OpenRouter is a service that provides access to most LLMs with a singular API, which has become exceedingly useful as of late given the rapid cadence of new LLM releases. Due to the company’s role as an intermediary between users and the LLM APIs, OpenRouter has robust, representative data on how users interact with LLMs and it publishes this data on the AI Model Rankings page: a welcome deviation from the labs themselves which generally keep this data secret for competitive reasons. Recently, I checked the OpenRouter rankings and noticed something peculiar.
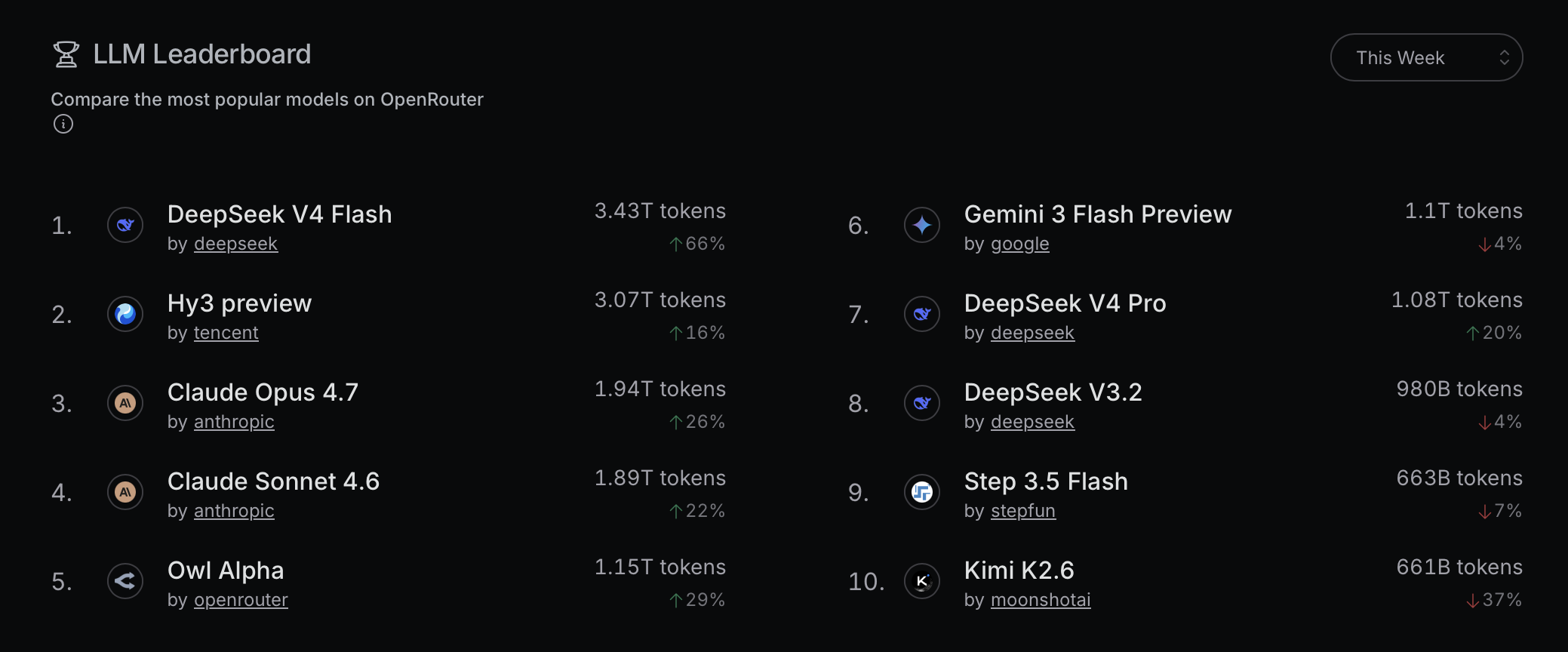
Retrieved May 25, 2026.
Two new models are now beating LLM darling Claude in terms of token usage and by more than 50%? I’ve heard of DeepSeek Flash V4: it’s an open-source release from DeepSeek that is not only fast/cheap, but also performs closer to the leading LLM models at a very low cost so it’s no surprise that it’s incredibly popular. But what the heck is Hy3 preview? I’ve never heard of Hy3 or anyone talking about it. Googling it returns an announcement from Chinese megacorp Tencent about Hy3’s open-source release: the model page itself on Hugging Face is sparse and includes oddly honest benchmark results that are not favorable for the model compared to other Chinese open-source models.
