A few months ago, I performed benchmarks of deep learning frameworks in the cloud, with a followup focusing on the cost difference between using GPUs and CPUs. And just a few months later, the landscape has changed, with significant updates to the low-level NVIDIA cuDNN library which powers the raw learning on the GPU, the TensorFlow and CNTK deep learning frameworks, and the higher-level Keras framework which uses TensorFlow/CNTK as backends for easy deep learning model training.
As a bonus to the framework updates, Google recently released the newest generation of NVIDIA cloud GPUs, the Pascal-based P100, onto Google Compute Engine which touts an up-to-10x performance increase to the current K80 GPUs used in cloud computing. As a bonus bonus, Google recently cut the prices of both K80 and P100 GPU instances by up to 36%.
The results of my earlier benchmarks favored preemptible instances with many CPUs as the most cost efficient option (where a preemptable instance can only last for up to 24 hours and could end prematurely). A 36% price cut to GPU instances, in addition to the potential new benefits offered by software and GPU updates, however, might be enough to tip the cost-efficiency scales back in favor of GPUs. It’s a good idea to rerun the experiment with updated VMs and see what happens.
Benchmark Setup
As with the original benchmark, I set up a Docker container containing the deep learning frameworks (based on cuDNN 6, the latest version of cuDNN natively supported by the frameworks) that can be used to train each model independently. The Keras benchmark scripts run on the containers are based off of real world use cases of deep learning.
The 6 hardware/software configurations and Google Compute Engine pricings for the tests are:
- A K80 GPU (attached to a
n1-standard-1instance), tested with both TensorFlow (1.4) and CNTK (2.2): $0.4975 / hour. - A P100 GPU (attached to a
n1-standard-1instance), tested with both TensorFlow and CNTK: $1.5075 / hour. - A preemptable
n1-highcpu-32instance, with 32 vCPUs based on the Intel Skylake architecture, tested with TensorFlow only: $0.2400 / hour - A preemptable
n1-highcpu-16instance, with 16 vCPUs based on the Intel Skylake architecture, tested with TensorFlow only: $0.1200 / hour
