
The latest and greatest AI content generation trend is AI generated art. In January 2021, OpenAI demoed DALL-E, a GPT-3 variant which creates images instead of text. However, it can create images in response to a text prompt, allowing for some very fun output.

DALL-E demo, via OpenAI.
However the generated images are not always coherent, so OpenAI also demoed CLIP, which can be used to translate an image into text and therefore identify which generated images were actually avocado armchairs. CLIP was then open-sourced, although DALL-E was not.
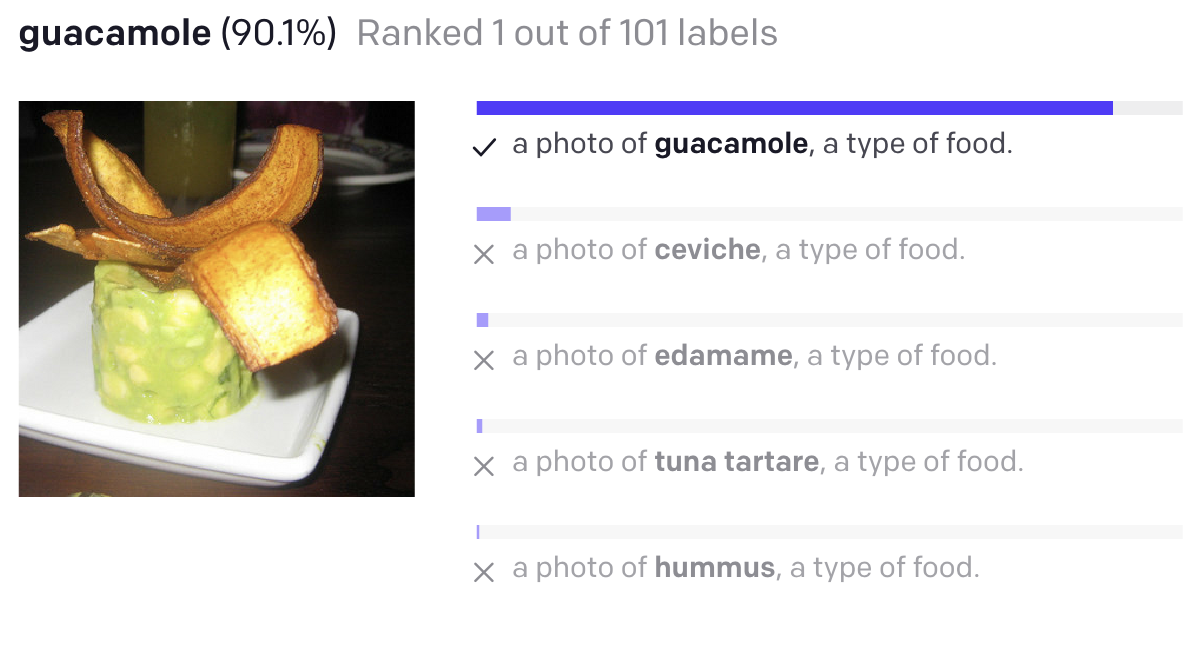
CLIP demo, via OpenAI.
Since CLIP is essentially an interface between representations of text and image data, clever hacking can allow anyone to create their own pseudo-DALL-E. The first implementation was Big Sleep by Ryan Murdock/@advadnoun, which combined CLIP with an image generating GAN named BigGAN. Then open source worked its magic: the GAN base was changed to VQGAN, a newer model architecture Patrick Esser and Robin Rombach and Björn Ommer which allows more coherent image generation. The core CLIP-guided training was improved and translated to a Colab Notebook by Katherine Crawson/@RiversHaveWings and others in a special Discord server. Twitter accounts like @images_ai and @ai_curio which leverage VQGAN + CLIP with user-submitted prompts have gone viral and received mainstream press. @ak92501 created a fork of that Notebook which has a user-friendly UI, to which I became aware of how far AI image generation has developed in a few months.
From that, I forked my own Colab Notebook, and streamlined the UI a bit to minimize the number of clicks needs to start generating and make it more mobile-friendly.
The VQGAN + CLIP technology is now in a good state such that it can be used for more serious experimentation. Some say art is better when there’s mystery, but my view is that knowing how AI art is made is the key to making even better AI art.
A Hello World to AI Generated Art
_All AI-generated image examples in this blog post are generated using this Colab Notebook, with the captions indicating the text prompt and other relevant deviations from the default inputs to reproduce the image._
Let’s jump right into it with something fantastical: how well can AI generate a cyberpunk forest?