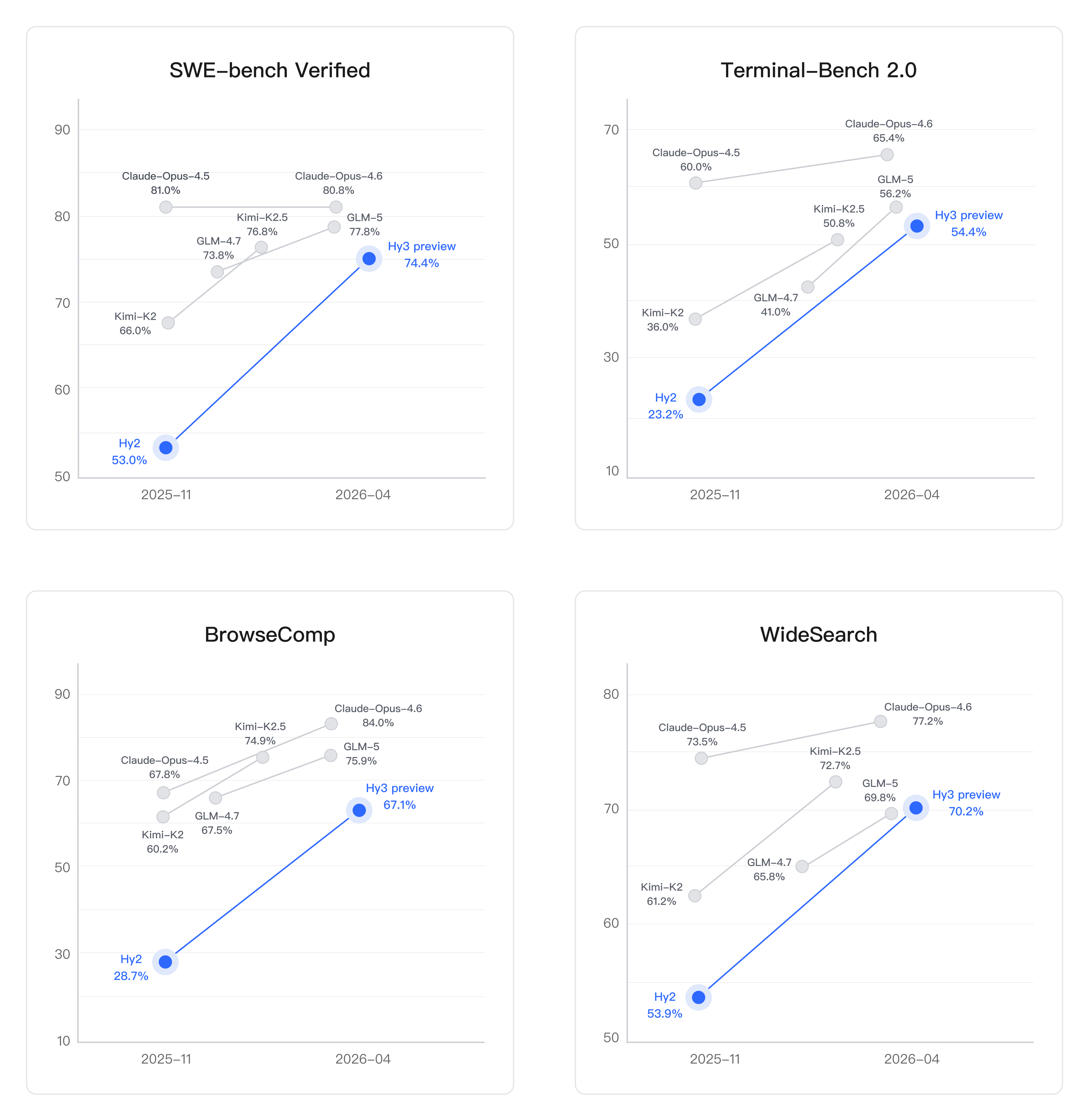
Coding-oriented benchmark results for Hy3 from Tencent’s Hugging Face repo.
A Hacker News search for Hy3 only returned a single submission that isn’t about Hy3, and Reddit discussion is more about the open-weights release. One Reddit thread also noted the rise of Hy3 but from May 6, when Hy3 was offered by OpenRouter for free; that free endpoint is no longer available, and therefore Hy3’s usage in the weekly rankings above is from paying users.
Hy3 preview is apparently popular in domains outside of agentic coding as well.