A single K80 GPU uses 1/2 a GPU board while a single P100 uses a full GPU board, which in an ideal world would suggest that the P100 is twice as fast at the K80 at minimum. But even so, the P100 configuration is about 3 times as expensive, so even if a model is trained in half the time, it may not necessarily be cheaper with the P100.
Also, the CPU tests use TensorFlow as installed via the recommended method through pip, since compiling the TensorFlow binary from scratch to take advantage of CPU instructions as with my previous test is not a pragmatic workflow for casual use.
Benchmark Results
When a fresh-out-of-a-AI-MOOC engineer wants to experiment with deep learning in the cloud, typically they use a K80 + TensorFlow setup, so we’ll use that as the base configuration.
For each model architecture and software/hardware configuration, I calculate the total training time relative to the base configuration instance training for running the model training for the provided test script. In all cases, the P100 GPU should perform better than the K80, and 32 vCPUs should train faster than 16 vCPUs. The question is how much faster?
Let’s start using the MNIST dataset of handwritten digits plus the common multilayer perceptron (MLP) architecture, with dense fully-connected layers. Lower training time is better.
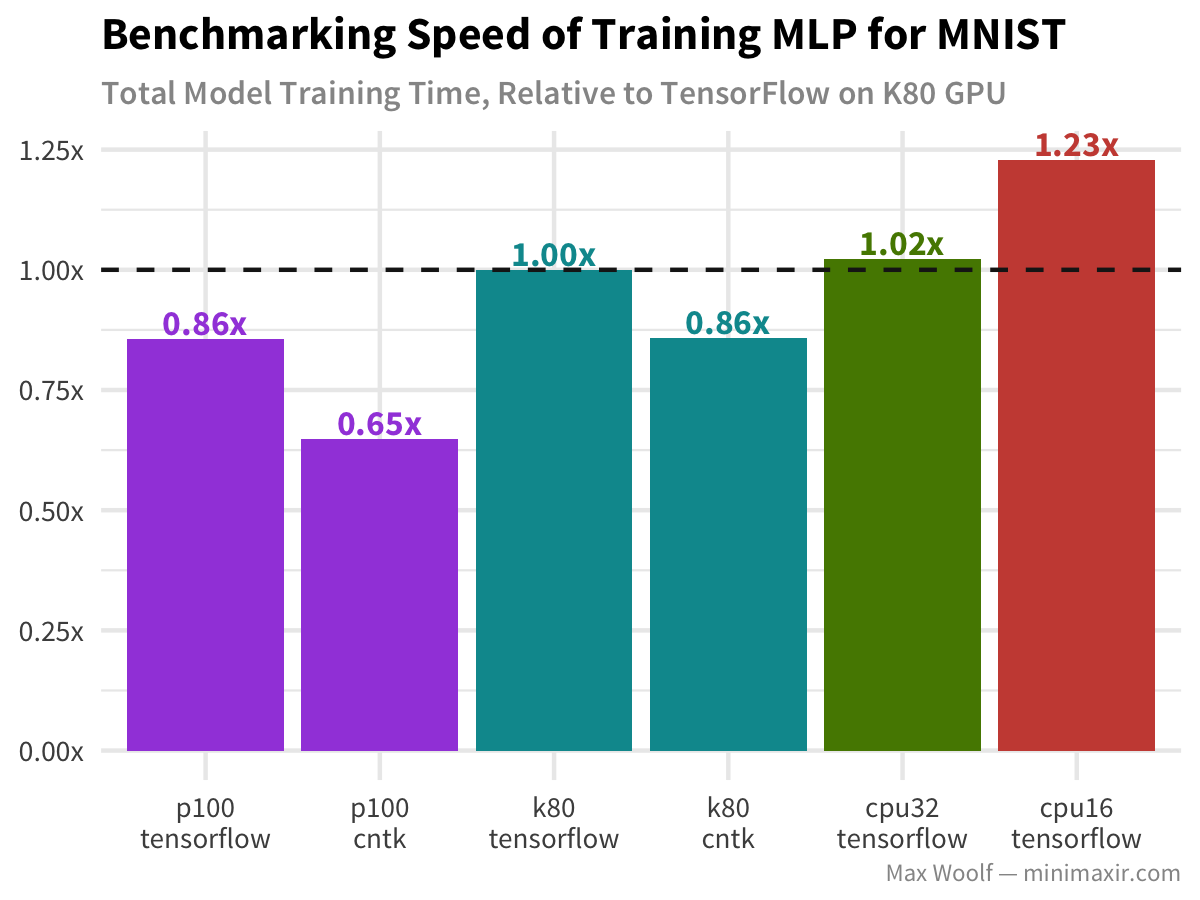
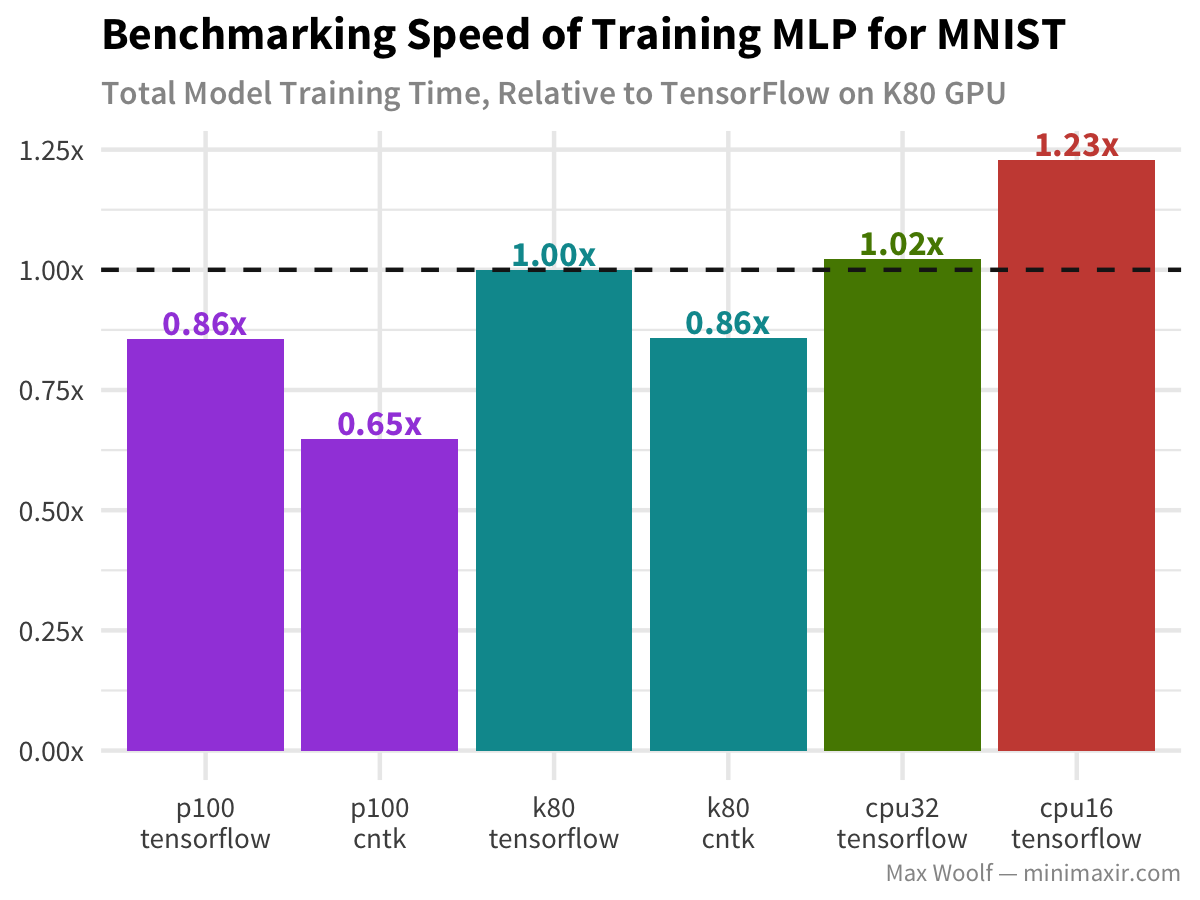
For this task, CNTK appears to be more effective than TensorFlow. Indeed, the P100 is faster than the K80 for the corresponding framework, although it’s not a dramatic difference. However, since the task is simple, the CPU performance is close to that of the GPU, which implies that the GPU is not as cost effective for a simple architecture.
For each model architecture and configuration, I calculate a normalized training cost relative to the cost of the base configuration training. Because GCE instance costs are prorated, we can simply calculate experiment cost by multiplying the total number of seconds the experiment runs by the cost of the instance (per second).
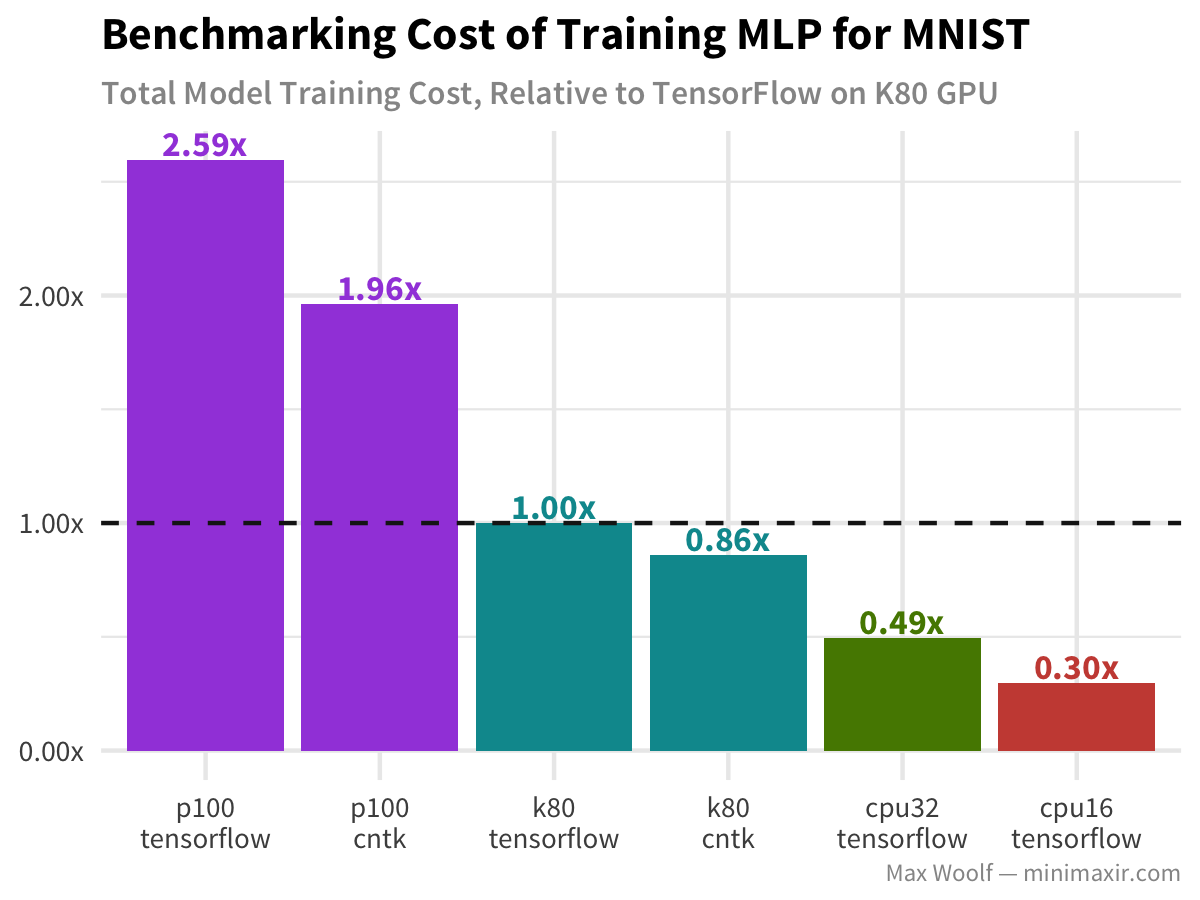
Unsurprisingly, CPUs are more cost effective. However, the P100 is more cost ineffective for this task than the K80.
