One of the more interesting applications of the neural network revolution is text generation. Most popular approaches are based off of Andrej Karpathy’s char-rnn architecture/blog post, which teaches a recurrent neural network to be able to predict the next character in a sequence based on the previous n characters. As a result, a sufficiently trained network can theoretically reproduce its input source material, but since properly-trained neural networks aren’t perfect, the output can fall into a weird-but-good uncanny valley.
Many internet tutorials for text-generation neural networks simply copy an existing char-rnn implementation while changing the input dataset. It’s one approach, but there’s an opportunity for improvement with modern deep learning tooling. Thanks to frameworks like TensorFlow and Keras, I built textgenrnn, a Python package which abstracts the process of creating and training such char-rnns to a few lines of code, with numerous model architecture and training improvements such as character embeddings, attention-weighted averaging, and a decaying learning rate.
A neat benefit of textgenrnn is that it can be easily used to train neural networks on a GPU very quickly, for free using Google Colaboratory. I’ve created a notebook which lets you train your own network and generate text whenever you want with just a few clicks!
Your First Text-Generating Neural Network
Colaboratory is a notebook environment similar to Jupyter Notebooks used in other data science projects. However, Colaboratory notebooks are hosted in a short term virtual machine, with 2 vCPUs, 13GB memory, and a K80 GPU attached. For free. Normally, this configuration would cost $0.57/hr on Google Compute Engine; it sounds low, but adds up when you need to train model(s) for hours to get good results.
First, I recommend copying the notebook to your own Drive so it’ll always be there (and switch to using Google Chrome if you aren’t). The Colaboratory VM contains Python 3 and common Python packages for machine learning such as TensorFlow. But you can install more packages directly in the notebook. Like textgenrnn! Just run this cell by clicking into the cell and click the “play” button (or use Shift + Enter) and it’ll take care of the rest:

When training a new model, textgenrnn allows you to specify the size and complexity of the neural network with a wide variety of parameters:
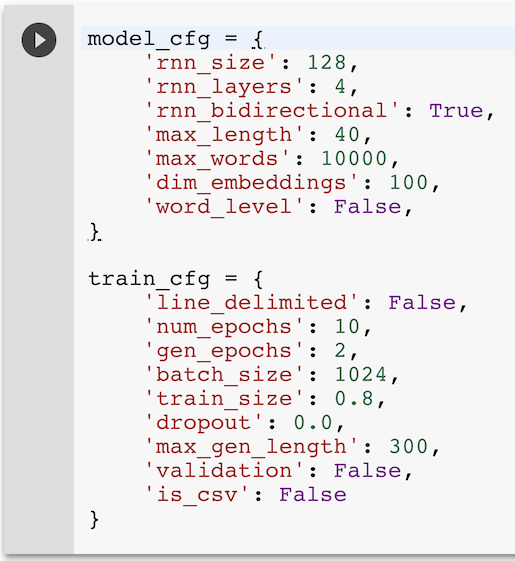
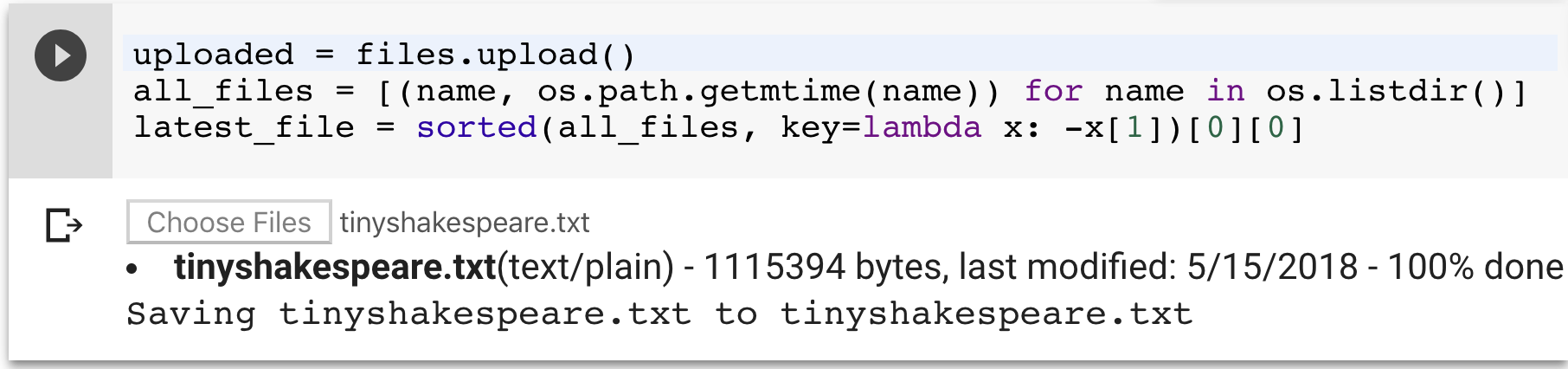
Let’s keep these default parameters for now, so run that cell to load them into memory. Run the next cell, which prompts you to upload a file. Any text file should work, even large text files! For this example, we’ll use a 1.1MB text file of Shakespeare plays also used in the char-rnn demos.