Retrieved May 25, 2026.
Did I miss something? After some nonscientific testing, the model quality is indeed on par with the other Chinese models indicated and not close to models such as Claude Opus 4.7 and GPT 5.5. It’s not a magic overlooked diamond-in-the-rough, so there has to be something else at play. Fortunately, OpenRouter has the data to narrow down possible explanations, but after checking the data I became more confused.
Hy3 preview is available from the OpenRouter API at a stated price of $0.066/1M tokens input which is indeed cheaper than the current top-ranked model DeepSeek V4 Flash with a stated price of $0.10/1M tokens input. Given the drastically rising cost of LLMs and coding agents, it makes sense that a cheaper model would prevail, but only if it offered similar quality and that doesn’t appear to be the case.
Here’s the chart of Hy3 preview model usage over time on OpenRouter from the model page:
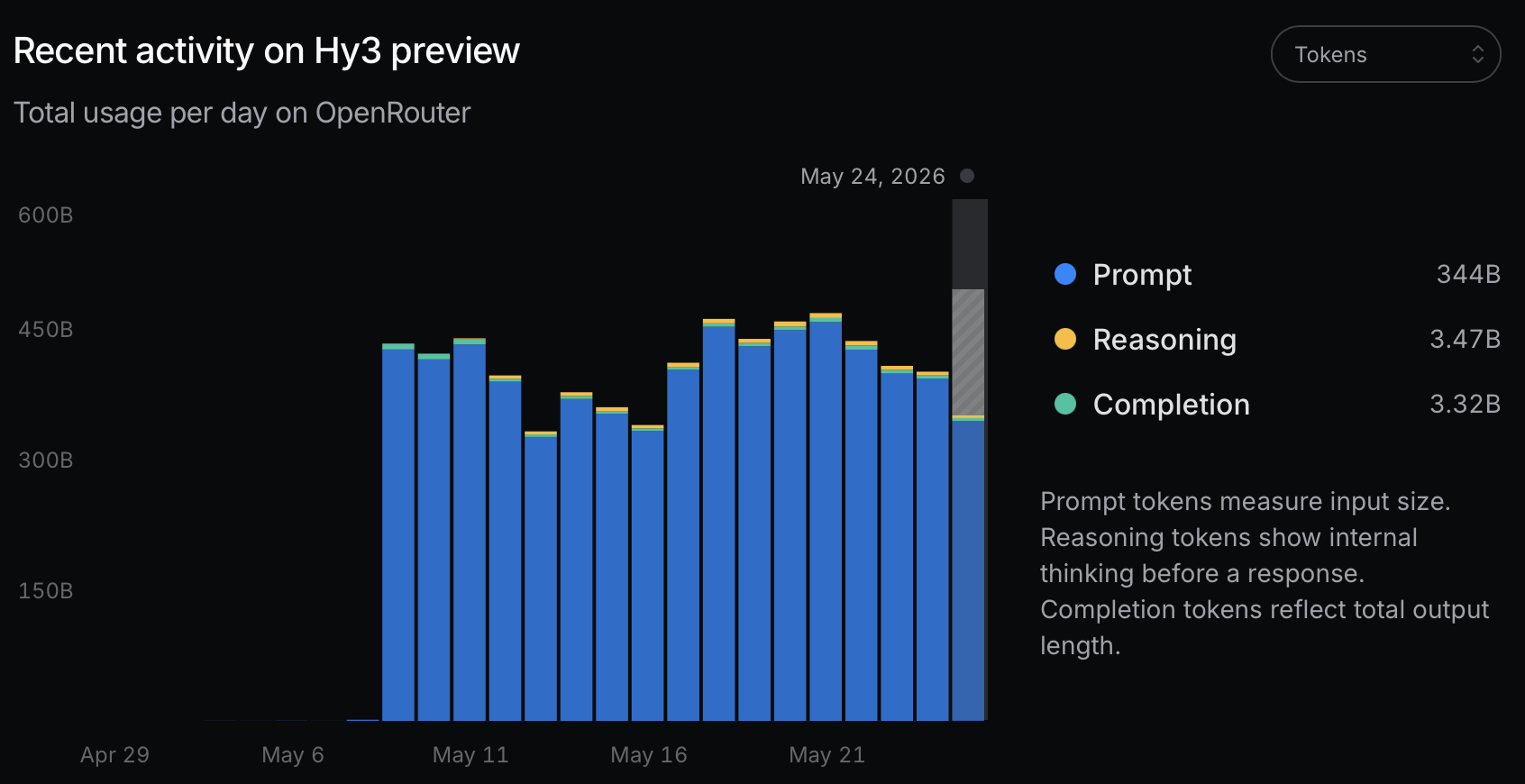
Hy3 preview has no usage data before May 8, which implies that is the time the model switched from the free SKU to the paid SKU. Usage is also steady over time since then with the initial rankings shown in this post being several weeks after launch, showing that the usage is at least organic (or very expensive to fake) and not a one-off outlier. Of note, if you do the math on the numbers presented here, the input-token-to-output-token breakdown on LLM API calls is now 98% input, 2% output in aggregate.
