used to form a 95% confidence interval around the median. For example, /r/funny has a 2.5% percentile of 0 points, a median of 1 point, and a 97.5% percentile of _875 points. However, from those values, it is clear the data is heavily skewed right, which makes running statistical tests more difficult.
Now we can query the top keywords for each subreddit, whose presence in a submission is related to the highest average score within that subreddit. This requires a very intricate and optimized BigQuery. Specifically, we want the query to:
- Get the Top 500 subreddits, by number of submissions (an abridged verson of query above).
- Get all submissions from these subreddits.
- Extract the keywords from all of these submissions, using a regular expression to remove most punctuation (unfortunately, the regular expression will remove punctuation within words as well, resulting in some odd “words” in the final results) and flattening the resulting tokens into separate rows for aggregation.
- Aggregate the keywords by both subreddit and the word itself, and obtain the # of distinct submissions the word is present in, the average score among all submissions, etc.
- Keep only words which occur in atleast 1,000 distinct submissions, which is important for getting a good average.
- For each subreddit, rank each remaining word by their average score, descending.
- Keep only the Top 20 words for each subreddit. 500 subreddits x 20 words = 10,000 rows maximum, which the limit BigQuery allows for web download, so that works out well.
SELECT * FROM (
SELECT subreddit, word, num_words, avg_score, lower_95, median, upper_95, ROW_NUMBER() OVER (PARTITION BY subreddit ORDER BY avg_score DESC) score_rank
FROM (
SELECT subreddit, word, COUNT(DISTINCT(id)) AS num_words, ROUND(AVG(score), 3) AS avg_score, NTH(25, quantiles(score,1000)) AS lower_95, NTH(500, quantiles(score,1000)) AS median, NTH(975, quantiles(score,1000)) AS upper_95
FROM(FLATTEN((
SELECT SPLIT(LOWER(REGEXP_REPLACE(title, r'[^\w\']', ' ')), ' ') word, subreddit, score, id
FROM [fh-bigquery:reddit_posts.full_corpus_201509]
WHERE subreddit IN (SELECT subreddit FROM (SELECT subreddit, COUNT(*) AS c FROM [fh-bigquery:reddit_posts.full_corpus_201509] GROUP BY subreddit ORDER BY c DESC LIMIT 500))
), word))
GROUP EACH BY subreddit, word
HAVING num_words >= 1000
))
WHERE score_rank <= 20
ORDER BY subreddit, avg_score DESC
Phew! That query results in this output, which we can use to plot a bar chart for each subreddit.
Plotting the Words
The R code used to generate the charts is available in this Jupyter notebook, open-sourced on GitHub. Additionally, all 500 charts with the keyword ranks for all 500 subreddits are available in the parent repository.
After a few R tricks, I managed to chart the Top 10 keywords for each of the Top 15 subreddits:
As noted in the subtitle, each word appears in atleast 1,000 submissions by subreddit (which absorbs any messy outliers), and vertical line represents the true average upvotes per subreddit. One might argue that the median would be a better statistic instead of the median, due to the high skewness of the data. Thanks to the power of BigQuery, I was able to calculate the top medians for each of the subreddits with a slightly-tweaked query, but the chart is not as helpful. There are still a few useful implications of the median, though, which I’ll show later. (No, I don’t need to normalize the data in the chart since I am not making an apples-to-apples comparison between the values of the words among subreddits, and no, I don’t need to remove stop words since this is visualizing an average, and not a count.)
When the visualization was posted to Reddit in the /r/dataisbeautiful subreddit, it received over 3,500 upvotes. As many commenters on that submission correctly note, there are a few especially interesting observations for the keywords in those 15 subreddits, and when looking at the remaining subreddits, many trends in their keywords are made apparent.
Politicalreddit
The most notable trend with the Top 15 subreddits is in the /r/politics subreddit, which tells users to “Vote based on quality, not opinion,” but has a high affiliation for submissions specifically involving Bernie Sanders and Elizabeth Warren.
