IMDb, the Internet Movie Database, has been a popular source for data analysis and visualizations over the years. The combination of user ratings for movies and detailed movie metadata have always been fun to play with.
There are a number of tools to help get IMDb data, such as IMDbPY, which makes it easy to programmatically scrape IMDb by pretending it’s a website user and extracting the relevant data from the page’s HTML output. While it works, web scraping public data is a gray area in terms of legality; many large websites have a Terms of Service which forbids scraping, and can potentially send a DMCA take-down notice to websites redistributing scraped data.
IMDb has data licensing terms which forbid scraping and require an attribution in the form of a Information courtesy of IMDb (http://www.imdb.com). Used with permission. statement, and has also DMCAed a Kaggle IMDb dataset to hone the point.
However, there is good news! IMDb publishes an official dataset for casual data analysis! And it’s now very accessible, just choose a dataset and download (now with no hoops to jump through), and the files are in the standard TSV format.
The uncompressed files are pretty large; not “big data” large (it fits into computer memory), but Excel will explode if you try to open them in it. You have to play with the data smartly, and both R and ggplot2 have neat tricks to do just that.
First Steps
R is a popular programming language for statistical analysis. One of the most popular series of external packages is the tidyverse package, which automatically imports the ggplot2 data visualization library and other useful packages which we’ll get to one-by-one. We’ll also use scales which we’ll use later for prettier number formatting. First we’ll load these packages:
library(tidyverse)
library(scales)
And now we can load a TSV downloaded from IMDb using the read_tsv function from readr (a tidyverse package), which does what the name implies, at a much faster speed than base R (+ a couple other parameters to handle data encoding). Let’s start with the ratings file:
df_ratings <- read_tsv('title.ratings.tsv', na = "\\N", quote = '')We can preview what’s in the loaded data using dplyr (a tidyverse package), which is what we’ll be using to manipulate data for this analysis. dplyr allows you to pipe commands, making it easy to create a sequence of manipulation commands. For now, we’ll use head(), which displays the top few rows of the data frame.
df_ratings %>% head()
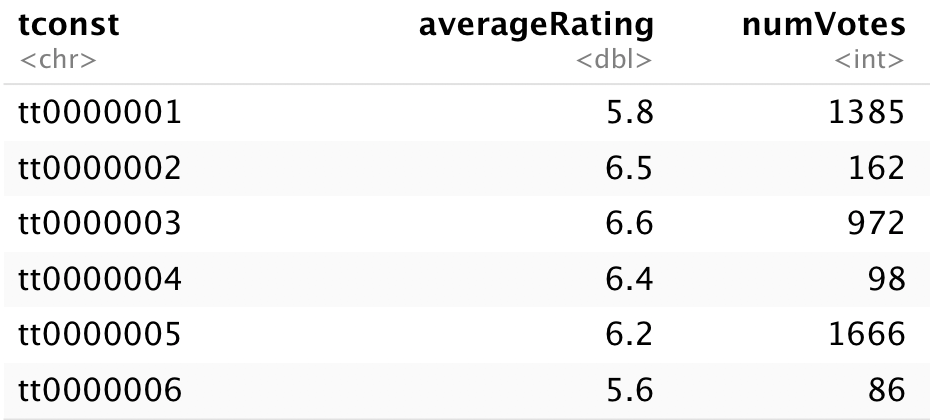
Each of the 873k rows corresponds to a single movie, an ID for the movie, its average rating (from 1 to 10), and the number of votes which contribute to that average. Since we have two numeric variables, why not test out ggplot2 by creating a scatterplot mapping them? ggplot2 takes in a data frame and names of columns as aesthetics, then you specify what type of shape to plot (a “geom”). Passing the plot to ggsave saves it as a standalone, high-quality data visualization.
plot <- ggplot(df_ratings, aes(x = numVotes, y = averageRating)) +
geom_point()
ggsave("imdb-0.png", plot, width = 4, height = 3)
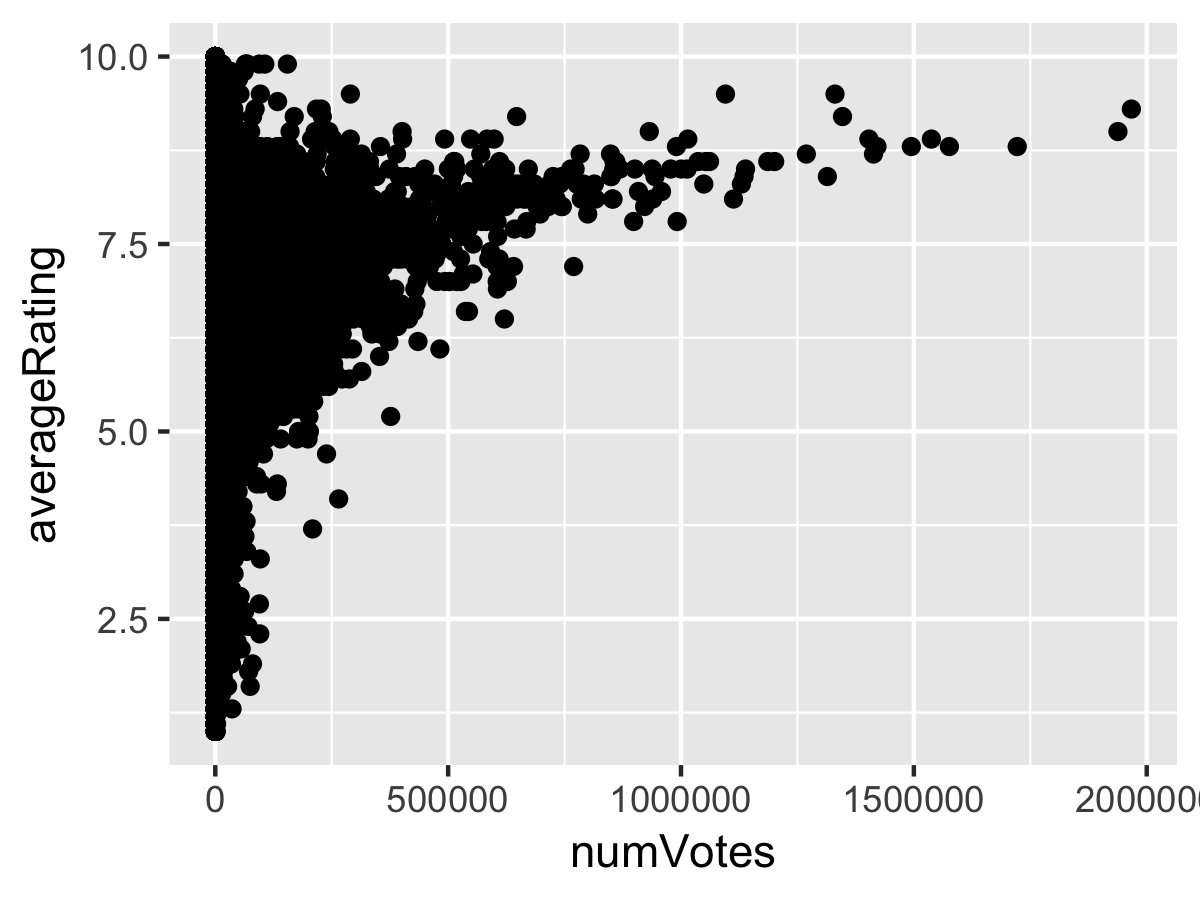
Here is nearly 1 million points on a single chart; definitely don’t try to do that in Excel! However, it’s not a useful chart since all the points are opaque and we’re not sure what the spatial density of points is. One approach to fix this issue is to create a heat map of points, which ggplot can do natively with geom_bin2d. We can color the heat map with the viridis colorblind-friendly palettes just introduced into ggplot2. We should also tweak the axes; the x-axis should be scaled logarithmically with scale_x_log10 since there are many movies with high numbers of votes and we can format those numbers with the comma function from the scales package (we can format the scale with comma too). For the y-axis, we can add explicit number breaks for each rating; R can do this neatly by setting the breaks to 1:10. Putting it all together:
plot <- ggplot(df_ratings, aes(x = numVotes, y = averageRating)) +
geom_bin2d() +
scale_x_log10(labels = comma) +
scale_y_continuous(breaks = 1:10) +
scale_fill_viridis_c(labels = comma)
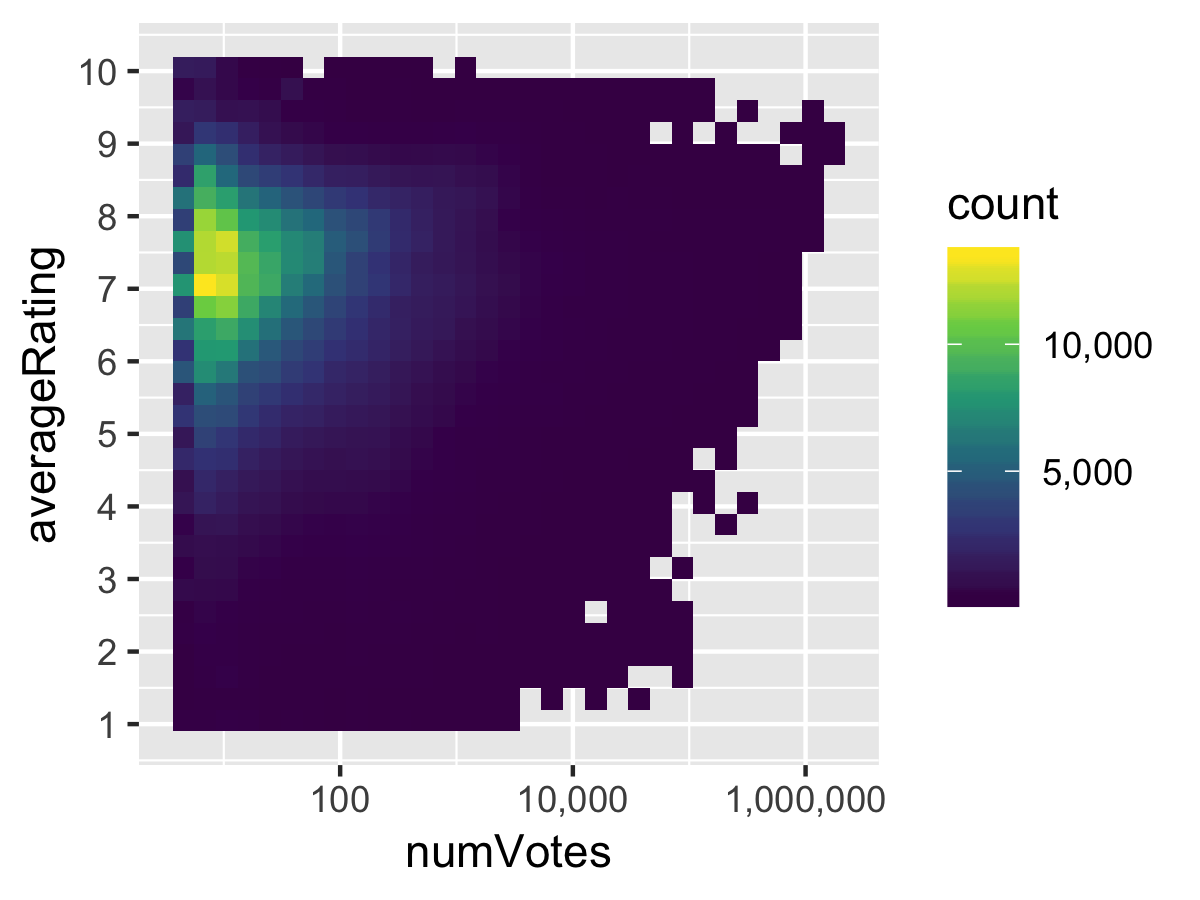
Not bad, although it unfortunately confirms that IMDb follows a Four Point Scale where average ratings tend to fall between 6 — 9.