For the OpenRouter AI Model Rankings, there have historically been spikes by specific apps switching their default to a particular LLM, such as when Kilo Code offered Grok Code Fast 1 for free in September 2025, which rocketed it up in popularity. That does not appear to be the case here because apps only constitute a very small part of Hy3 preview’s activity.
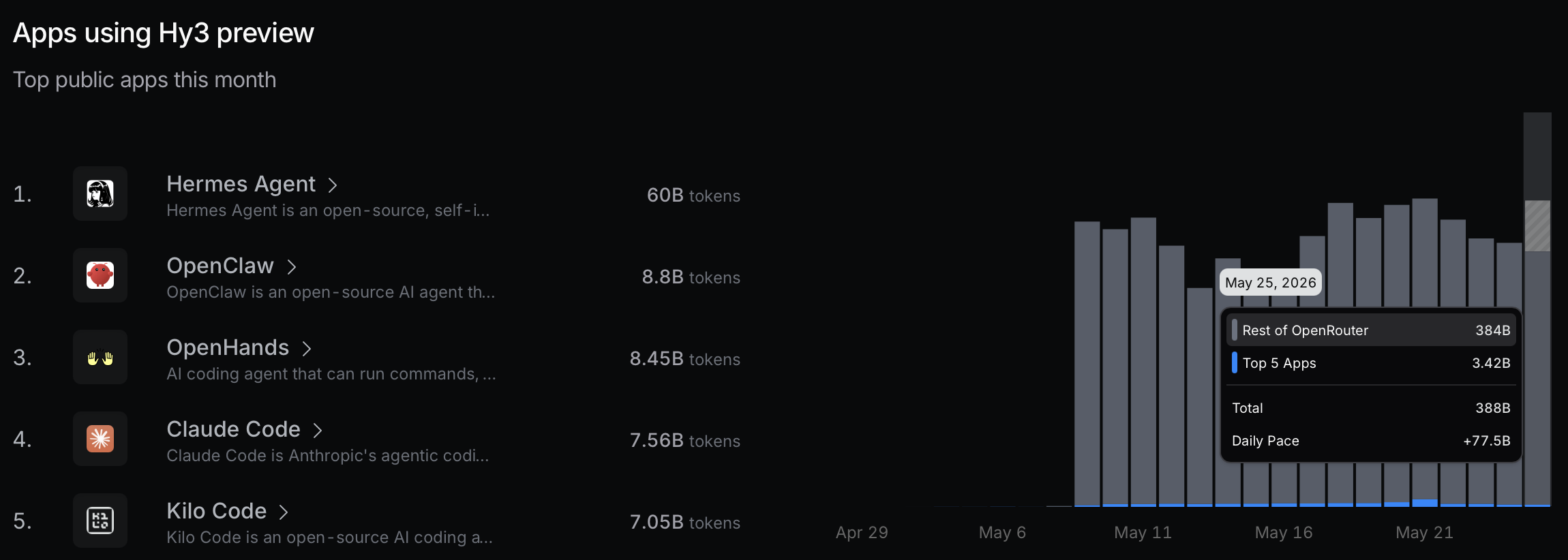
The top 5 apps accout for <1% of all activity to Hy3 preview.
OpenRouter’s value proposition is the ability to automatically route a given API request to different providers: for open-weight models such as DeepSeek V4 Flash, OpenRouter lists 13 providers, but Hy3 preview only has one provider despite its open weights1: the Singapore-based SiliconFlow. Their usage page on OpenRouter shows that SiliconFlow had relatively little usage…until Hy3.