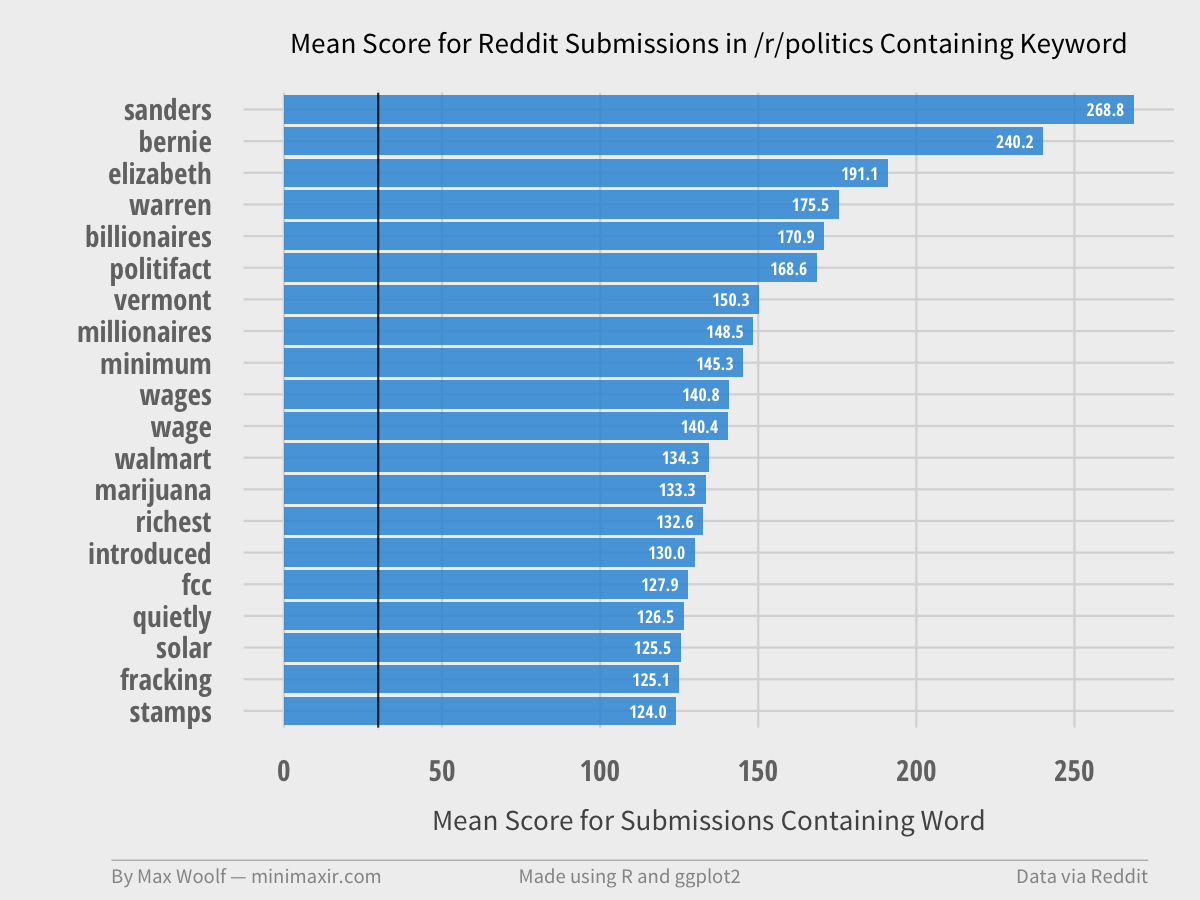
/r/technology, intended to be about “a broad spectrum of conversation as to the innovations, aspirations, applications and machinations,” has a high affiliation for political issues such as the net neutrality controversy involving the FCC, ISPs, and Comcast, and little affiliation for actual technology.
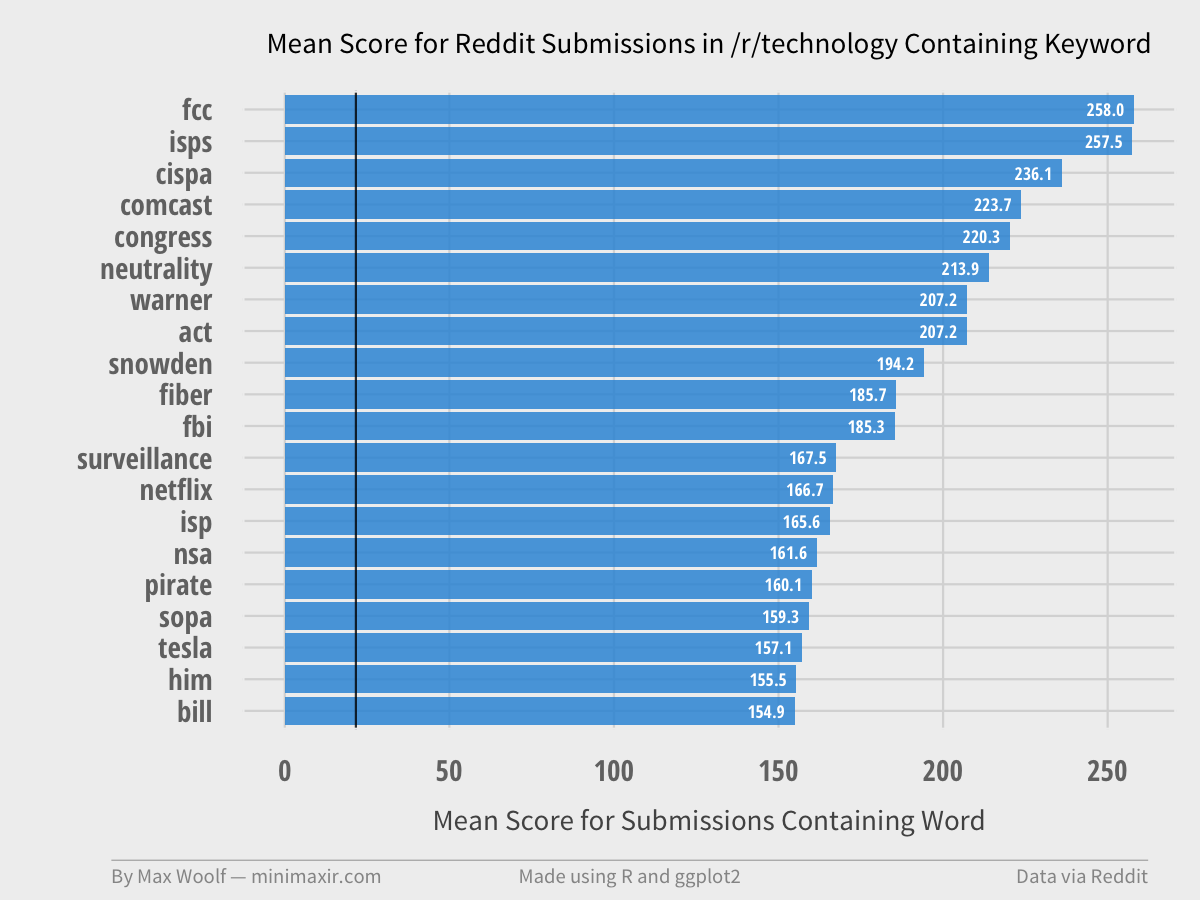
Outside the Top 15 Subreddits, the political affiliations of subreddits such as /r/Libertarian are less surprising and more funny as a result.