The next cell initializes an instance of textgenrnn and begins training a custom new text-generating neural network!
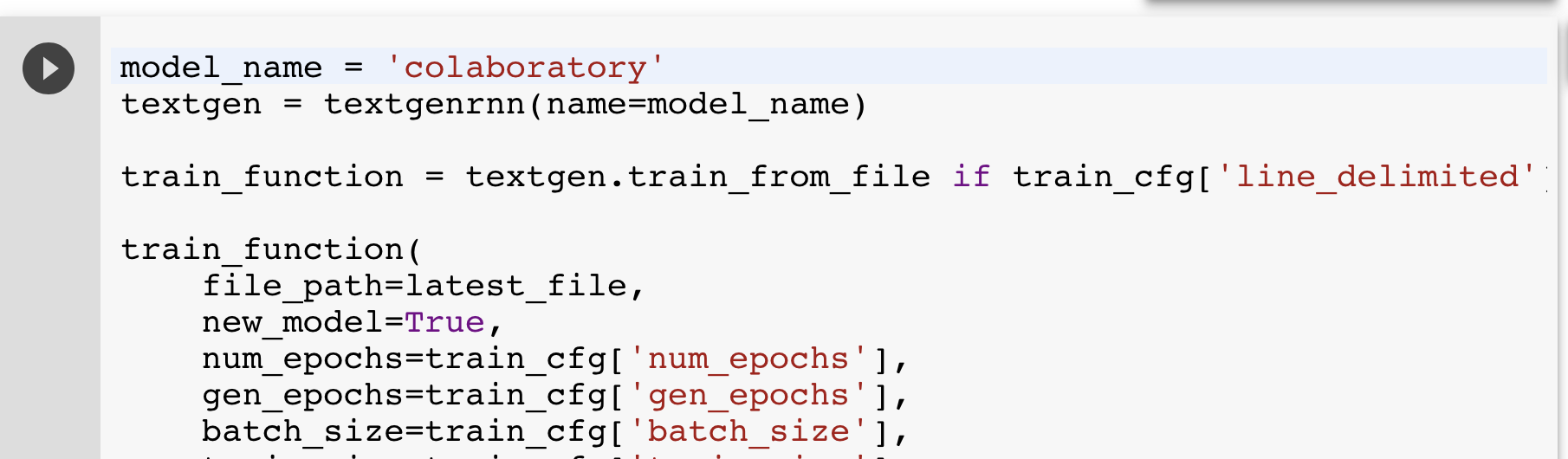
textgenrnn automatically processes the input text into character sequences ready to train the network. After every 2 epochs (a full pass through the data), the network will generate sample text at different temperatures, which represent the “creativity” of the text (i.e. it allows the model to make increasingly suboptimal predictions, which can cause hilarity to ensue). I typically like generating text at a temperature of 0.5, but for very well-trained models, you can go up to 1.0.
The quick model training speed comes from the VM’s GPU, which can perform the necessary mathematical operations much faster than with a CPU. However, in the case of recurrent neural networks, Keras recently added a CuDNN implementation of RNNs like LSTMs, which can easily tap into the GPU-native code more easily and gain a massive speed boost (about 7x as fast) compared to previous implementations! In all, for this example dataset and model architecture, training on a GPU took 5-6 minutes an epoch, while on a modern CPU, training took 1 hour and 24 minutes an epoch, a 14x speedup on the GPU!
After training is complete, running the next cell will download three files: a weights file, a vocabulary file, and a config file that are all needed to regenerate your model elsewhere.