cyberpunk forest
The TL;DR of how VQGAN + CLIP works is that VQGAN generates an image, CLIP scores the image according to how well it can detect the input prompt, and VQGAN uses that information to iteratively improve its image generation. Lj Miranda has a good detailed technical writeup.
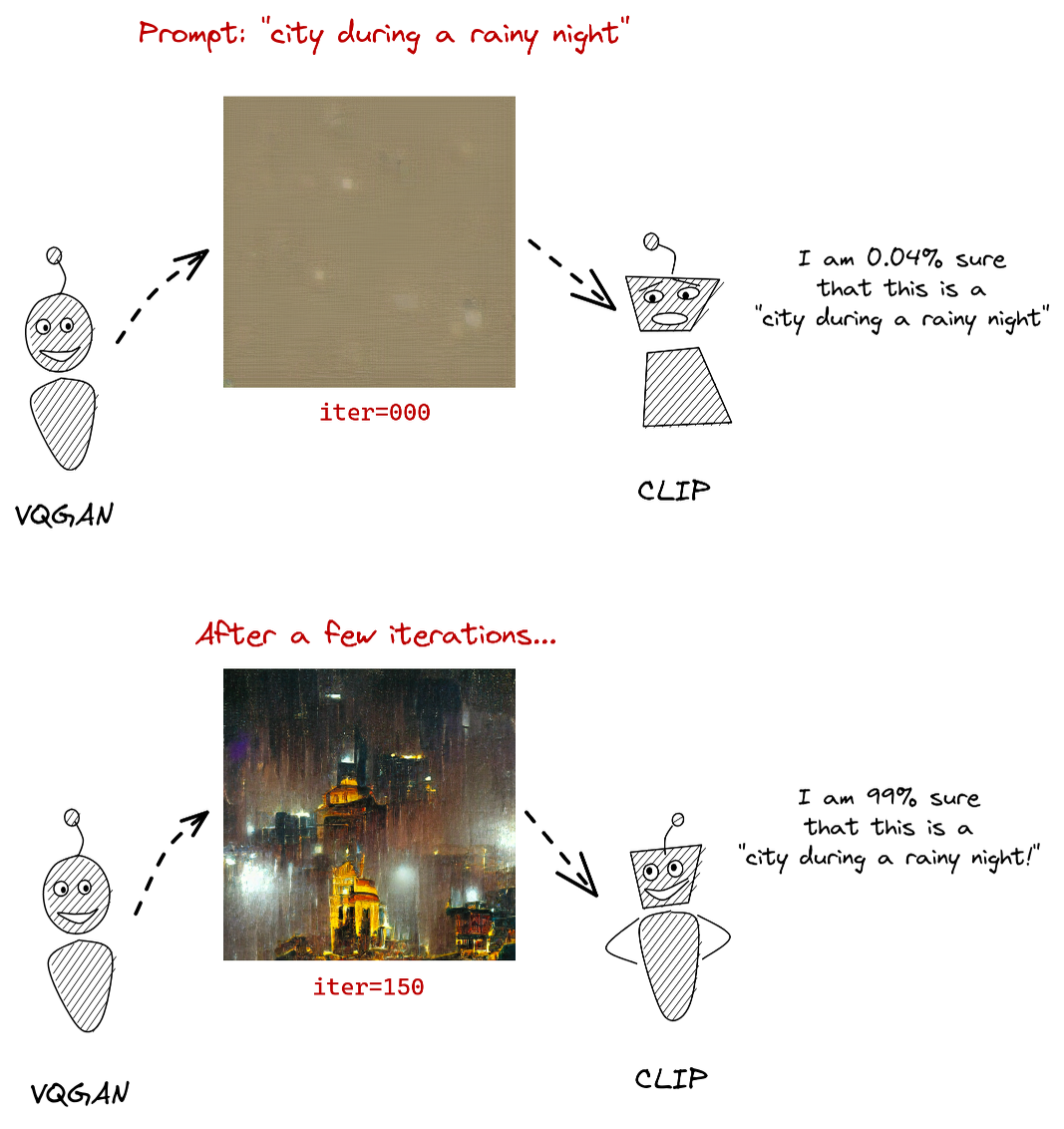
via Lj Miranda. Modified for theme friendliness.
Now let’s do the same prompt as before, but with an added author from a time well before the cyberpunk genre existed and see if the AI can follow their style. Let’s try Salvador Dali.

cyberpunk forest by Salvador Dali
It’s definitely a cyberpunk forest, and it’s definitely Dali’s style.
One trick the community found to improve generated image quality is to simply add phrases that tell the AI to make a good image, such as artstationHQ or trending on /r/art. Trying that here:

cyberpunk forest by Salvador Dali artstationHQ
In this case, it’s unclear if the artstationHQ part of the prompt gets higher priority than the Salvador Dali part. Another trick that VQGAN + CLIP can do is take multiple input text prompts, which can add more control. Additionally, you can assign weights to these different prompts. So if we did cyberpunk forest by Salvador Dali:3 | artstationHQ, the model will try three times as hard to ensure that the prompt follows a Dali painting than artstationHQ.

cyberpunk forest by Salvador Dali:3 | artstationHQ
Much better! Lastly, we can use negative weights for prompts such that the model targets the opposite of that prompt. Let’s do the opposite of green and white to see if the AI tries to remove those two colors from the palette and maybe make the final image more cyberpunky.

cyberpunk forest by Salvador Dali:3 | artstationHQ | green and white:-1
Now we’re getting to video game concept art quality generation. Indeed, VQGAN + CLIP rewards the use of clever input prompt engineering.
Initial Images and Style Transfer
Normally with VQGAN + CLIP, the generation starts from a blank slate. However, you can optionally provide an image to start from instead. This provides both a good base for generation and speeds it up since it doesn’t have to learn from empty noise. I usually recommend a lower learning rate as a result.
So let’s try an initial image of myself, naturally.