Mapping Movies to Ratings
You may be asking “which ratings correspond to which movies?” That’s what the tconst field is for. But first, let’s load the title data from title.basics.tsv into df_basics and take a look as before.
df_basics <- read_tsv('title.basics.tsv', na = "\\N", quote = '')
We have some neat movie metadata. Notably, this table has a tconst field as well. Therefore, we can join the two tables together, adding the movie information to the corresponding row in the rating table (in this case, a left join is more appropriate than an inner/full join)
df_ratings <- df_ratings %>% left_join(df_basics)
Runtime minutes sounds interesting. Could there be a relationship between the length of a movie and its average rating on IMDb? Let’s make a heat map plot again, but with a few tweaks. With the new metadata, we can filter the table to remove bad points; let’s keep movies only (as IMDb data also contains television show data), with a runtime < 3 hours, and which have received atleast 10 votes by users to remove extraneous movies). X-axis should be tweaked to display the minutes-values in hours. The fill viridis palette can be changed to another one in the family (I personally like inferno).
More importantly, let’s discuss plot theming. If you want a minimalistic theme, add a theme_minimal to the plot, and you can pass a base_family to change the default font on the plot and a base_size to change the font size. The labs function lets you add labels to the plot (which you should always do); you have your title, x, and y parameters, but you can also add a subtitle, a caption for attribution, and a color/fill to name the scale. Putting it all together:
plot <- ggplot(df_ratings %>% filter(runtimeMinutes < 180, titleType == "movie", numVotes >= 10), aes(x = runtimeMinutes, y = averageRating)) +
geom_bin2d() +
scale_x_continuous(breaks = seq(0, 180, 60), labels = 0:3) +
scale_y_continuous(breaks = 0:10) +
scale_fill_viridis_c(option = "inferno", labels = comma) +
theme_minimal(base_family = "Source Sans Pro", base_size = 8) +
labs(title = "Relationship between Movie Runtime and Average Mobie Rating",
subtitle = "Data from IMDb retrieved July 4th, 2018",
x = "Runtime (Hours)",
y = "Average User Rating",
caption = "Max Woolf — minimaxir.com",
fill = "# Movies")
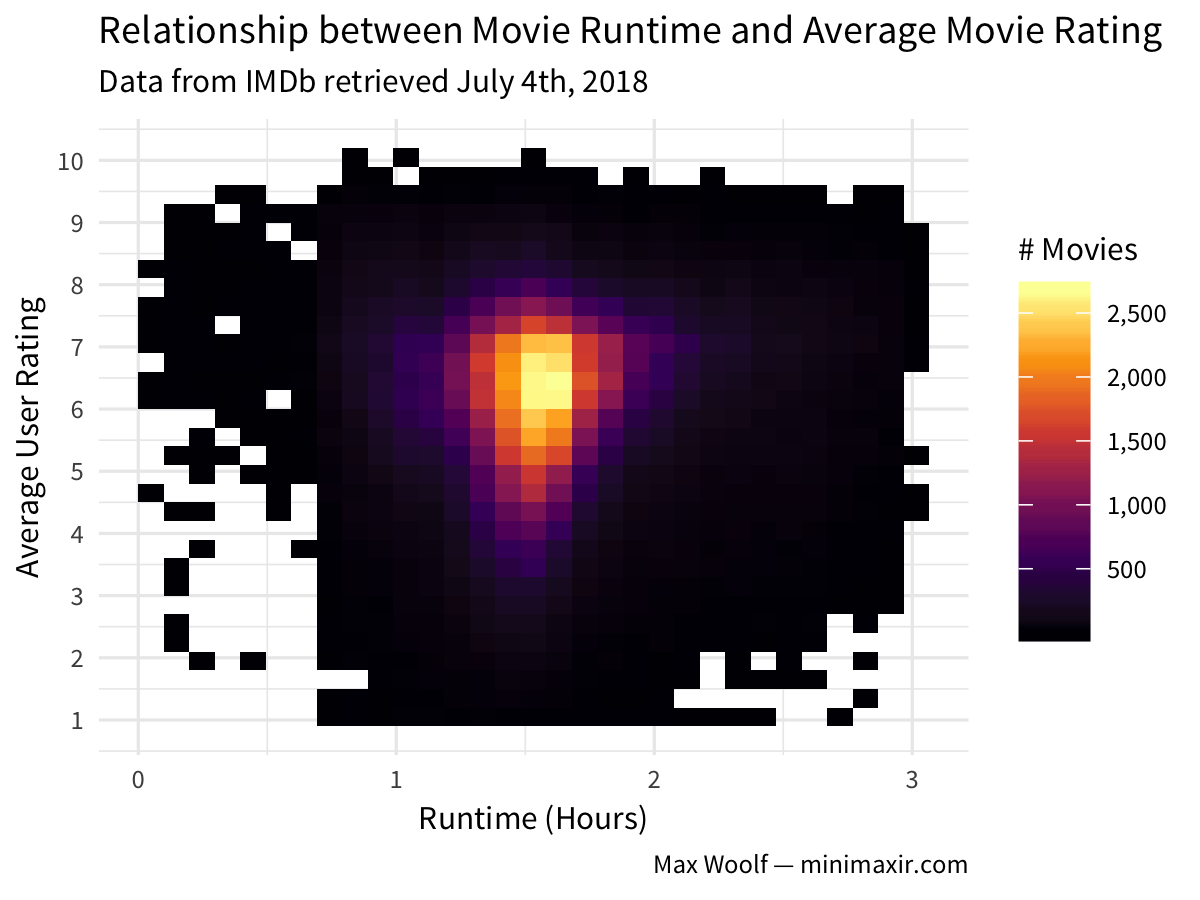
Now that’s pretty nice-looking for only a few lines of code! Albeit unhelpful, as there doesn’t appear to be a correlation.
