I am objectively terrible at writing attractive titles for my blog posts. Which is a problem, as nowadays it’s a commonly understood truth that a good headline can be the sole factor whether a blog post goes viral or gets completely ignored, especially in the data science/machine learning fields I typically write about.
So, why not use said data science/machine learning to create an optimized title for me?
Many know GPT-3 as a tool for robust text generation. But a newer, lesser discussed feature that OpenAI allows is finetuning GPT-3 on data you provide. If I provide GPT-3 with a large dataset of good titles, can I use that to tell me if one of my blog post titles are good? Let’s give it a try.
Getting The Good Blog Post Data from Hacker News
All code and tools used in this blog post are available open-source on GitHub.
The AI classifier I will create will be a binary classifier, which returns the probability that an input blog post title is good, and from that I can provide alternate blog post titles and see roughly which is best from those probabilities.
In order to finetune GPT-3 for this use case, I need to obtain a decently large amount of post titles with good and bad labels. For this experiment, I’ll use submission data from Hacker News.

Hacker News frontpage on August 14th, 2022.
Hacker News data is good for a few reasons: each submission has community validation by a large number of people, submission titles cover a wide variety of idiosyncratic styles, and most of all, it’s easy to get Hacker News submission data in bulk from BigQuery. For example, if I wanted to get all submissions between August 2020 and 2022 with atleast a score of 10 (the rough minimum to get on the front page and to filter out some spam), plus some light filters to remove things that are definitely not blog posts or articles (such as Show HNs and social media), I’d input a SQL query something like this:
SELECT
title,
score
FROM
`bigquery-public-data.hacker_news.full`
WHERE
type = "story"
AND score >= 10
AND url IS NOT NULL
AND timestamp BETWEEN "2020-08-01" AND "2022-08-01"
AND NOT REGEXP_CONTAINS(title, r"^Show HN")
AND NOT REGEXP_CONTAINS(url, r"(?:github|youtube|twitter)\.com")
This query returns roughly 90k submission titles total. For good titles, let’s say we consider posts with atleast 100 points as “good”, because it’s a nice number which is sometimes all that’s necessary in the world of data science. There are about 27k posts with more than 100 points in that subset, which is more than sufficient. The harder part is selecting the bad titles: since there are 63k titles fewer than 100 points, the data set as-is is unbalanced ~1:3 and will lead to flawed training results.
There are two solutions: either repeat the good posts to roughly equal the bad posts, or take a subset of bad posts to roughly equal the amount of good posts. We’ll do the latter since the sample size of good posts is large enough. Most people would download all 90k rows into something like Python to handle that sampling, but with SQL shenanigans you can do it entirely in BigQuery. (the annotated query is here and out of scope for this post, but may be interesting for data science hiring managers who want to annoy candidates in screening interviews)
This results in a ~55k title dataset: 27k good, 27k bad, perfectly balanced, as all datasets should be.
OpenAI’s finetuning API takes in a JSONL file where each line is a JSON object with two fields: prompt and completion (no, I am not sure why it can’t just be a CSV). In this case, the prompt is the title, prepended with Title: and with a -> suffix per their documentation suggestions to “align” it better to GPT-3, and the completion is the good/bad label, prepended with a space because GPT-3 is weird like that. An example of the final dataset:
{"prompt":"Title: How to slightly improve your life without trying ->","completion":" bad"}
{"prompt":"Title: SixtyFPS Becomes Slint ->","completion":" bad"}
{"prompt":"Title: Family estrangement: Why adults are cutting off their parents ->","completion":" bad"}
Their CLI cleans and can extract a validation set out of the inputs, which you should always do. Fortunately, BigQuery now offers JSONL export, so downloading the resulting dataset requires no further preprocessing. Once that’s done, the CLI allows you finetune, with special options for binary classification. (the exact CLI command I used is here)
Another understated aspect of GPT-3 is that there are weaker models that are faster and much cheaper than the default davinci model that is what people use when they generally use “GPT-3”. For text generation they tend to have less coherent outputs, but for a simplified use case like binary classification they are more than sufficient. I’ll use the babbage model, the second weakest.
The final results of the finetuning are about 63% accuracy on both the training and validation sets: not too much better than the default 50% accuracy of a balanced dataset for a binary classification problem, but given the problem difficulty it’s better than most approaches I’ve done for Hacker News data.
Once the finetuning is complete, you can query it, and ask it to return the probability of the returned token. Let’s pass in the title for my last blog post: Absurd AI-Generated Professional Food Photography with DALL-E 2
"top_logprobs": [
{
" bad": -0.34654787
}
Well, that’s not promising.
For some really weird reason, the API returns a log-probability instead of the actual probability that you’d want, so taking the exponent of that value results in a 70.7% probability it’s bad, which means there’s a 29.3% chance it’s good.
And that, is why I need a title optimizer.
Using InstructGPT To Create Alternate Titles
Since we now have a tool to determine the quality of blog post titles, how do we generate alternate titles that maintain the same meaning? I could think of tweaks to titles, but that takes effort and I am lazy. What if GPT-3 could create the candidate titles for me? It turns out, GPT-3 latest Instruct model can.
InstructGPT, released in January without much fanfare, is a version of davinci OpenAI finetuned themselves to better respond to instructions. It worked so well that it’s now the default GPT-3 model (noted as text-davinci-002 in the backend UI).
InstructGPT is surprisingly robust with the right prompt engineering. You can tell it to create detailed product descriptions of nonexistent video games, or write 4chan-style greentexts for any domain which maintain both the style and twist endings of the format.