Storyreddit
One of the rising trends in the online publication landscape is that telling a story is more effective at generating attention. (thank BuzzFeed for that)
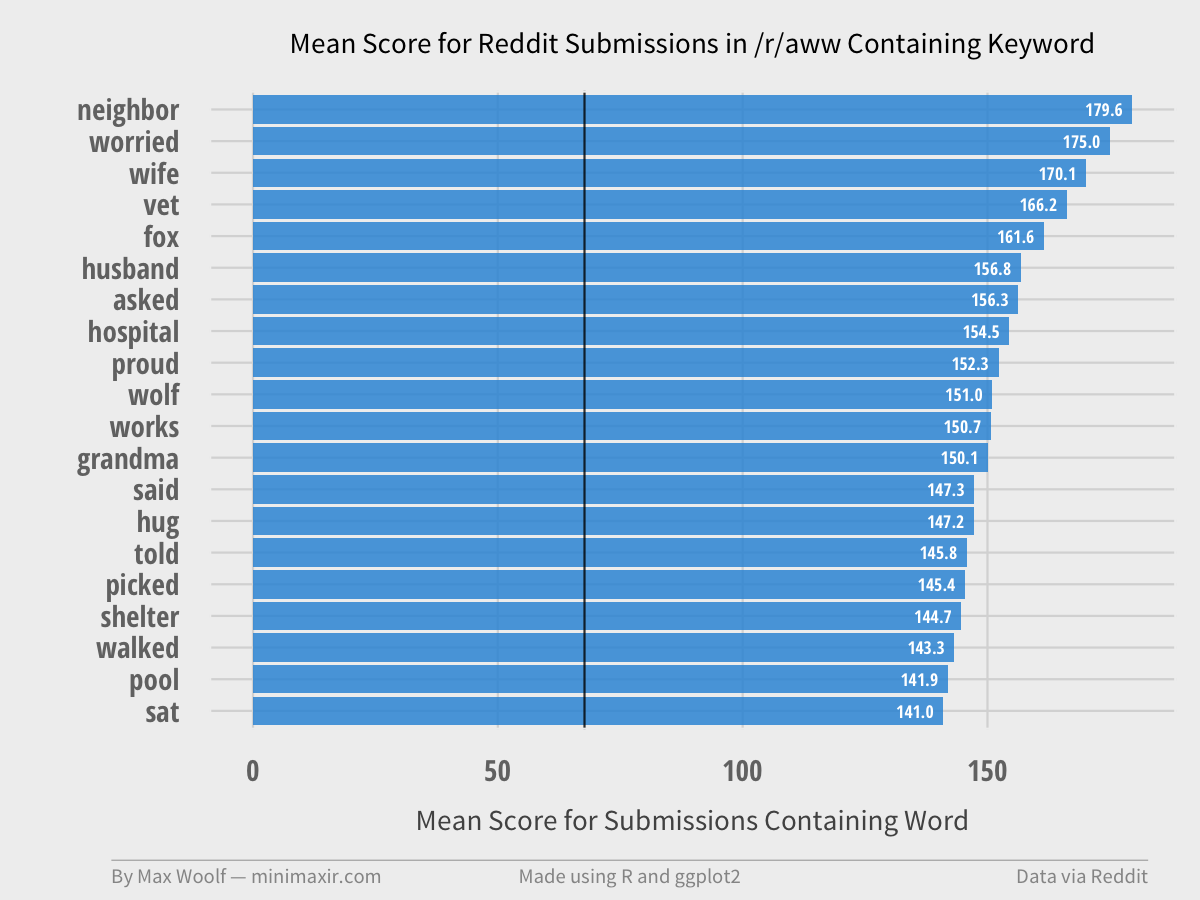
The biggest offender is /r/aww, a subreddit about animals, has a high affinity for words that aren’t animals, with only two animal words appearing in the Top 20.
The presence of story titles is also apparent in /r/Fitness, which in fairness, the atmosphere of self-improvement lends itself more to stories.
