I’ve done some cool things with movie data using a dataset from OMDb API, which is sourced from IMDb and Rotten Tomatoes data. In my previous article on the dataset, I plotted the relationship between the domestic box office revenue of movies and their Rotten Tomatoes scores.
I want to take another look at domestic Box Office Revenues with aggregate statistics such as means/medians on categorical variables such as MPAA rating and release month. For this type of analysis in particular, I’ll also need to implement code in R for inflation adjustment.
However, I ran into a few unexpectedly silly issues.
Seeing Double
There are many similarities between data validation and the Quality Assurance process of product development, which is why this particular area appeals to me personally as a Software QA Engineer. Whenever a cool dataset is released publicly, I play around with it to look for any obvious flaws and to get a good all-around benchmark on the robustness of the data (this is a separate procedure from the traditional “data cleaning” phase necessary to begin quantification on some poorly-structured datasets).
Do the extreme values in the data make sense? Is the data encoded in a sane format? Are there any obvious gaps or logical contradictions in summary representations of the data, especially when compared to other canonical sources?
These concerns are also some of the reasons I’ve switched to the Jupyter Notebook as my primary data science IDE. After each block of code which transforms data, I can print the data frame inline to immediately see the results of the code execution, and refer back to them if anything odd happens in the future.
Let’s say I have a data frame of Movies using the latest data dump (3/26/16) from OMDb. This data set contains 1,160,273 movies, including both IMDb and Rotten Tomatoes data. After cleaning the data (not shown), I can use the R package dplyr by Hadley Wickham to sort the data frame by Box Office Revenue descending, and print the head (top) of the data.
print(df %>% select(imdbID, Title, Year, BoxOffice) %>% arrange(desc(BoxOffice)) %>% head(25), n = 25)

Those movies being the best makes sense. For Star Wars: The Force Awakens, I can compare it to the Box Office reported on the corresponding Rotten Tomatoes page, which in turn matches the domestic Box Office Revenue on Box Office Mojo.
But wait, The Dark Knight appears twice? How?!
There’s no way I would have missed something this obvious during the sanity-check for my previous article. In order to make sure that I’m not going insane, I double-checked the December 2015 data dump I used for that post, derived the top movies with the same methodology for the modern data dump, and the duplicate movies were not present. Weird.
There are 2 different IDs for The Dark Knight, and for some other movies near the top (Inside Out, “The Gravity”). Fortunately, duplicate data like this is easy to debug. The second data entry for The Dark Knight has a greater IMDb ID (1774602) which means it was likely added to the site later. Let’s look up the corresponding IMDb page:
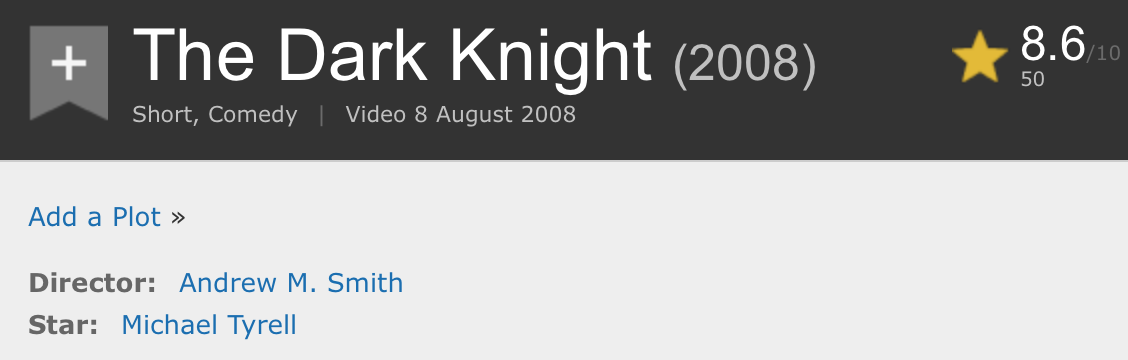
Huh. Apparently someone put a filler movie entry with the same name and release year as a blockbuster movie in hopes that people search for it by accident (and since it received 50 ratings and an average score of 8.6, this tactic was successful).
Using the Rotten Tomatoes IMDb Lookup API, we find that “The Dark Knight” page on Rotten Tomatoes…doesn’t exist.
We can run a safe deduplicate by removing entries with the same title (excluding the “The” if present) and release year.
df_dup <- df %>% select(Title, Year) %>% mutate(Title = gsub("The ", "", Title))
dup <- duplicated(df_dup) # find entry indices which are duplicates
rm(df_dup) # remove temp dataframe
df_dedup <- df %>% filter(!dup) # keep entries which are *not* dups
print(df_dedup %>% select(imdbID, Title, Year, BoxOffice) %>% arrange(desc(BoxOffice)) %>% head(25), n = 25)