(Note: for the rest of this post, the theming/labels code will be omitted for convenience)
How about movie ratings vs. the year the movie was made? It’s a similar plot code-wise to the one above (one perk about ggplot2 is that there’s no shame in reusing chart code!), but we can add a geom_smooth, which adds a nonparametric trendline with confidence bands for the trend; since we have a large amount of data, the bands are very tight. We can also fix the problem of “empty” bins by setting the color fill scale to logarithmic scaling. And since we’re adding a black trendline, let’s change the viridis palette to plasma for better contrast.
plot <- ggplot(df_ratings %>% filter(titleType == "movie", numVotes >= 10), aes(x = startYear, y = averageRating)) +
geom_bin2d() +
geom_smooth(color="black") +
scale_x_continuous() +
scale_y_continuous(breaks = 1:10) +
scale_fill_viridis_c(option = "plasma", labels = comma, trans = 'log10')
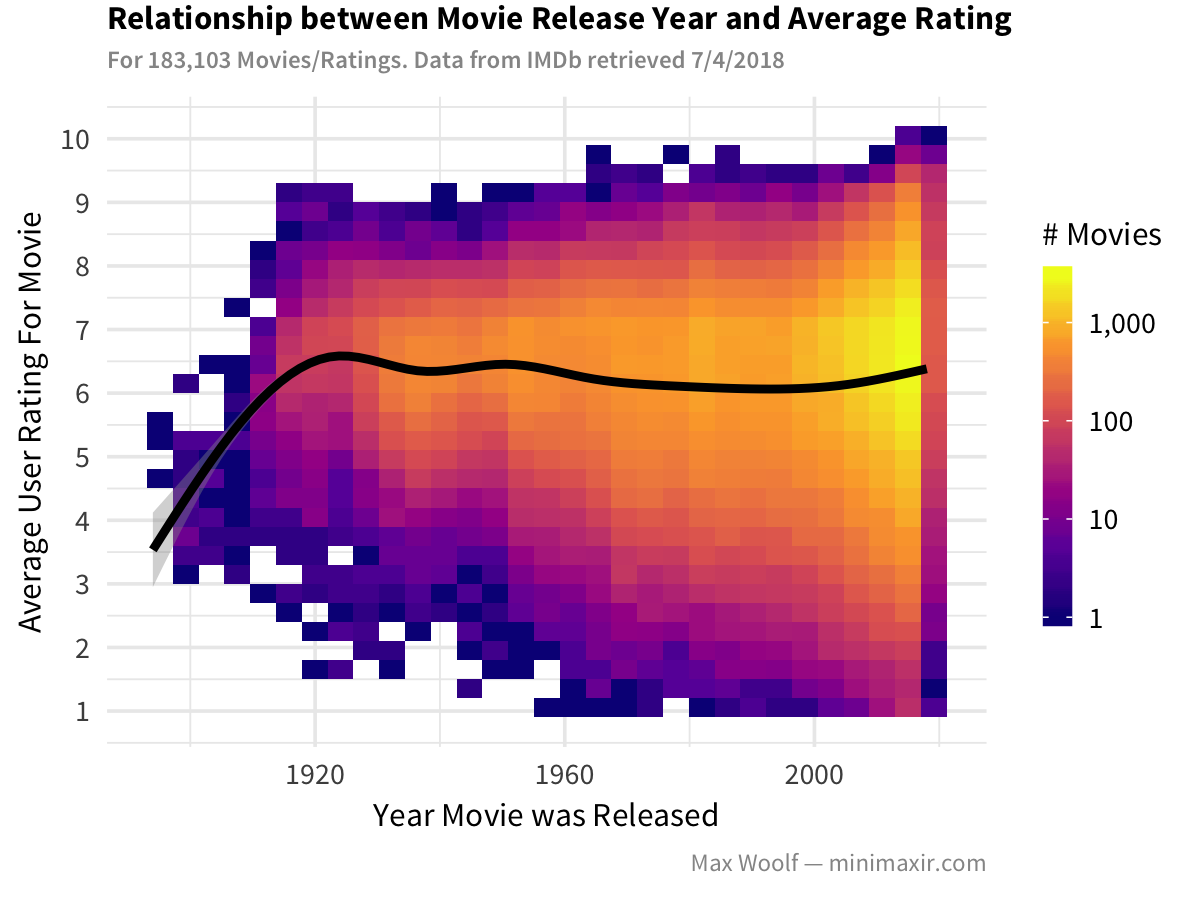
Unfortunately, this trend hasn’t changed much either, although the presence of average ratings outside the Four Point Scale has increased over time.