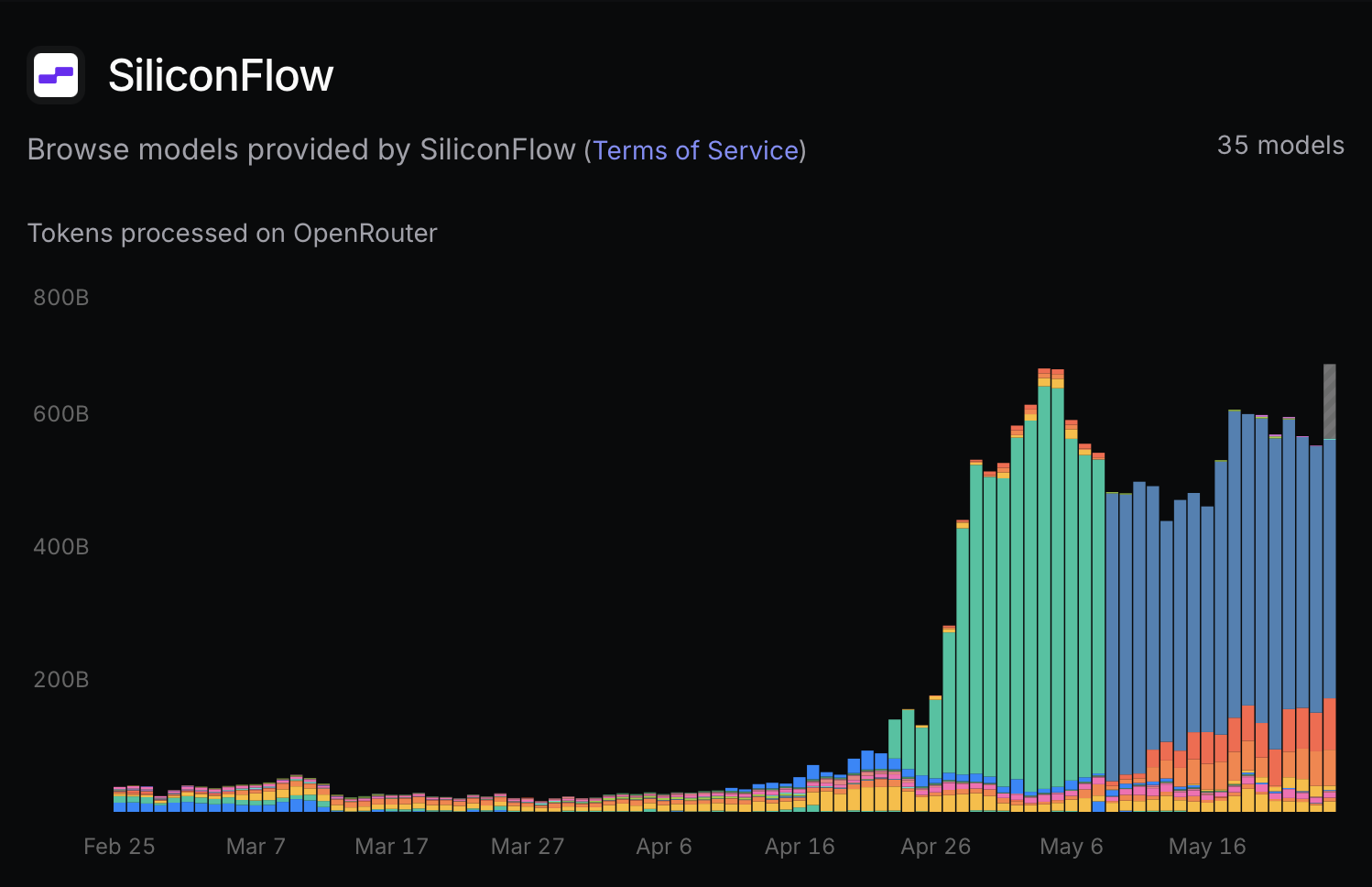
The green area corresponds to free Hy3 usage while the blue area corresponds to paid Hy3 usage: OpenRouter does not differentiate them on mouseover which I suspect is a bug.
Coincidentially that data visualization shows that usage didn’t drop drastically when Hy3 preview moved from free to paid, which in itself is interesting: if users were not getting value from the free model, they likely would have stopped using it once the costs hit their wallet.
What am I missing? Am I overthinking it and the answer is really because “it’s the cheapest” and it received sufficient loss leader traction from the free period?
…but is Hy3 preview actually the cheapest LLM backed by a major company on OpenRouter? While I was double-checking some assumptions, I found that OpenRouter has data that shows Hy3 preview is not the cheapest well-performing LLM available: it’s actually DeepSeek V4 Flash, but with interesting caveats.