Now, let’s look at the same dataset with a convolutional neural network (CNN) approach for digit classification. Since CNNs are typically used for computer vision tasks, new graphic card architectures are optimized for CNN workflows, so it will be interesting to see how the P100 performs compared to the K80:
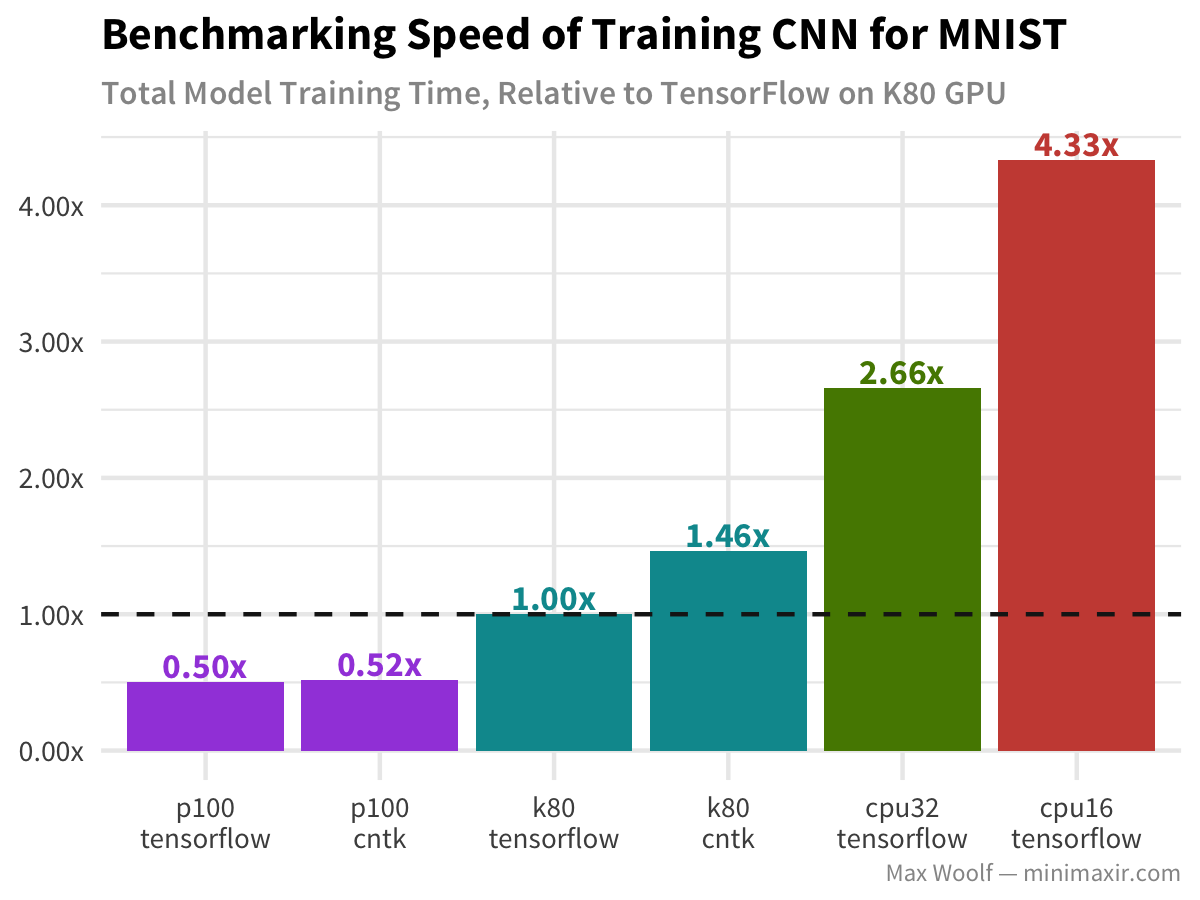
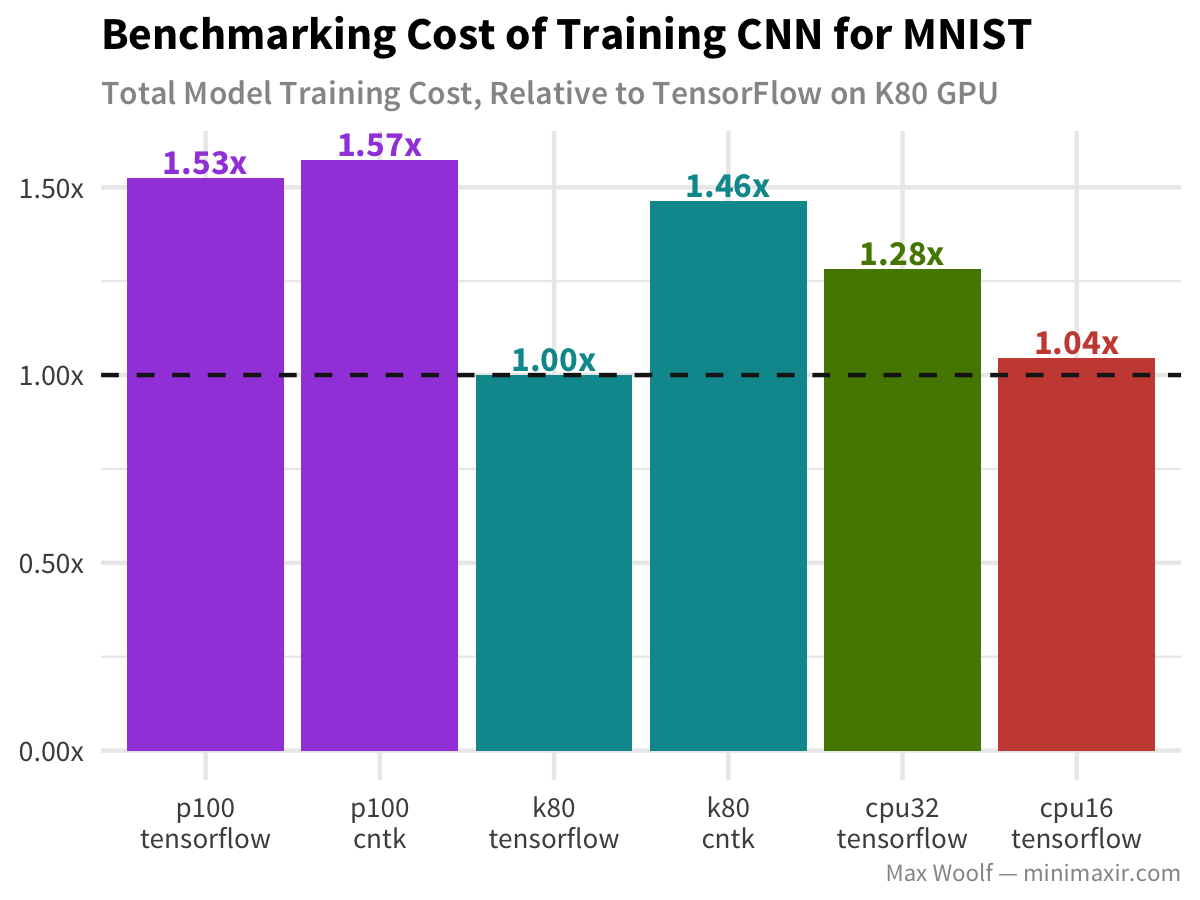
Indeed, the P100 is twice as fast and the K80, but due to the huge cost premium, it’s not cost effective for this simple task. However, CPUs do not perform well on this task either, so notably the base configuration is the best configuration.