Mapping Lead Actors to Movies
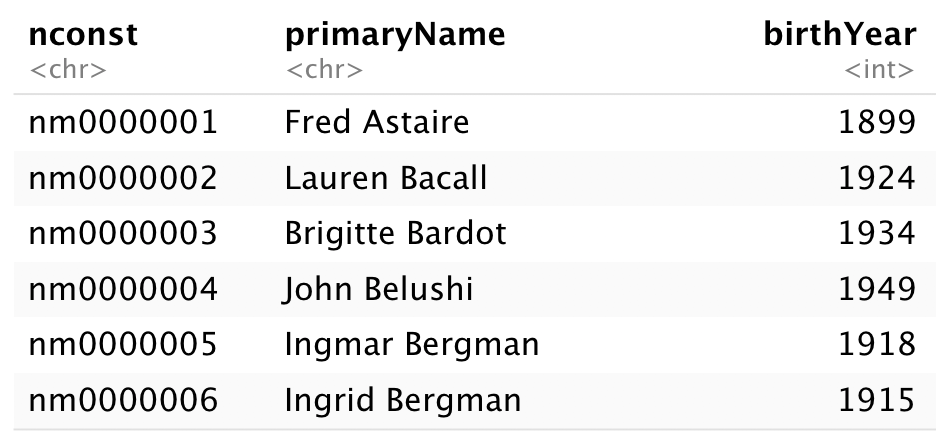
Now that we have a handle on working with the IMDb data, let’s try playing with the larger datasets. Since they take up a lot of computer memory, we only want to persist data we actually might use. After looking at the schema provided with the official datasets, the only really useful metadata about the actors is their birth year, so let’s load that, but only keep both actors/actresses (using the fast str_detect function from stringr, another tidyverse package) and the relevant fields.
df_actors <- read_tsv('name.basics.tsv', na = "\\N", quote = '') %>%
filter(str_detect(primaryProfession, "actor|actress")) %>%
select(nconst, primaryName, birthYear)
The principals dataset, the large 1.28GB TSV, is the most interesting. It’s an unnested list of the credited persons in each movie, with an ordering indicating their rank (where 1 means first, 2 means second, etc.).
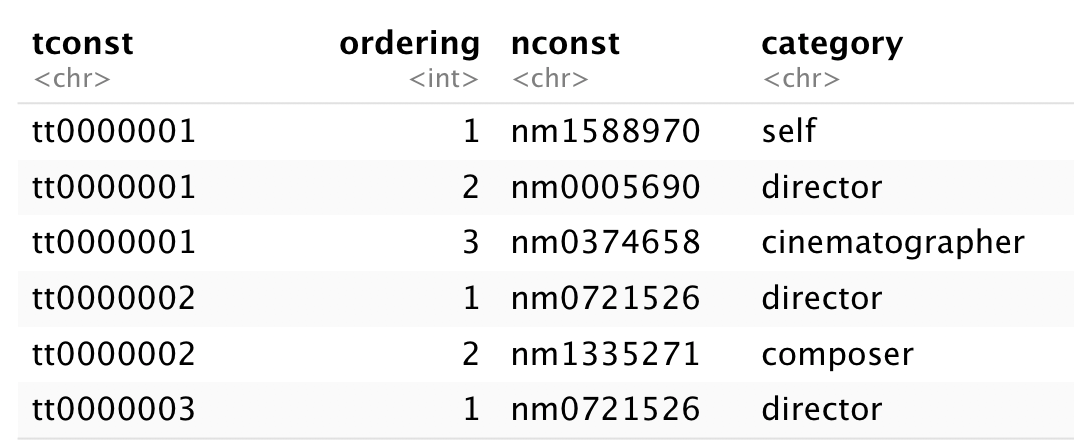
For this analysis, let’s only look at the lead actors/actresses; specifically, for each movie (identified by the tconst value), filter the dataset to where the ordering value is the lowest (in this case, the person at rank 1 may not necessarily be an actor/actress).
df_principals <- read_tsv('title.principals.tsv', na = "\\N", quote = '') %>%
filter(str_detect(category, "actor|actress")) %>%
select(tconst, ordering, nconst, category) %>%
group_by(tconst) %>%
filter(ordering == min(ordering))
Both datasets have a nconst field, so let’s join them together. And then join that to the ratings table earlier via tconst.
df_principals <- df_principals %>% left_join(df_actors)
df_ratings <- df_ratings %>% left_join(df_principals)
Now we have a fully denormalized dataset in df_ratings. Since we now have the movie release year and the birth year of the lead actor, we can now infer the age of the lead actor at the movie release. With that goal, filter out the data on the criteria we’ve used for earlier data visualizations, plus only keeping rows which have an actor’s birth year.
df_ratings_movies <- df_ratings %>%
filter(titleType == "movie", !is.na(birthYear), numVotes >= 10) %>%
mutate(age_lead = startYear - birthYear)
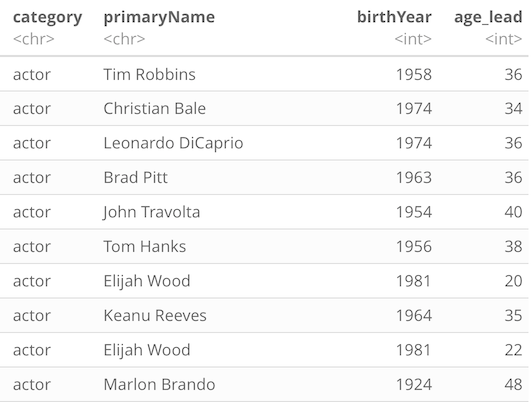
Plotting Ages
Age discrimination in movie casting has been a recurring issue in Hollywood; in fact, in 2017 a law was signed to force IMDb to remove an actor’s age upon request, which in February 2018 was ruled to be unconstitutional.