via OpenAI’s GPT-3 Playground; all nonhighlighted text is the prompt.
After a bit of testing, the prompt I found worked best for this use case was:
Rewrite the following blog post title into six different titles but optimized for social media virality: <FILL IN TITLE>
-
It’s verbose, but that’s prompt engineering for you. The - at the end informs GPT-3 that the output should be a list with dash-bullets, which will make it easier to programmatically split the final output into distinct titles.
You can test it on the GPT-3 Playground; if the temperature parameter is 0, then the output will be deterministic.
Again putting in my last blog post Absurd AI-Generated Professional Food Photography with DALL-E 2 into InstructGPT:

via OpenAI’s GPT-3 Playground; all nonhighlighted text is the prompt.
All six of those titles are definitely an improvement, and all the text in green is what the programmatic API returns. Notably, despite the terseness of the input title and recency of DALL-E 2, InstructGPT is able to infer that the AI creates something and work from that, which is impressive.
Put The Title Optimizer Into Action!
A walkthrough of the code used to interact with the GPT-3 API and make the optimizer is available in this Jupyter Notebook, and the final demos are available in this Notebook.
Now that we have the two models ready, the workflow is simple:
- Choose the title of a technical blog post I want to optimize.
- Ping InstructGPT to get up to 6 alternate titles.
- Extract/clean up the generated titles (i.e. split and strip whitespace)
- For each of those alternate titles, ping the finetuned Hacker News GPT-3 for the probability that it is a
goodtitle. - In a pretty table, sort the titles by probability, descending.
Because the model can’t be widely distributed without review due to OpenAI rules, I decided to put the “UI” for this into a personal Jupyter Notebook.
Let’s experiment! We know the title of Absurd AI-Generated Professional Food Photography with DALL-E 2 is bad and the alternatives are interesting, but how good are the alternatives?

via GPT-3 Title Optimizer
Most of alternates are much better, with the predicted probabilities of being a good post going above 50%. (I probably should change the title retroactively but I will live with my SEO dishonor)
The original title for this post, in my boring no-one-will-ever-click-this style, was Creating a Blog Post Title Optimizer by Finetuning GPT-3 on Hacker News. Let’s plop it into the optimizer:

via GPT-3 Title Optimizer, temperature=0
So yes, the optimizer says the original title is very bad. But in this case, the variants are clickbaity and probably wouldn’t do very well on Hacker News.
Fortunately, you can rerun the generation and get more different variants if temperature is nonzero.