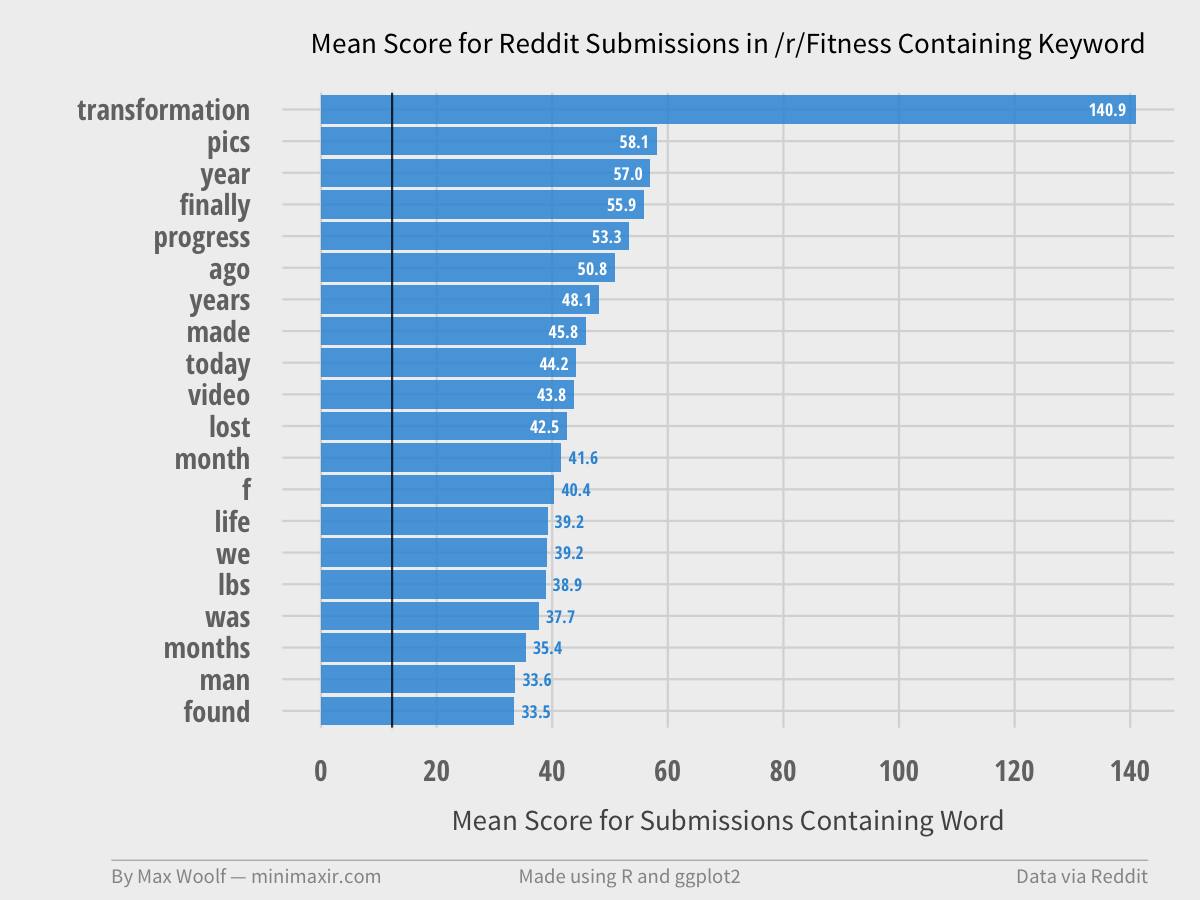
Metareddit
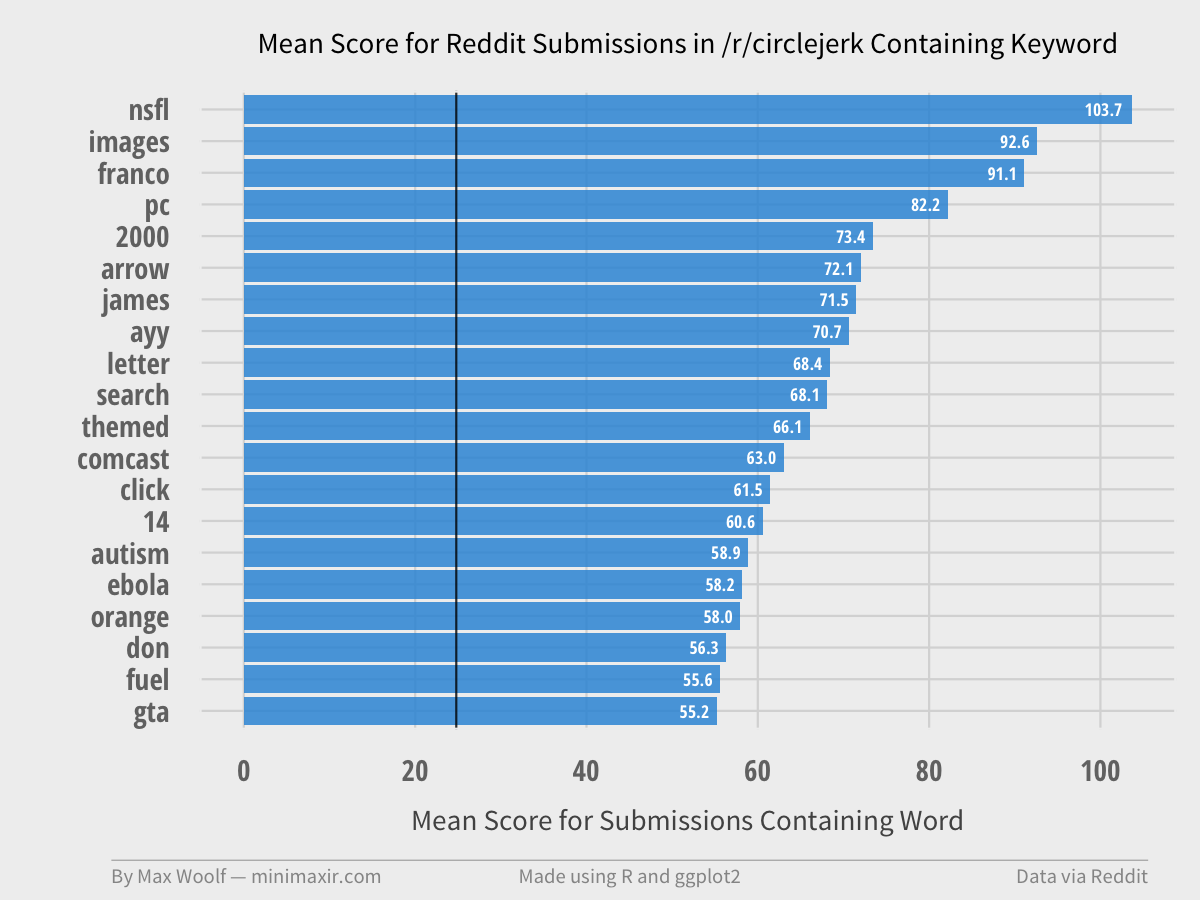
The practice of upvoting submissions just because they mention a particular topic is colloquially known as “circlejerking.” /r/circlejerk