LLM Economics in 2026
So here are a few more notes about how LLM APIs work that aren’t often discussed. LLM calls are still stateless, which means that after every turn (including user messages to the LLM asking questions), all of the tokens in the current conversation thread are reprocessed, meaning that in the case of agents, the count of input tokens increases cumulatively with each successive message and is one reason why starting new threads frequently as context fills up is encouraged for effective agent use.
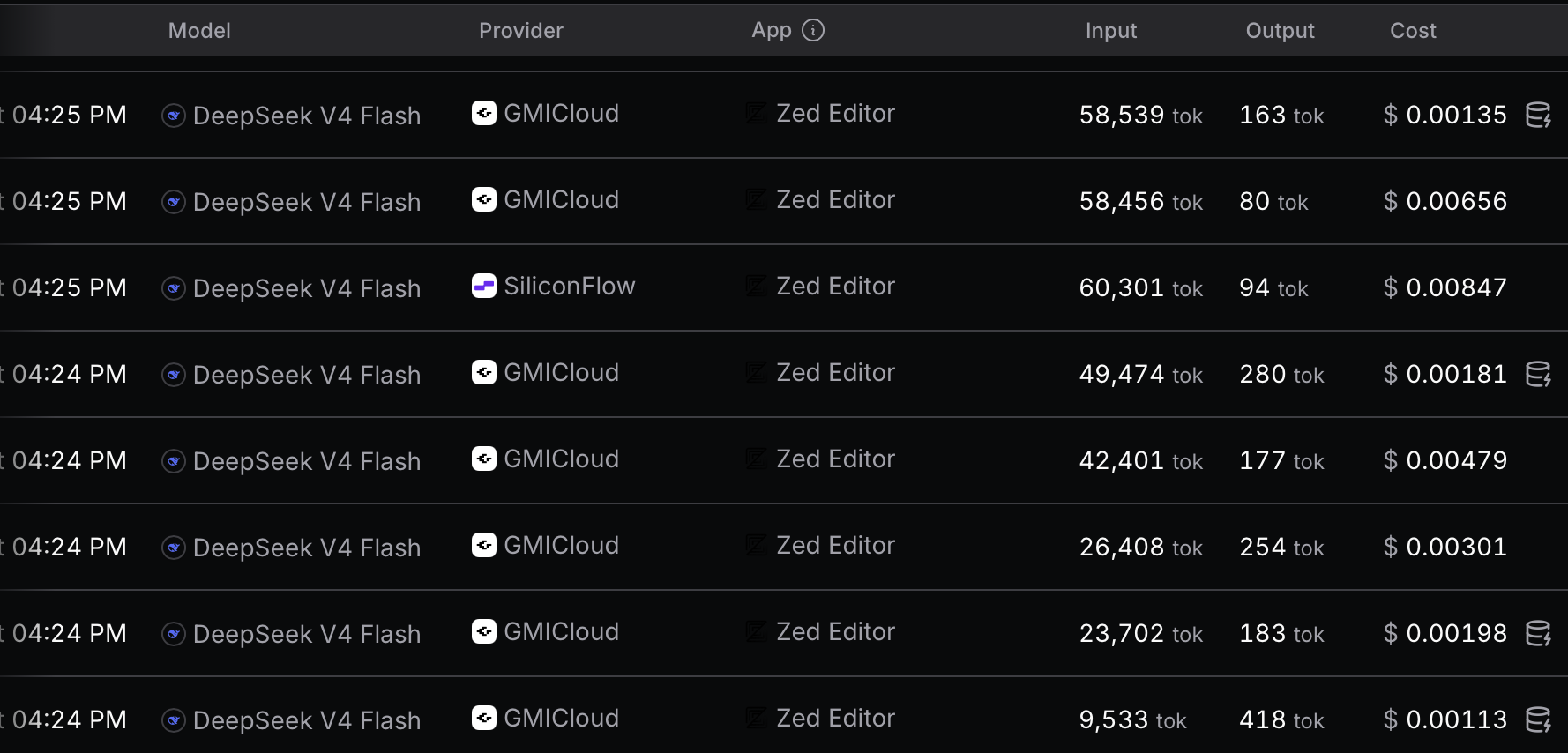
Reverse-chronological OpenRouter logs from one minute of Zed Agent use with DeepSeek V4 Flash selected.