Have the ages of movie leads changed over time? For this example, we’ll use a ribbon plot to plot the ranges of ages of movie leads. A simple way to do that is, for each year, calculate the 25th percentile of the ages, the 50th percentile (i.e. the median), and the 75th percentile, where the 25th and 75th percentiles are the ribbon bounds and the line represents the median.
df_actor_ages <- df_ratings_movies %>%
group_by(startYear) %>%
summarize(low_age = quantile(age_lead, 0.25, na.rm=T),
med_age = quantile(age_lead, 0.50, na.rm=T),
high_age = quantile(age_lead, 0.75, na.rm=T))
Plotting it with ggplot2 is surprisingly simple, although you need to use different y aesthetics for the ribbon and the overlapping line.
plot <- ggplot(df_actor_ages %>% filter(startYear >= 1920) , aes(x = startYear)) +
geom_ribbon(aes(ymin = low_age, ymax = high_age), alpha = 0.2) +
geom_line(aes(y = med_age))
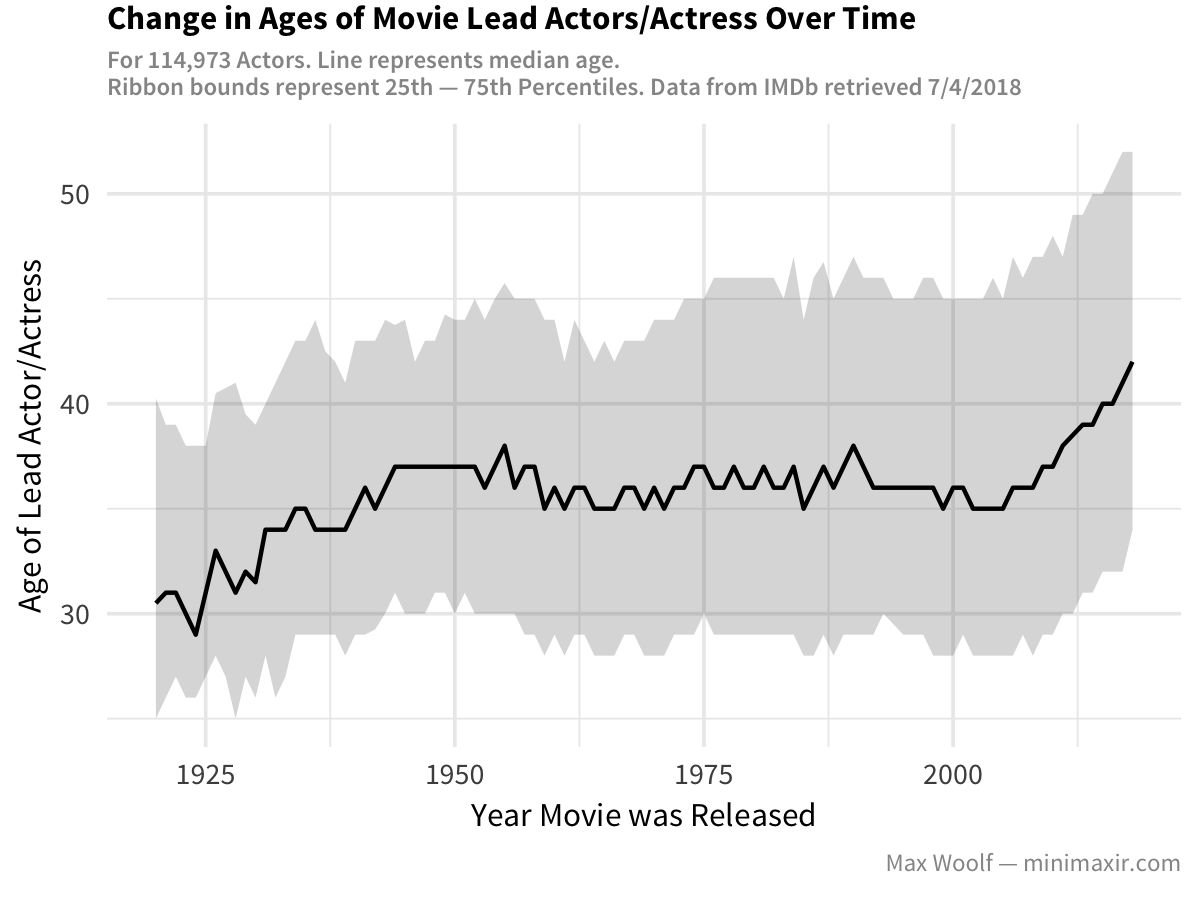
Turns out that in the 2000’s, the median age of lead actors started to increase? Both the upper and lower bounds increased too. That doesn’t coalesce with the age discrimination complaints.
Another aspect of these complaints is gender, as female actresses tend to be younger than male actors. Thanks to the magic of ggplot2 and dplyr, separating actors/actresses is relatively simple: add gender (encoded in category) as a grouping variable, add it as a color/fill aesthetic in ggplot, and set colors appropriately (I recommend the ColorBrewer qualitative palettes for categorical variables).