fits that well, with titles designed to satirize clickbaity issues in order to receive upvotes ironically.
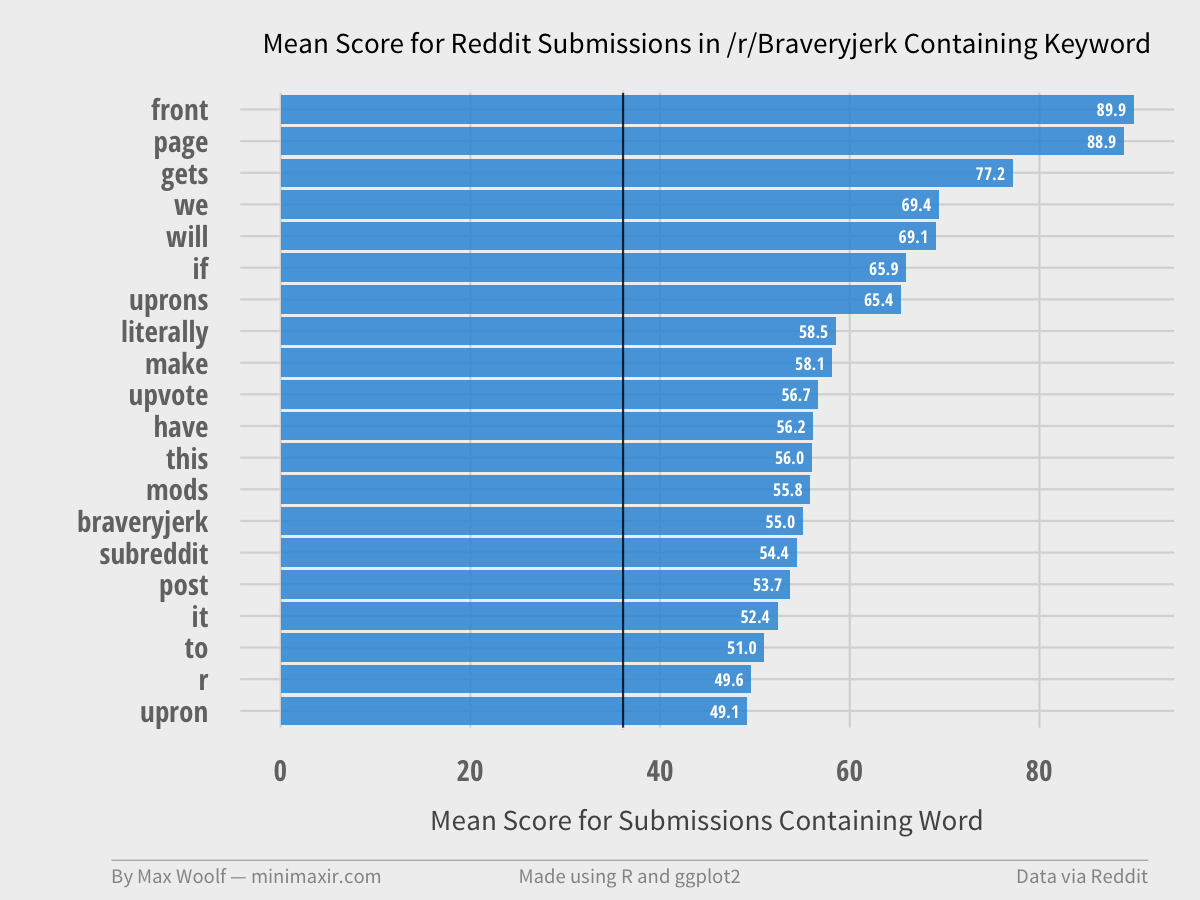
/r/Braveryjerk, however, takes this practice to its logical conclusion.