But even before agentic workflows, large inputs such as full PDFs bloated context similarly. As a result, most LLM providers implemented prompt caching, which reuses input tokens processed earlier in the conversation: this is a win-win that saves time/compute for the LLM provider and the savings are passed to the customer. Most LLM providers cache inputs automatically, including when accessed through OpenRouter: the disk-lightning-bolt symbol next to the cost indicates tokens were cached and the cache may not always be hit, especially if OpenRouter switches providers mid-thread. The odd API provider out is the Anthropic (Claude) API which requires paying for a cache write first for some reason.
Typically, cache read costs are 10% of the input costs: this is the case for the latest models from OpenAI API, Anthropic API, and Google Gemini API. For the 13 providers that serve DeepSeek V4 Flash, cache read costs are between 20% and 50% of input cost, which makes sense as they may not have the same economies of scale. There’s one DeepSeek V4 Flash provider that’s an exception, though:
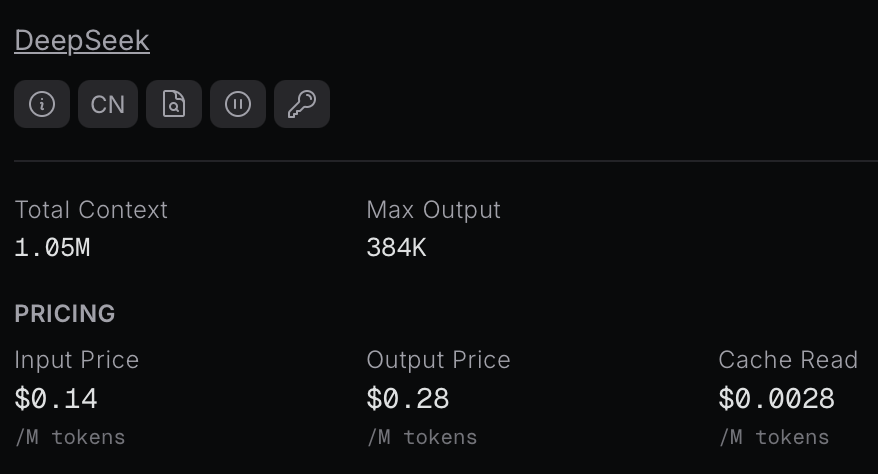
That’s a 2% cache read cost! (multiply by 2, move decimal left 2 places) How are DeepSeek’s cache read prices so low? DeepSeek has implemented a new approach to KV caching starting with V4 and as the model’s creator it is positioned to best leverage its own innovations, which as mentioned the benefits are passed to the customer. The DeepSeek V4 Pro variant model, when served by DeepSeek, has a cache read cost of 0.83%! (use a calculator for that one)
Remember how I showed that 98% of LLM API costs are now input tokens, which are aggressively cached? That means the “stated” prices of LLMs are now misleading, but unusually in a pro-customer way because the effective price will be much cheaper! To counter this ambiguity, OpenRouter now has a table for effective prices on the model page, which accounts for the cost savings from cache hits. Here’s the effective pricing for DeepSeek V4 Flash via OpenRouter by provider, which is different for each provider as they have different cache read costs and cache hit rates:
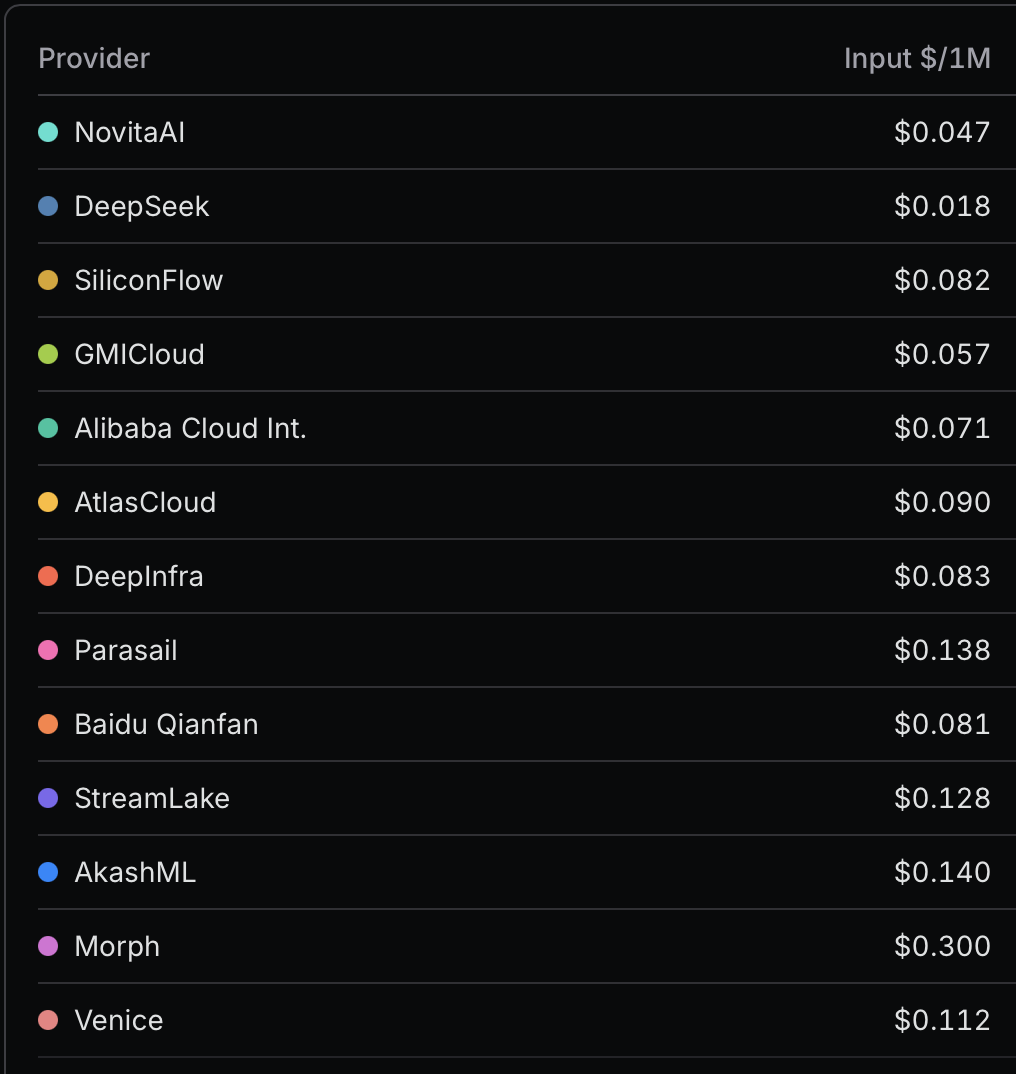
Retrieved May 25, 2026; these values update every hour.