For example, on your own personal computer. Just install textgenrnn + TensorFlow by inputting pip3 install textgenrnn tensorflow into a terminal, change to the directory where the downloaded files are located, run python3, and load the model using:
from textgenrnn import textgenrnn
textgen = textgenrnn(weights_path='colaboratory_weights.hdf5',
vocab_path='colaboratory_vocab.json',
config_path='colaboratory_config.json')
And that’s that! No GPU necessary if you’re just generating text. You can generate samples (like during training) using textgen.generate_samples(), generate a ton of samples at any temperature you like to a file using textgen.generate_to_file(), or incorporate a generated text into a Python script (e.g. a Twitter bot) using textgen.generate(1, return_as_list=True)[0] to store a text as a variable. You can view more of textgenrnn’s functions and capabilities in this demo Jupyter Notebook.
Here’s some Shakespeare generated with a 50-minute-trained model at a temperature of 0.5:
LUCENTIO:
And then shall good grave to my wife thee;
Thou would the cause the brieved to me,
And let the place and then receives:
The rest you the foren to my ways him child,
And marry that will be a parties and so set me that be deeds
And then the heart and be so shall make the most as he and stand of seat.
GLOUCESTER:
Your father and madam, or shall for the people
And dead to make the truth, or a business
As we brother to the place her great the truth;
And that which to the smaster and her father,
I am I was see the sun have to the royal true.
Not too bad, and it’s even close to iambic pentameter!
Tweaking the Model
The most important model configuration options above are rnn_size and rnn_layers: these determine the complexity of the network. Typically, you’ll see networks in tutorials be a single 128-cell or 256-cell network. However, textgenrnn’s architecture is slightly different as it has an attention layer which incorporates all the preceding model layers. As a result, it’s much better to go deeper than wider (e.g. 4x128 is better than 1x512) unless you have a very large amount of text (>10MB). rnn_bidirectional controls whether the recurrent neural network is bidirectional, that is, it processes the previous characters both forward and backward (which works great if text follows specific rules, like Shakespeare’s character headings). max_length determines the maximum number of characters for the network to use to predict the next character, which should be increased to let the network learn longer sequences, or decrease for shorter sequences.
Training has a few helpful options as well. num_epochs determines the number of full passes of the data; this can be tweaked if you want to train the model even more. batch_size determines the number of model sequences to train in a step: typically, batch size for deep learning models is 32 or 128, but with a GPU, you can get a speed increase by saturating it with the given 1024 default. train_size determines the proportion of character samples to train; setting it < 1.0 both speeds up each epoch, and prevents the model from cheating and being able to learn sequences verbatim. (You can set 'validation': True to run the model on the unused data after each epoch to see if the model is overfitting).
Let’s try playing with the parameters more on a new text dataset.
Word-Level Text Generation With Reddit Data
You might be asking “how do you obtain text data”? The popular text-generation use cases like lyric generation and movie scripts are copyright-protected so they’re harder to find, and even then, it might not be enough text data to train a new model upon (you typically want atleast 100,000 characters).
Reddit, however, has millions of submission titles which would be great to train for a model. I wrote a helper script to automatically download the top n Reddit submissions from a given subreddit over a given period of time. If you choose subreddits with similar linguistic styles in their titles, the subreddits will even blend together! Let’s play with the Top 20,000 Submissions in 2017 from each of /r/politics and /r/technology, which results in a 3.3MB file: about 3x as much data as the Shakespeare plays.

One last thing that textgenrnn can do that most char-rnn implementations can’t is generate a word level model (thanks to Keras’s tokenizers), where the model uses the n previous words/punctuation to predict the next word/punctuation. On the plus side, using only words prevents crazy typoes and since it predicts multiple “characters” at a time, max_length can be reduced proportionally, dramatically speeding up training. There’s two downsides with this approach; since words are all lowercase and punctuation is its own token, the generated text cannot be immediately used without manual editing. Additionally, the model weights will be substantially larger than a character-level model since the word-level model has to store an embedding for each word (up to max_words, which is 10,000 by default when the vocabulary size for a char-level model is 200-300).
Another advantage of the Colaboratory notebook is that you can quickly adjust model parameters, upload a new file, and immediately start training it. We’ll set 'line_delimited': True and 'rnn_bidirectional': False since there aren’t specific rules. For word level training, let’s set 'word_level': True and 'max_length': 8 to reflect the new training architecture. Since training length has been reduced to 1/5th, we can set 'num_epochs': 50 and 'gen_epoch': 10 to balance it out. Rerun the config cell to update parameters, upload the Reddit data file, and rerun training.