Let’s go deeper with CNNs and look at the CIFAR-10 image classification dataset, and a model which utilizes a deep covnet + a multilayer perceptron and ideal for image classification (similar to the VGG-16 architecture).
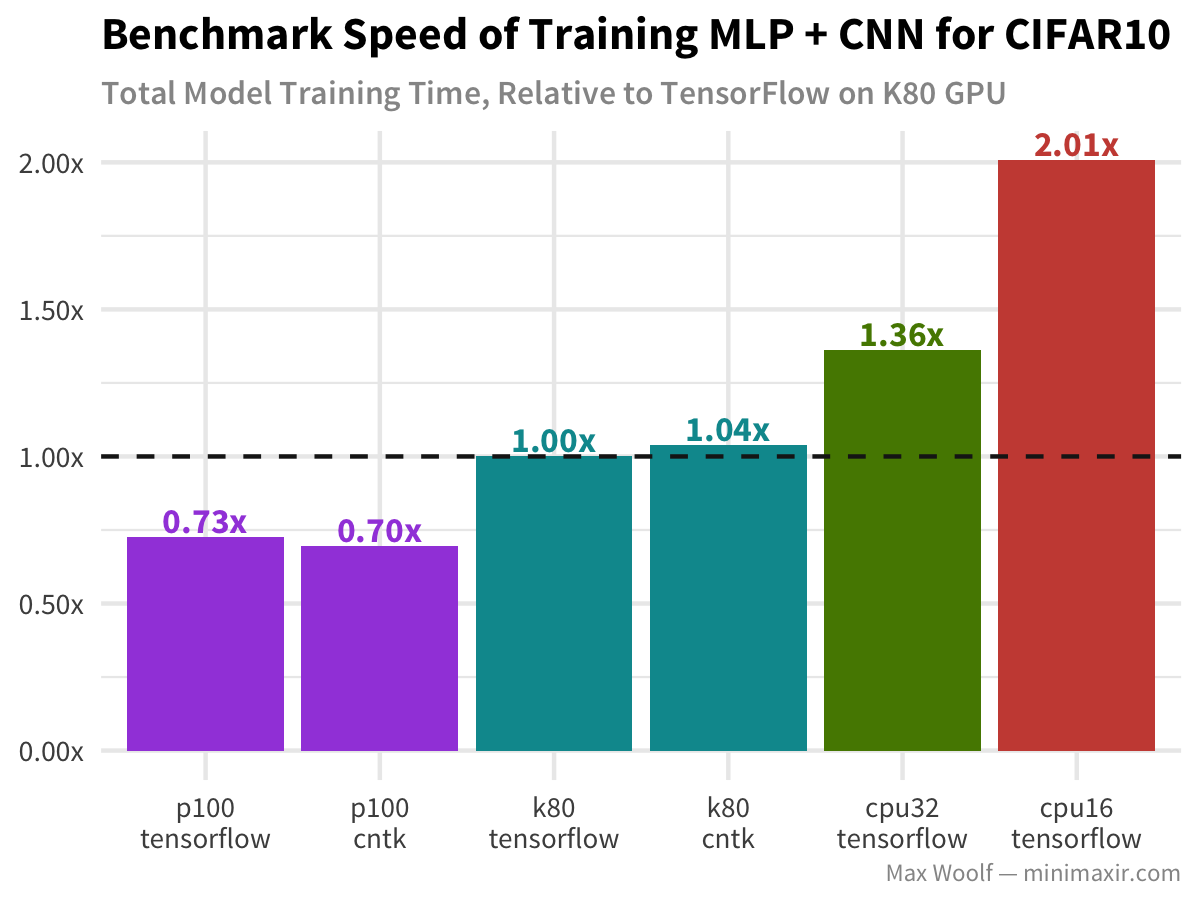
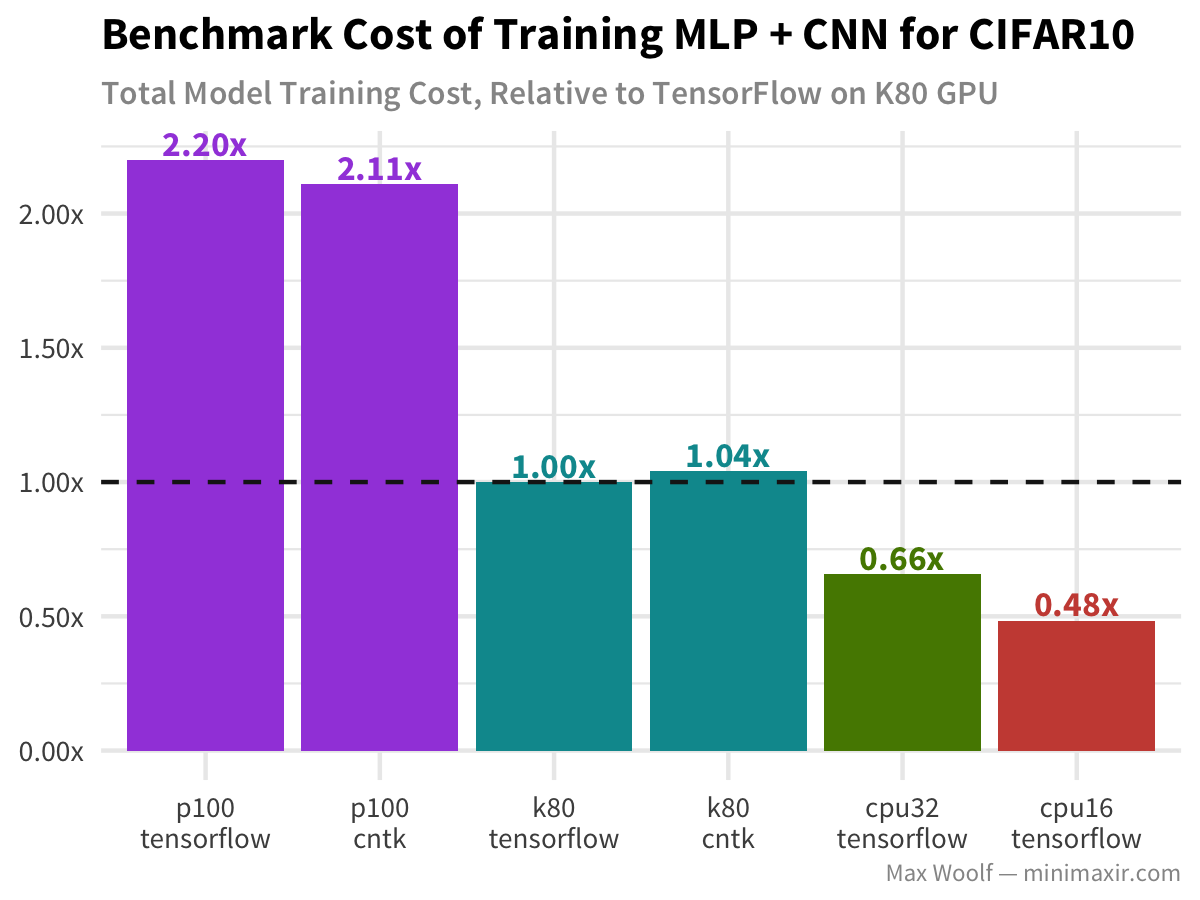
Similar results to that of a normal MLP. Nothing fancy.
The Bidirectional long-short-term memory (LSTM) architecture is great for working with text data like IMDb reviews. When I did my first benchmark article, I noticed that CNTK