Esotericreddit
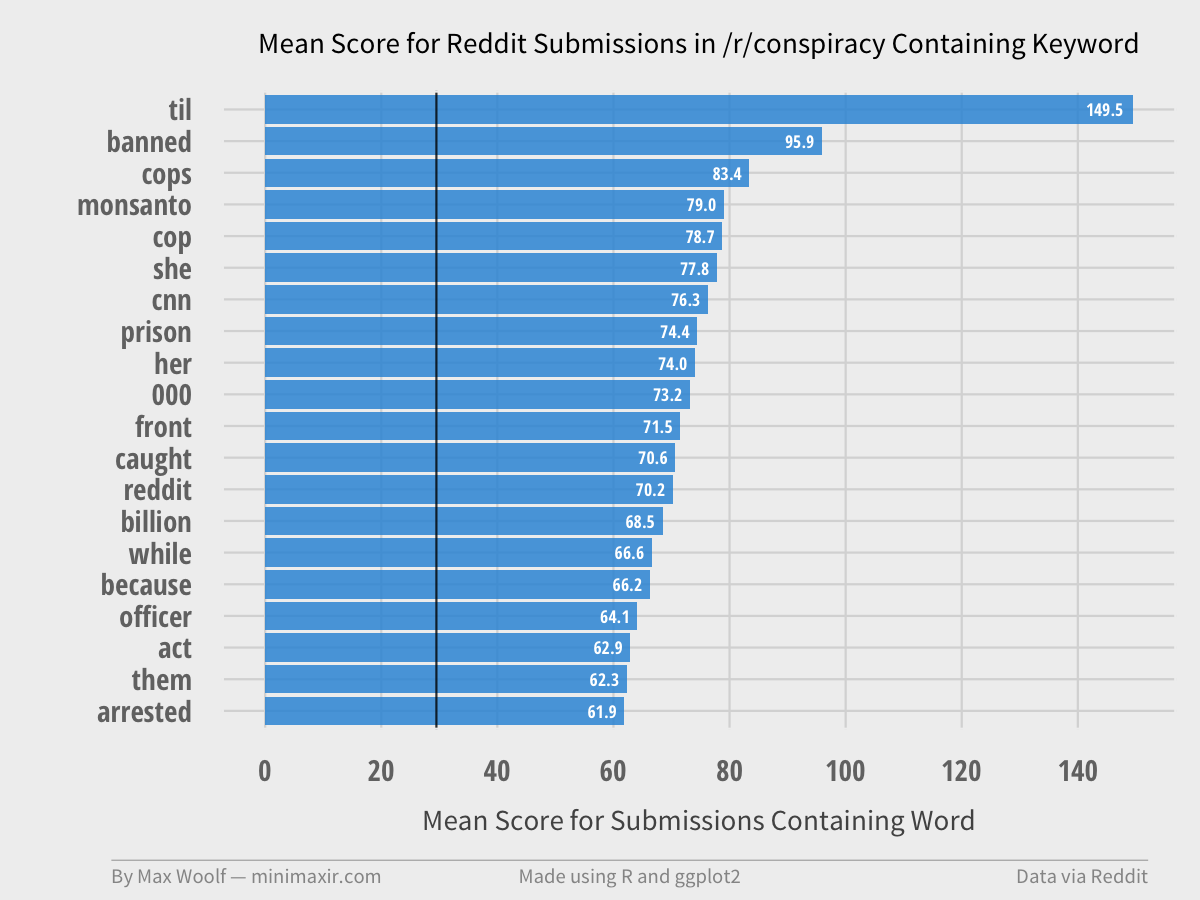
Here are a few other infamous subreddits that people have requested.
/r/conspiracy, which apparently have frequent instances of “TIL” (Today, I Learned) in titles, are simultaneously very suspicious of the actions in the /r/TIL subreddit.
The keywords in /r/teenagers captures the essence of modern social media.