The prices are all over the place, but notice the second row where DeepSeek itself is the provider, which is priced at a whopping $0.018/1M input tokens! That 2% cache read really pays off. Comparing apples to apples with Hy3 preview, the effective pricing for Hy3 preview as noted on its model page from SiliconFlow (a whopping 44% cache read cost) is $0.034/1M: nearly double DeepSeek V4 Flash from DeepSeek! Of course, this is only applicable if DeepSeek is explicitly used as the provider, which some downstream OpenRouter clients/agents may not support: the OpenRouter prices match the prices directly from DeepSeek, so using a direct DeepSeek API key will work the same.
There is also an elephant in the room: DeepSeek is a China-based company and some may not want—or may not legally be able—to give their payment processing information or LLM input data to a Chinese company who has set prompt training = true on their OpenRouter data policy information, which is a legitimate concern.
Yes, subscription-based LLM services such as Claude Code and Codex are still the best bang for your buck if you’re able to consistently exhaust the usage limits. But the super-cheap DeepSeek V4 Flash via the API doesn’t lock you into a subscription, and if you need a bit more agentic compute to finish a project, it’s cheaper than paying for extra usage from the subscription services.2 At the least, it’s a microeconomic check against additional pricing shenanigans that will likely continue through 2026 as competition in agentic AI heats up.
Overall, I still don’t understand the popularity of Hy3 preview on OpenRouter. Given the available data and analysis above, my guess is that a single large app not affiliated with Tencent is indeed using Hy3 as its data-processing backbone, and this app isn’t solely an agentic coding app. But one of the advantages of OpenRouter is that it’s low-lift to switch models and providers: it wouldn’t surprise me if DeepSeek V4 Flash gets a spike in a few weeks once people catch on to its pricing.
The license for Hy3 is very restrictive in a way that could potentially prevent providers from adopting the model. ↩︎
DeepSeek has also just announced its own coding agent platform with V4 Flash that claims to leverage their strong caching, however it’s at 50% input cost but at a significantly more expensive 20% cache read cost so its unclear if the economics are actually cheaper than just using an DeepSeek API key with another agent. ↩︎