performed significantly better than TensorFlow, as commenters on Hacker News noted that TensorFlow uses an inefficient implementation of the LSTM on the GPU.
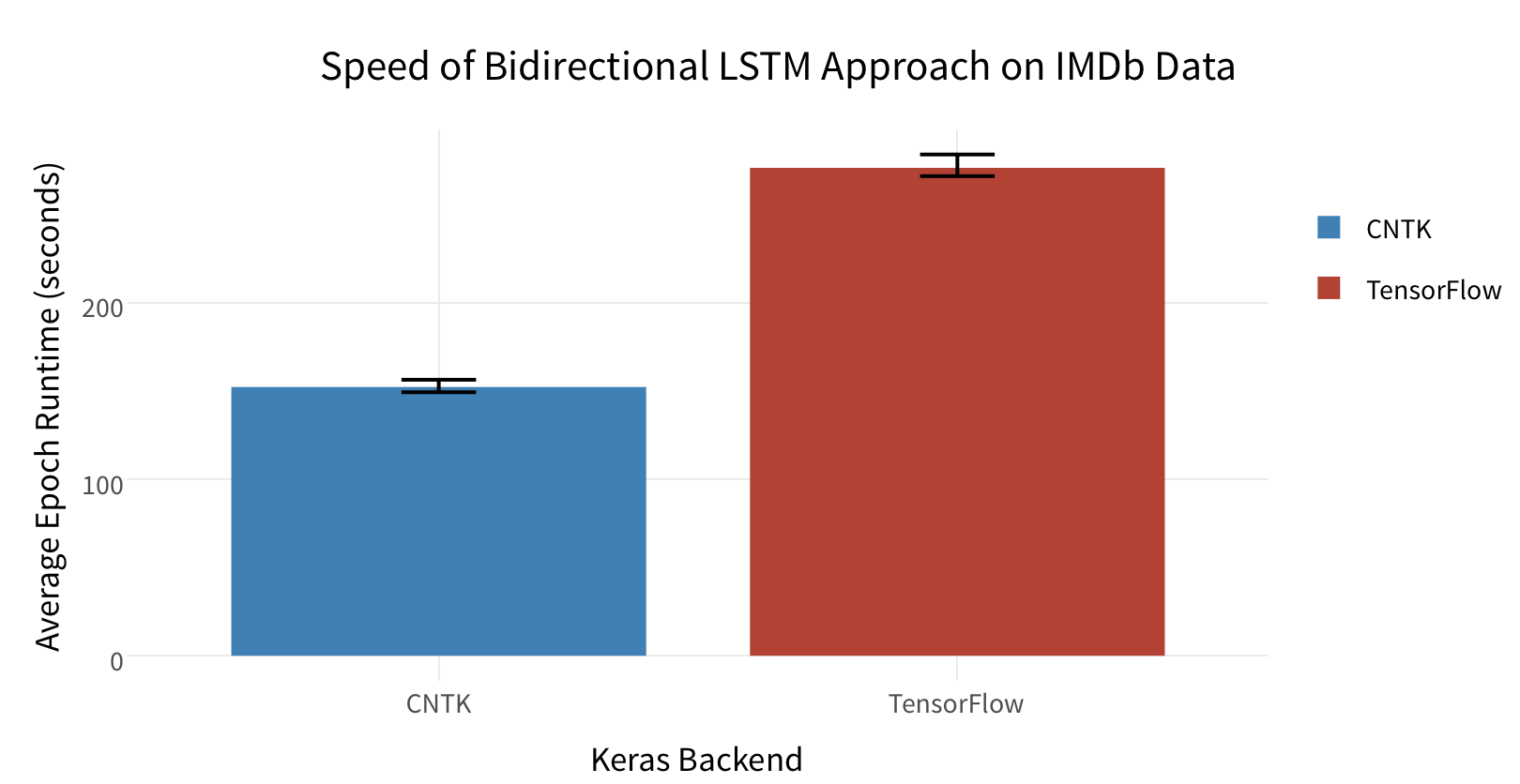
However, with Keras’s new CuDNNRNN layers which leverage cuDNN, this inefficiency may be fixed, so for the K80/P100 TensorFlow GPU configs, I use a CuDNNLSTM layer instead of a normal LSTM layer. So let’s take another look:
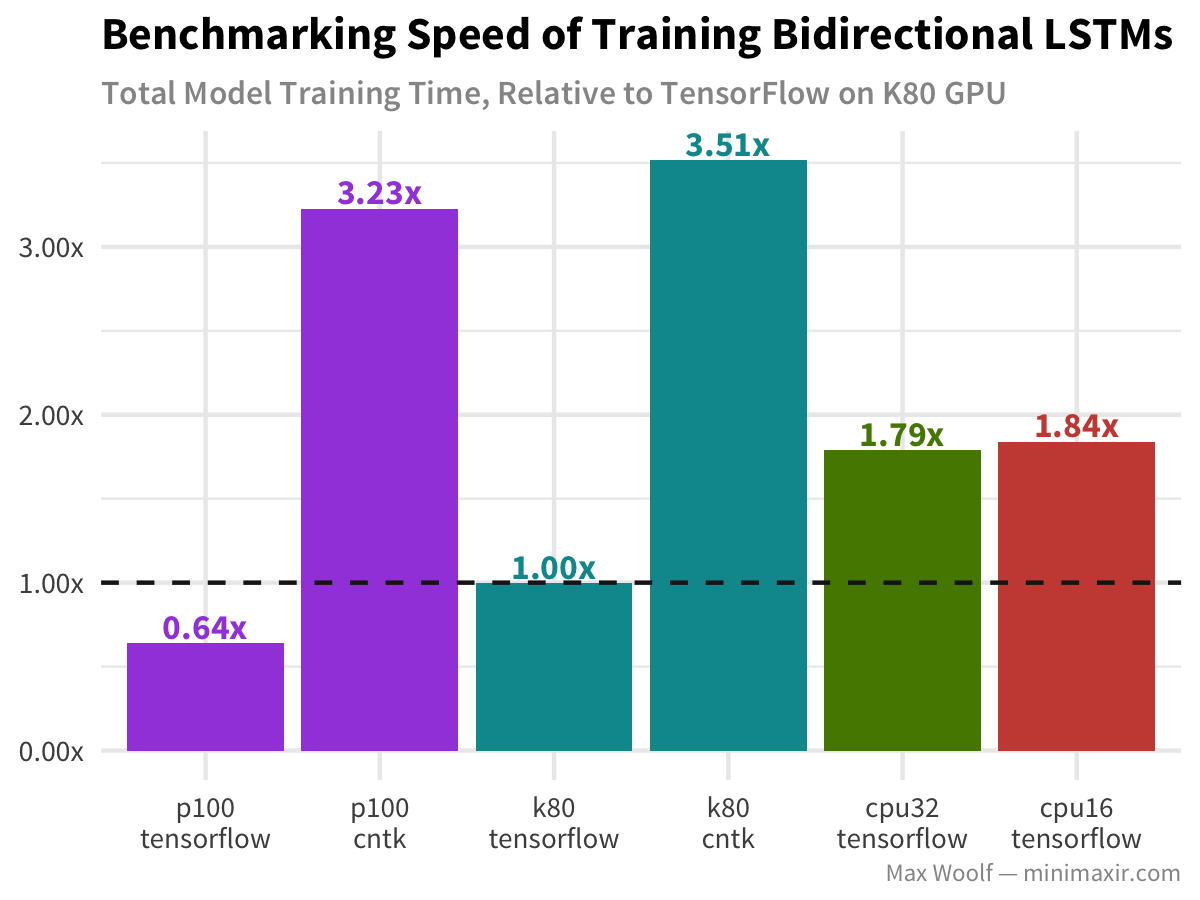
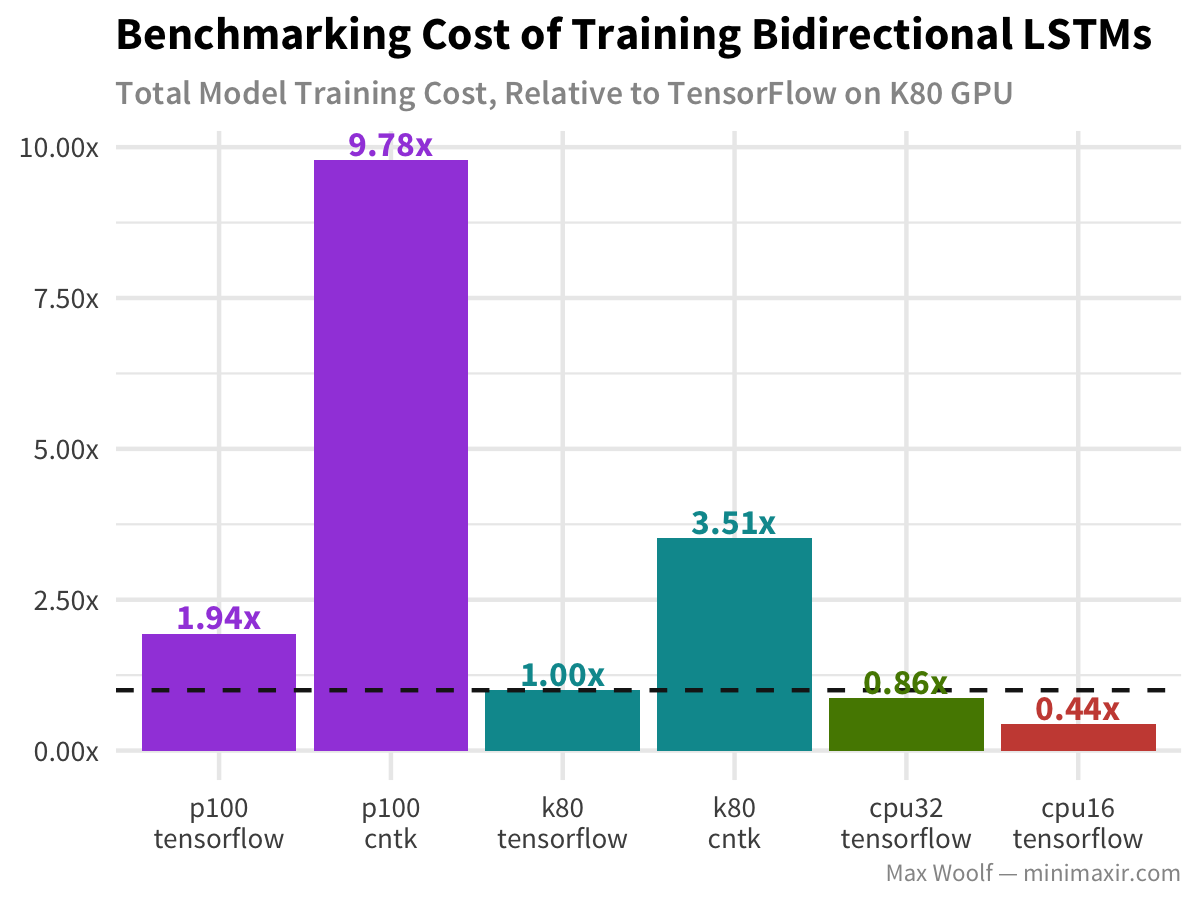
WOAH. TensorFlow is now more than three times as fast than CNTK! (And compared against my previous benchmark, TensorFlow on the K80 w/ the CuDNNLSTM is about 7x as fast as it once was!) Even the CPU-only versions of TensorFlow are faster than CNTK on the GPU now, which implies significant improvements in the ecosystem outside of the CuDNNLSTM layer itself. (And as a result, CPUs are still more cost efficient)
Lastly, LSTM text generation of Nietzsche’s writings follows similar patterns to the other architectures, but without the drastic hit to the GPU.