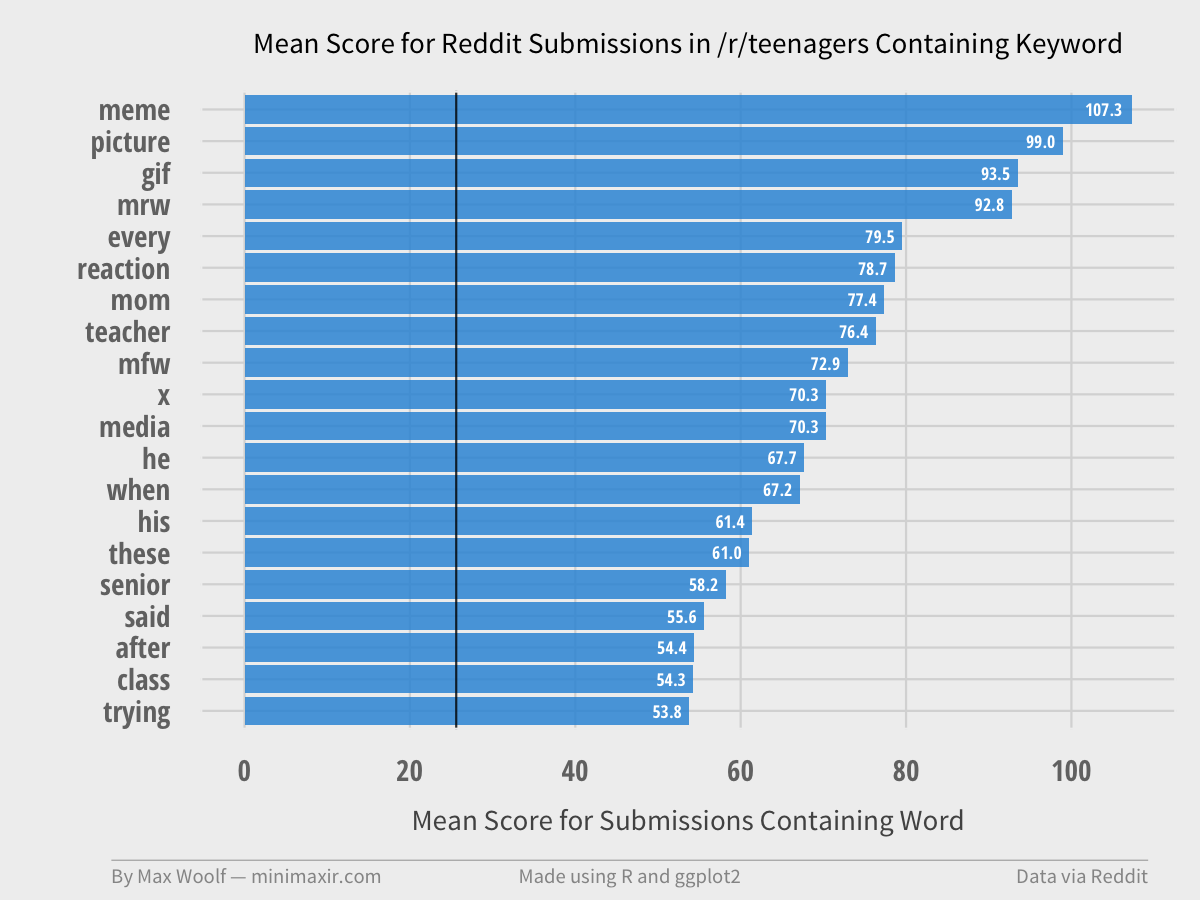
Some subreddits are just plain weird.
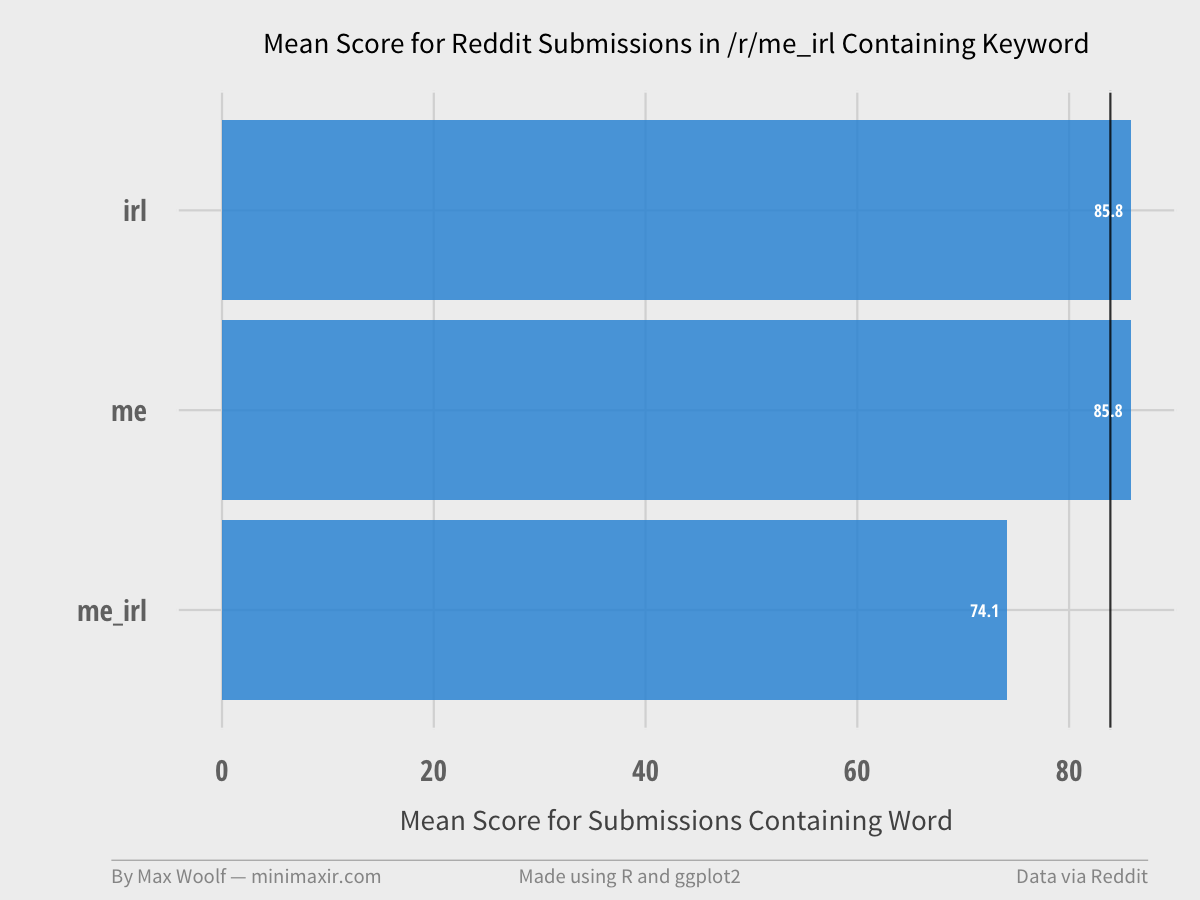
That’s /r/me_irl for you.