The resulting model is much more well trained than the Shakespeare model, and here’s a few Reddit submission titles generated at a temperature of 1.0:
report : 49 % of americans now believe all of the country ’ s effective
people like facebook like it ' s 650 of 1 %
uber accused of secretly - security popular service ( likely oklahoma )
equifax breach fallout : your salary is dead
sanders uses texas shooter ' s iphone sales
adobe videos will be used to sell the web
apple to hold cash for $ 500 service
fitbit just targeting solar energy
george bush ' s concept car ‘ goes for all the biggest controversy .
Those look pretty good, although they may need a little editing before posting on social media.
Followup
These examples only train the model for little time as a demo of textgenrnn’s fast learning; there’s nothing stopping you from increasing num_epochs even more to further refine a model. However, from my experience, the training cell times out after 4 hours; set num_epochs accordingly, although in my experience that’s all you need before the network converges.
In practice, I used this Colaboratory notebook to train many models for /r/SubredditNN, a Reddit subreddit where only text-generating neural network bots trained on other subreddits. And the results are very funny:
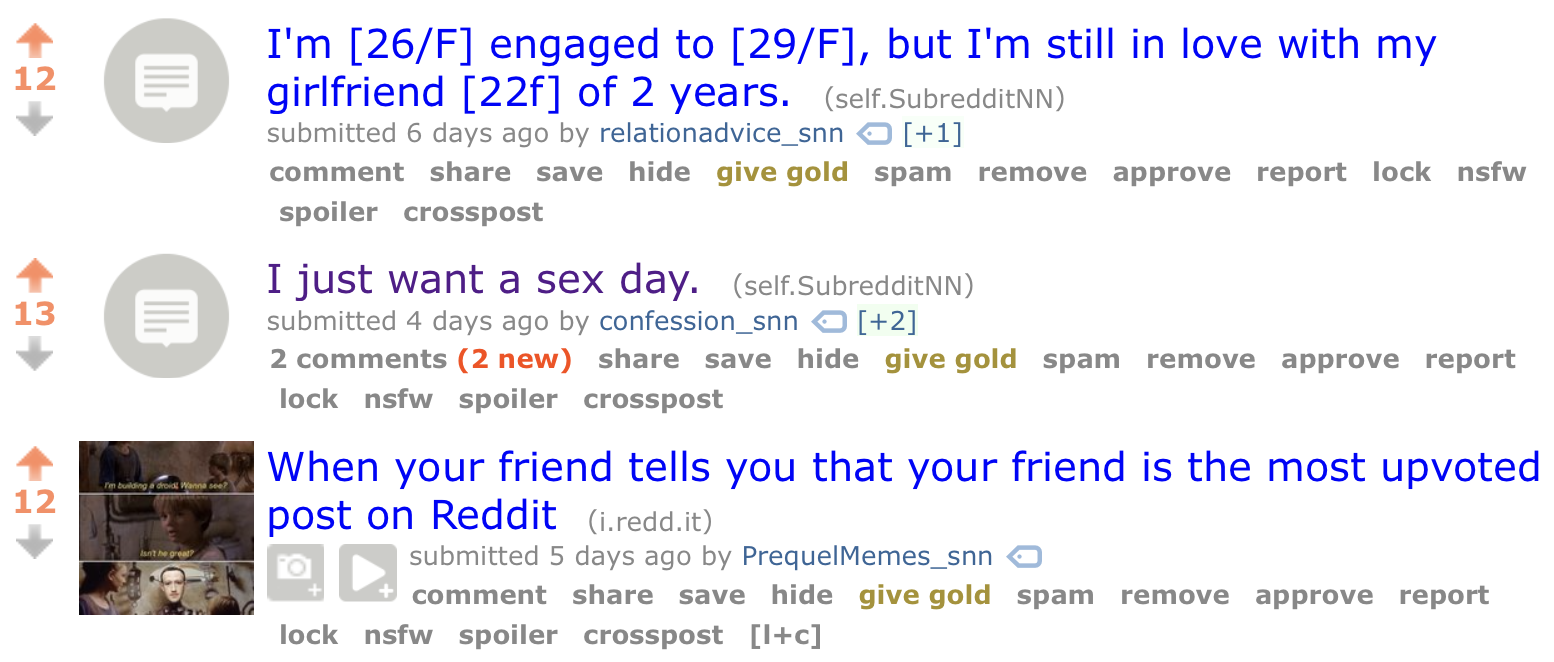
Although text generating neural networks aren’t at the point where they can write entire articles by themselves, there are still many opportunities to use it just for fun! And thanks to textgenrnn, it’s easy, fast, and cost-effective for anyone to do! Let me know if you make any interesting neural networks with textgenrnn and this Notebook!