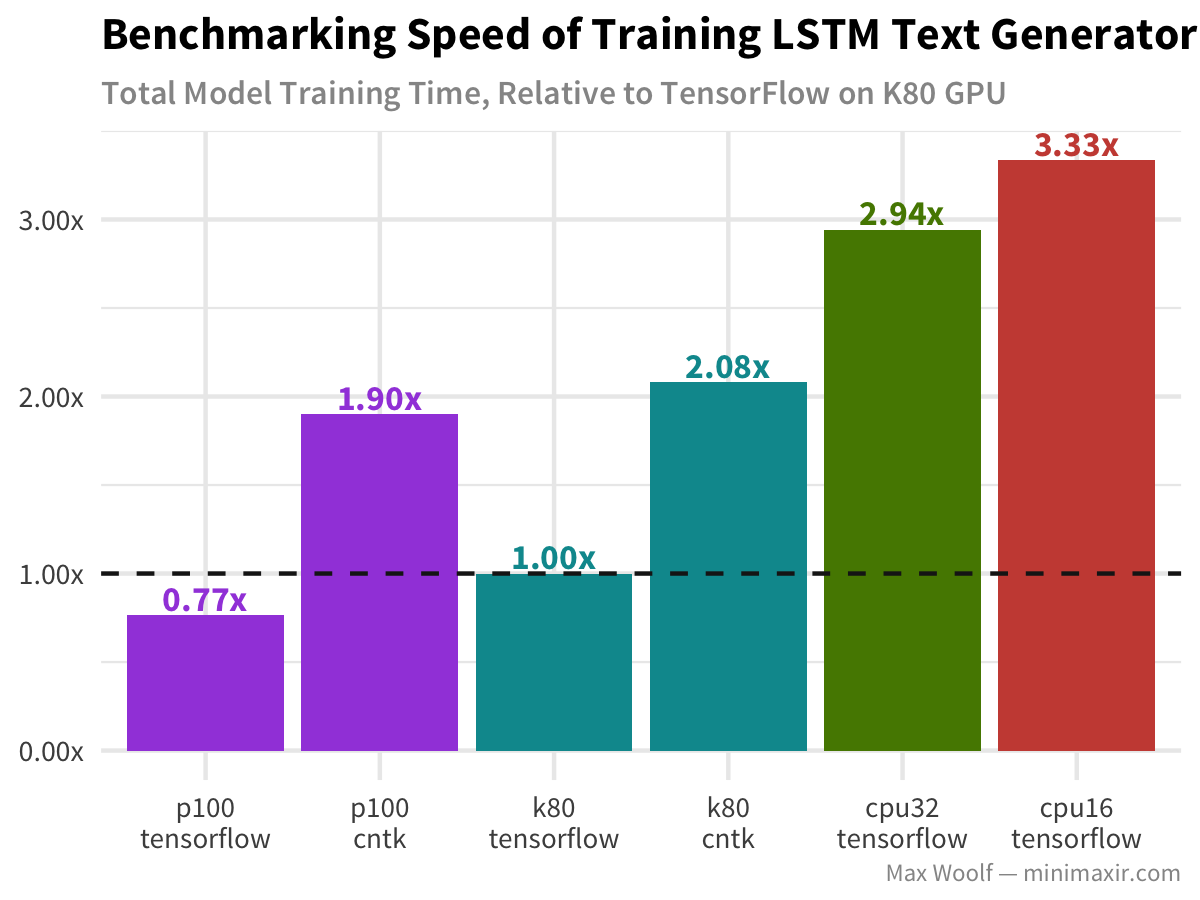
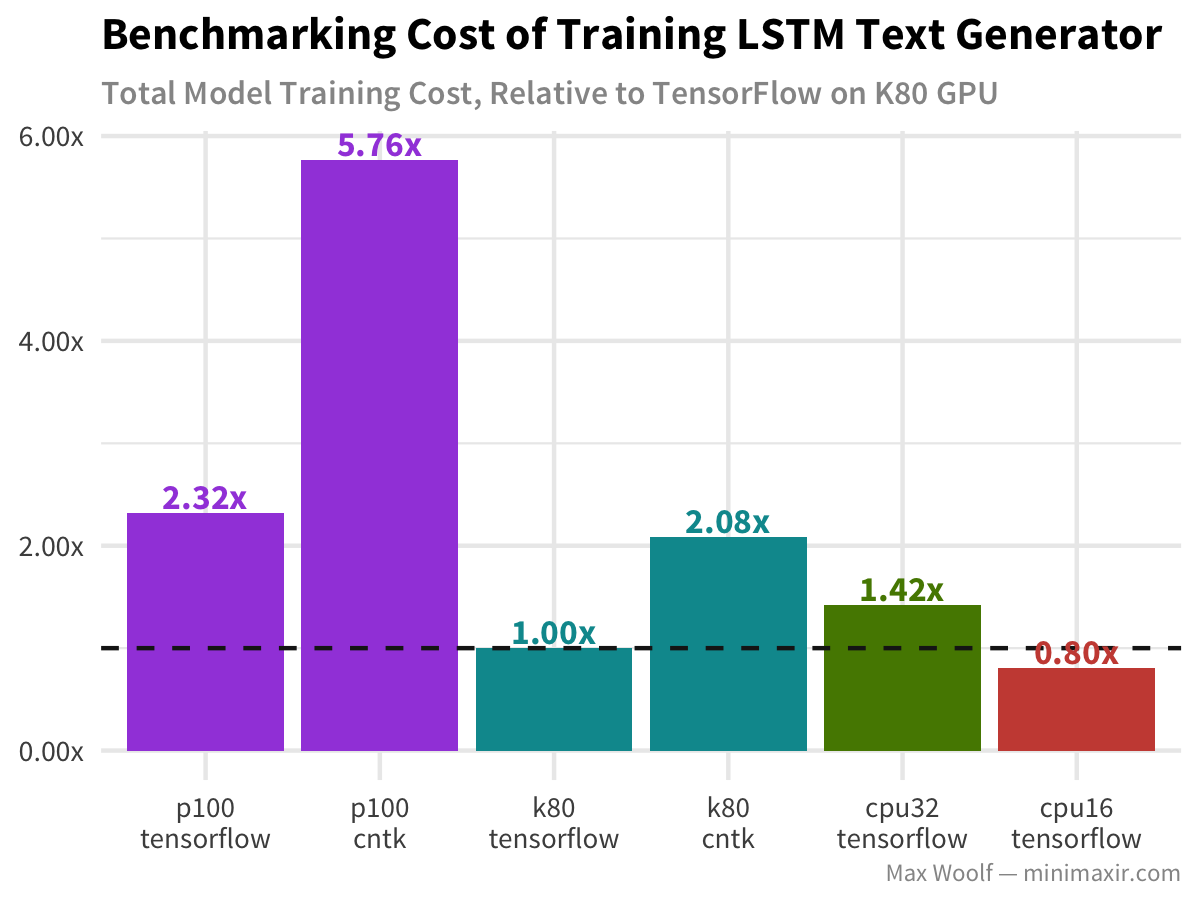
Conclusions
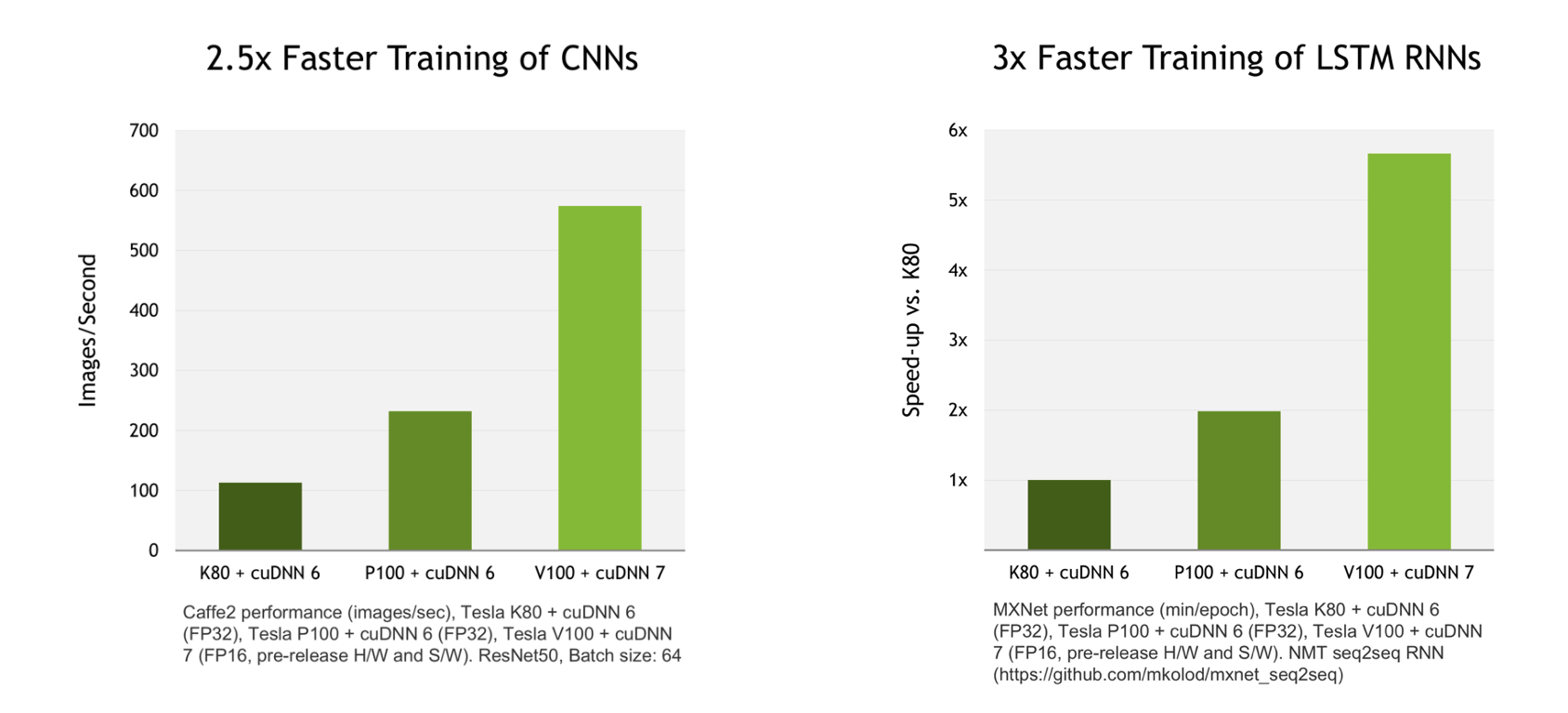
The biggest surprise of these new benchmarks is that there is no configuration where the P100 is the most cost-effective option, even though the P100 is indeed faster than the K80 in all tests. Although per the cuDNN website, there is apparently only a 2x speed increase between the performance of the K80 and P100 using cuDNN 6, which is mostly consistent with the results of my benchmarks:
I did not include a multi-GPU configuration in the benchmark data visualizations above using Keras’s new multi_gpu_model function because in my testing, the multi-GPU training was equal to or worse than a single GPU in all tests.
Taking these together, it’s possible that the overhead introduced by parallel, advanced architectures eliminates the benefits for “normal” deep learning workloads which do not fully saturate the GPU. Rarely do people talk about diminishing returns in GPU performance with deep learning.
In the future, I want to benchmark deep learning performance against more advanced deep learning use cases such as reinforcement learning and deep CNNs like Inception. But that doesn’t mean these benchmarks are not relevant; as stated during the benchmark setup, the GPUs were tested against typical deep learning use cases, and now we see the tradeoffs that result.