df_actor_ages_lead <- df_ratings_movies %>%
group_by(startYear, category) %>%
summarize(low_age = quantile(age_lead, 0.25, na.rm = T),
med_age = quantile(age_lead, 0.50, na.rm = T),
high_age = quantile(age_lead, 0.75, na.rm = T))
plot <- ggplot(df_actor_ages_lead %>% filter(startYear >= 1920), aes(x = startYear, fill = category, color = category)) +
geom_ribbon(aes(ymin = low_age, ymax = high_age), alpha = 0.2) +
geom_line(aes(y = med_age)) +
scale_fill_brewer(palette = "Set1") +
scale_color_brewer(palette = "Set1")
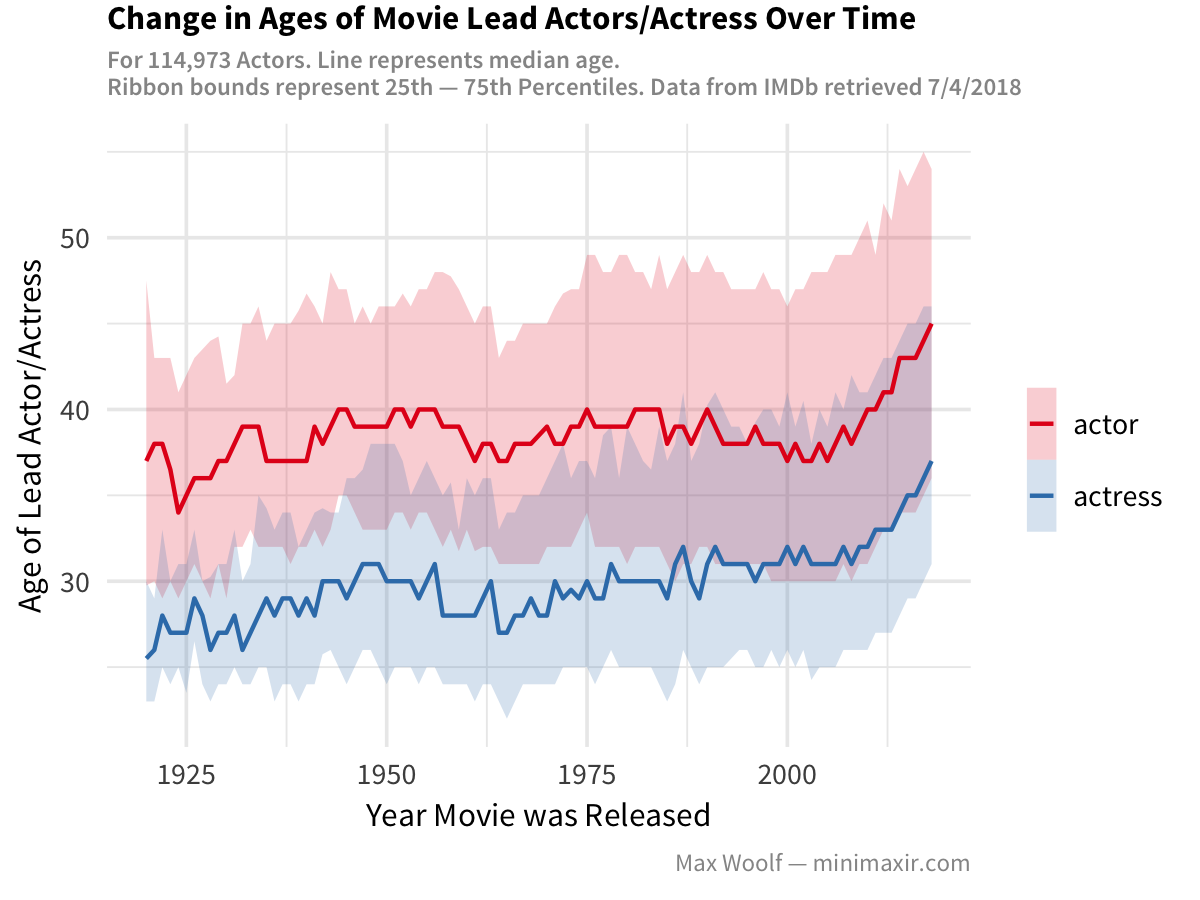
There’s about a 10-year gap between the ages of male and female leads, and the gap doesn’t change overtime. But both start to rise at the same time.
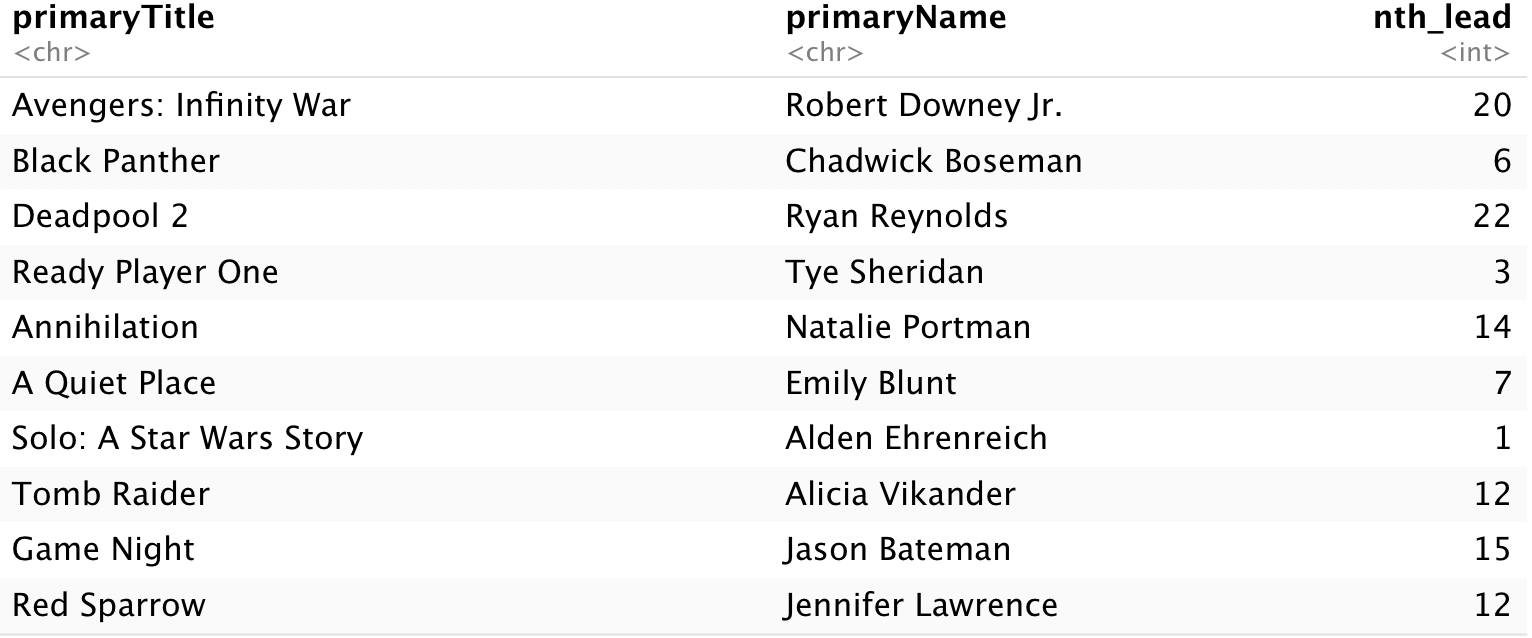
One possible explanation for this behavior is actor reuse: if Hollywood keeps casting the same actor/actresses, by construction the ages of the leads will start to steadily increase. Let’s verify that: with our list of movies and their lead actors, for each lead actor, order all their movies by release year, and add a ranking for the #th time that actor has been a lead actor. This is possible through the use of row_number in dplyr, and window functions like row_number are data science’s most useful secret.