via GPT-3 Title Optimizer, temperature=0.7

via GPT-3 Title Optimizer, temperature=1.0
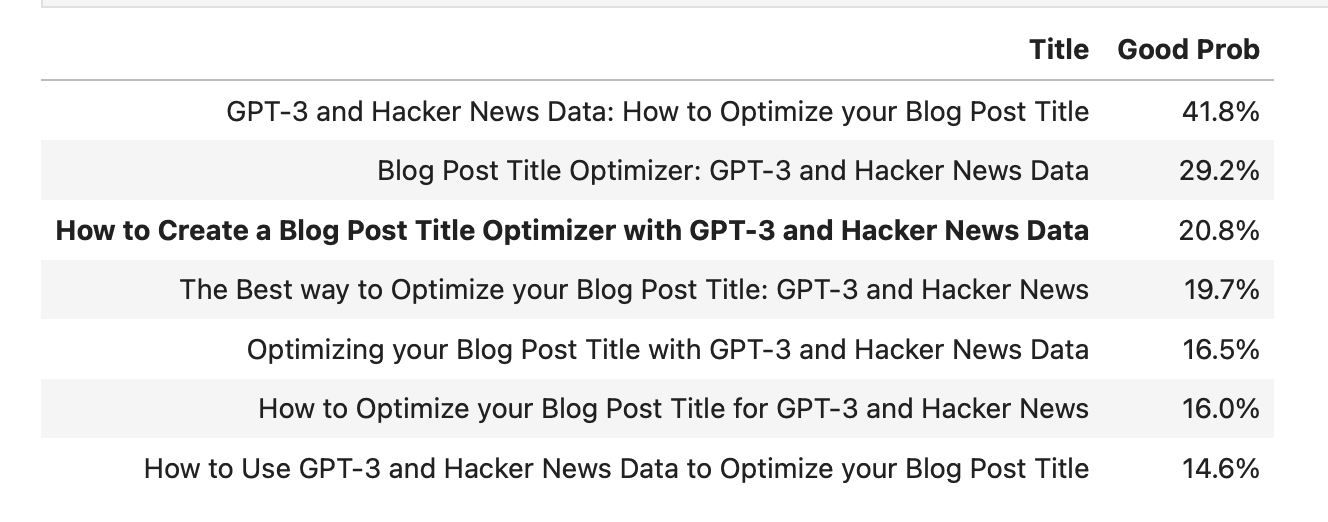
Definitely more variety. I like “How to Create a Blog Post Title Optimizer with GPT-3” as it maintains the same spirit even if it’s not the most optimal, although for disclosure reasons, I do want to include Hacker News somewhere in the title. Therefore, I can tweak the input to “How to Create a Blog Post Title Optimizer with GPT-3 and Hacker News Data” and feed it back to the optimizer and maybe get an interative improvement.

via GPT-3 Title Optimizer
The probability went down significantly with the change, and none of the variants are much better. Oh well.
Here’s the results of running the optimizer for some of my older blog posts:

The results for this post are indeed better; I’d definitely click the top one although it’s misleading.

The results for this post are much better, although this is one case where the original title is actually good.

The results for this post are a balance between better and not-technically-misleading clickbait.
Costwise, the entire pipeline is relatively inexpensive. Overall, it’s about $0.02 per run: too expensive to give unrestricted access to the internet, but very high return-on-investment if it successfully results in a catchy headline even if takes multiple tries. The most expensive part was the finetuning itself, which cost $2 but is a one-time cost.
Some might ask “why finetune GPT-3 when you can finetune an open-source large language model such as BERT like every NLP project since 2018?” In this case, GPT-3’s advantage is that it was trained in the entire internet. GPT-3 is a master of idiosyncrasy, which is a key when working with Hacker News data and in theory would give better results than the Wikipedia-trained BERT. The success of Hacker News posts also depends on a global context outside of the title itself, which is why finetuning an existing model trained on such context may be better than training an existing model solely on HN data.
Some are concerned about GPT-3 and AI tools such as these making writers redundant, but the results here prove otherwise: there will always have to be a human-in-the-loop.
UPDATE: When I submitted this post to Hacker News, it ended up getting over 200 points, defying the 20.8% probability!