In all, with the price cuts on GPU instances, cost-performance is often on par with preemptable CPU instances, which is an advantage if you want to train models faster and not risk the instance being killed unexpectedly. And there is still a lot of competition in this space: Amazon offers a p2.xlarge Spot Instance with a K80 GPU for $0.15-$0.20 an hour, less than half of the corresponding Google Compute Engine K80 GPU instance, although with a few bidding caveats which I haven’t fully explored yet. Competition will drive GPU prices down even further, and training deep learning models will become even easier.
And as the cuDNN chart above shows, things will get very interesting once Volta-based GPUs like the V100 are generally available and the deep learning frameworks support cuDNN 7 by default.
UPDATE 12/17: As pointed out by dantiberian on Hacker News, Google Compute Engine now supports preemptible GPUs, which was apparently added after this post went live. Preemptable GPUs are exactly half the price of normal GPUs (for both K80s and P100s; $0.73/hr and $0.22/hr respectively), so they’re about double the cost efficiency (when factoring in the cost of the base preemptable instance), which would put them squarely ahead of CPUs in all cases. (and since the CPU instances used here were also preemptable, it’s apples-to-apples)
All scripts for running the benchmark are available in this GitHub repo. You can view the R/ggplot2 code used to process the logs and create the visualizations in this R Notebook.