There we go! The de-duped dataset has 1,114,431 movies, impliying that there were 45,842 of these duplicate entries.
I’m not sure whose fault it is that duplicate movies suddenly became present in the data dump: OMDb or Rotten Tomatoes. But it doesn’t matter: the wrong entries still need to be addressed, and it’s good to have a test case for the future too.
Inflation Station
A Stack Overflow answer from Ben Hanowell has a good R implementation and rationale for implementing inflation adjustment using the historical Consumer Price Index data from the Federal Reserve Bank of St. Louis.
Take the index for each year (averaging each month for simplicity) and create an adjustment factor to convert historical dollar amounts into present-day dollar amounts. Much better than plugging hundreds of thousands of values into an online calculator. Here’s the SO code made dplyr-friendly for this purpose, with the requisite sanity-checks.
inflation <- read_csv("http://research.stlouisfed.org/fred2/data/CPIAUCSL.csv") %>%
group_by(Year = as.integer(substr(DATE, 1, 4))) %>%
summarize(Avg_Value = mean(VALUE)) %>% # average across all months
mutate(Adjust = tail(Avg_Value, 1) / Avg_Value) # normalize by most-recent year
print(inflation %>% head())
print(inflation %>% tail())
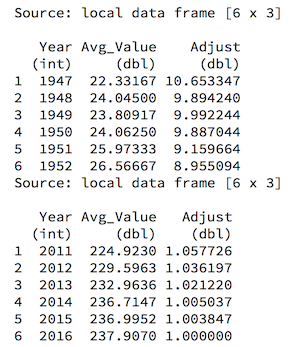
For example, to get the inflation-adjusted Box Office Revenue for a movie released in 1949 in 2016 dollars, we multiply the reported revenue by 10. That sounds about right (and matches closely enough to the output of the Bureau of Labor Statistics inflation calculator).
Now map each inflation adjustment factor to each movie by merging the two datasets (on the Year column), then multiply the Box Office revenue by the adjustment factor to get the inflation-adjusted revenue. Plus another sanity-check for good measure.
df_dedup_join <- df_dedup %>% inner_join(inflation) %>% mutate(AdjBoxOffice = BoxOffice * Adjust)
print(df_dedup_join %>% select(Title, Year, AdjBoxOffice) %>% arrange(desc(AdjBoxOffice)) %>% head(25), n=25)

Uh-oh.
I mean, The Lorax probably earned $1.2 billion in VHS sales for Earth Day education alone, but the TV special was never released in theaters. There was a CGI remake of The Lorax a few years ago which was reasonably popular. Could it be that someone at Rotten Tomatoes or Box Office Mojo confused the two media?
That is exactly what happened. On Rotten Tomatoes, The 1972 Lorax was encoded with similar box office revenue as the 2012 Lorax; then the inflation factor sextupled it. For this type of data fidelity issue, it’s considerably more obvious whose at fault.
Unfortunately, that’s not the end of problems with the dataset. I compared my results with Vox’s dataset on worldwide historical box office revenues. In the Top 200 Movies by inflation-adjusted revenue, there are noted historical movie omissions such as Jaws and Star Wars: A New Hope. It turns out Rotten Tomatoes does not have Box Office Revenue data for these movies at all.
That is a very serious problem which I’ll have to think about if it blocks any analysis on aggregate box office data completely. In the end, sanity-checking third party data is important because you never know how the data will surprise you, until it’s too late.
You can view the Top 200 movies by domestic box office revenue for each of the 12/15 source dataset, the 3/16 dataset, the 3/16 deduped dataset, and the 3/16 deduced inflation-adjusted data in this GitHub repository, along with the Jupyter notebook.