df_ratings_movies_nth <- df_ratings_movies %>%
group_by(nconst) %>%
arrange(startYear) %>%
mutate(nth_lead = row_number())
One more ribbon plot later (w/ same code as above + custom y-axis breaks):
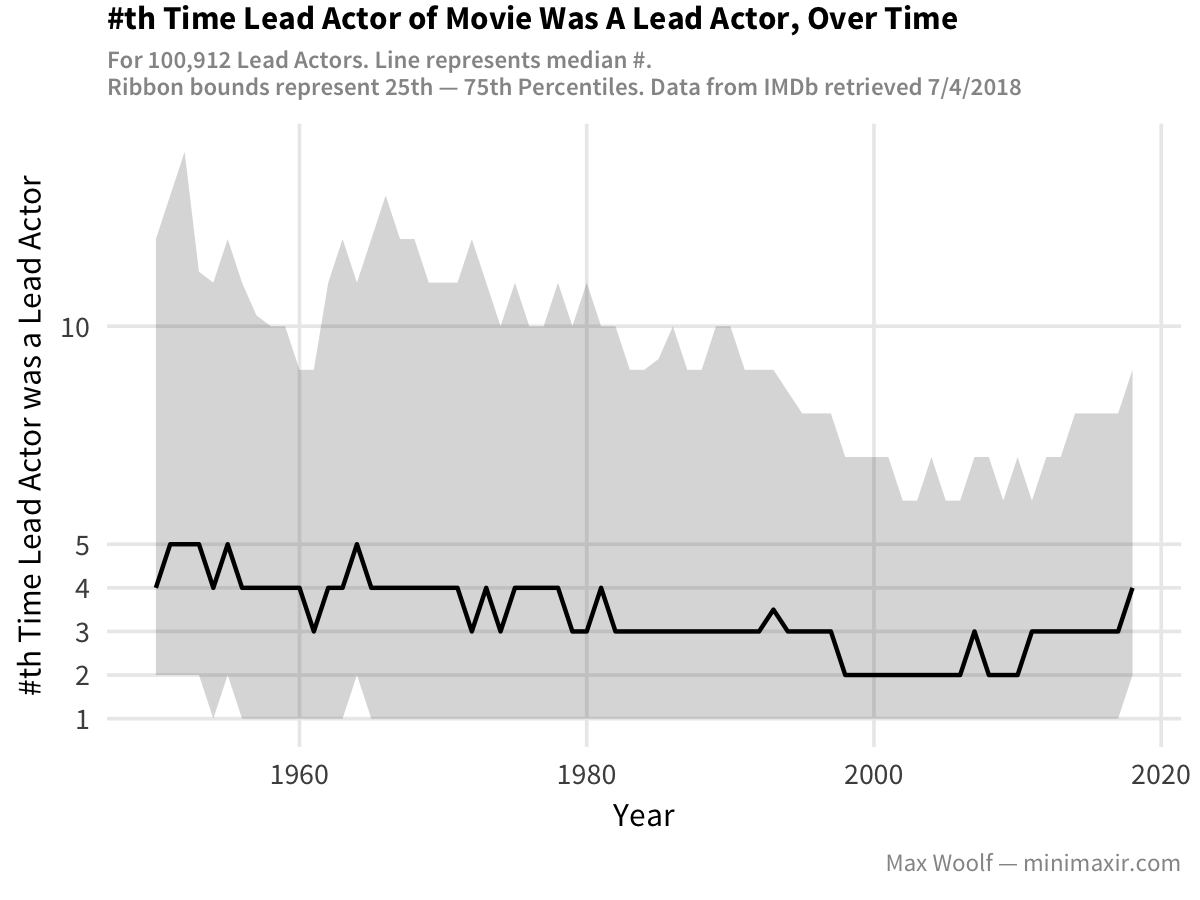
Huh. The median and upper-bound #th time has dropped over time? Hollywood has been promoting more newcomers as leads? That’s not what I expected!
More work definitely needs to be done in this area. In the meantime, the official IMDb datasets are a lot more robust than I thought they would be! And I only used a fraction of the datasets; the rest tie into TV shows, which are a bit messier. Hopefully you’ve seen a good taste of the power of R and ggplot2 for playing with big-but-not-big data!
You can view the R and ggplot used to create the data visualizations in this R Notebook, which includes many visualizations not used in this post. You can also view the images/code used for this post in this GitHub repository.
You are free to use the data visualizations from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