Looking at the Medians
As shown in the linked median image earlier, the medians for most keywords are 1 or 2, which does not provide much visual information whether a keyword is more important than another.
There are notable exceptions, however, such as with /r/Android.

That subreddit has official threads for events; it would make sense for users to upvote that whenever it appears as it’s important that it’s visible, but not necessarily as an agreement of the topic. That’s why I believe looking at the medians is a different approach than looking at the means.
Same thing with /r/relationships, where an “update” is important.
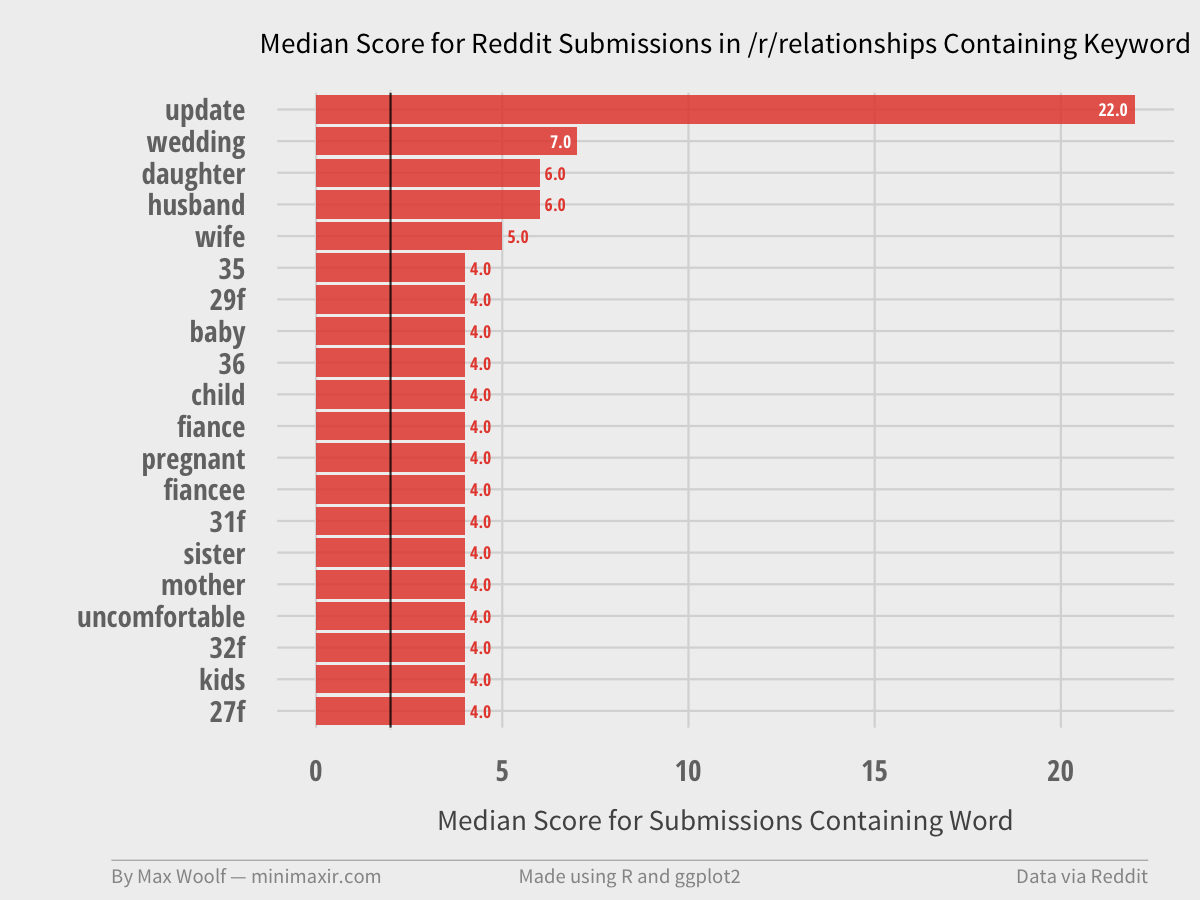
All in all, this is still just a first step for analyzing the importance of keywords in Reddit submission, and the impact of Reddit’s hivemind. The next step would be NLP techniques such as POS tagging and TDF-IF, but those require very significant and very expensive computing power. At the least, the good results with these simple analyses validates the idea for further research.
Again the R code used to generate the charts is available in this Jupyter notebook, open-sourced on GitHub. Additionally, all 500 charts with the keyword ranks for all 500 subreddits are available in the parent repository.

{kind=link}