No, I am not an AI Generated person. Hopefully.
Let’s try another artist, such as Junji Ito who has a very distinctive horror style of art.

a black and white portrait by Junji Ito — initial image above, learning rate = 0.1
One of the earliest promising use cases of AI Image Generation was neural style transfer, where an AI could take the “style” of one image and transpose it to another. Can it follow the style of a specific painting, such as Starry Night by Vincent Van Gogh?

Starry Night by Vincent Van Gogh — initial image above, learning rate = 0.1
Well, it got the colors and style, but the AI appears to have taken the “Van Gogh” part literally and gave me a nice beard.
Of course, with the power of AI, you can do both prompts at the same time for maximum chaos.

Starry Night by Vincent Van Gogh | a black and white portrait by Junji Ito — initial image above, learning rate = 0.1
Icons and Generating Images With A Specific Shape
While I was first experimenting with VQGAN + CLIP, I saw an interesting tweet by AI researcher Mark Riedl:
Intrigued, I adapted some icon generation code I had handy from another project and created icon-image, a Python tool to programmatically generate an icon using Font Awesome icons and paste it onto a noisy background.
The default icon image used in the Colab Notebook
This icon can be used as an initial image, as above. Adjusting the text prompt to accomidate the icon can result in very cool images, such as a black and white evil robot by Junji Ito.

a black and white evil robot by Junji Ito — initial image above, learning rate = 0.1
The background and icon noise is the key, as AI can shape it much better than solid colors. Omitting the noise results in a more boring image that doesn’t reflect the prompt as well, although it has its own style.

a black and white evil robot by Junji Ito — initial image above except 1.0 icon opacity and 0.0 background noice opacity, learning rate = 0.1
Another fun prompt addition is rendered in unreal engine (with an optional high quality), which instructs the AI to create a three-dimensional image and works especially well with icons.

smiling rusted robot rendered in unreal engine high quality — icon initial image, learning rate = 0.1
icon-image can also generate brand images, such as the Twitter logo, which can be good for comedy, especially if you tweak the logo/background colors as well. What if we turn the Twitter logo into Mordor, which is an fair metaphor?

Mordor — fab fa-twitter icon, icon initial image, black icon background, red icon, learning rate = 0.1
So that didn’t turn out well as the Twitter logo got overpowered by the prompt (you can see outlines of the logo’s bottom). However, there’s a trick to force the AI to respect the logo: set the icon as the initial image and the target image, and apply a high weight to the prompt (the weight can be lowered iteratively to preserve the logo better).

Mordor:3 — fab fa-twitter icon, icon initial image, icon target image, black icon background, red icon, learning rate = 0.1
More Fun Examples
Here’s a few more good demos of what VQGAN + CLIP can do using the ideas and tricks above:

Microsoft Excel by Junji Ito — 500 steps

a portrait of Mark Zuckerberg:2 | a portrait of a bottle of Sweet Baby Ray's barbecue sauce — 500 steps

Never gonna give you up, Never gonna let you down — 500 steps

a portrait of cyberpunk Elon Musk:2 | a human:-1 — 500 steps

hamburger of the Old Gods:5 — fas fa-hamburger icon, icon initial image, icon target image, black icon background, white icon, learning rate = 0.1, 500 steps

reality is an illusion:8 — fas fa-eye icon, icon initial image, icon target image, black icon background, white icon, learning rate = 0.1
@kingdomakrillic released an album with many more examples of prompt augmentations and their results.
Making Money Off of VQGAN + CLIP
Can these AI generated images be commercialized as software-as-a-service? It’s unclear. In contrast to StyleGAN2 images (where the license is explicitly noncommercial), all aspects of the VQGAN + CLIP pipeline are MIT Licensed which does support commericalization. However, the ImageNet 16384 VQGAN used in this Colab Notebook and many other VQGAN+CLIP Notebooks was trained on ImageNet, which has famously complicated licensing, and whether finetuning the VQGAN counts as sufficiently detached from an IP perspective hasn’t been legally tested to my knowledge. There are other VQGANs available such as ones trained on the Open Images Dataset or COCO, both of which have commercial-friendly CC-BY-4.0 licenses, although in my testing they had substantially lower image generation quality.
Granted, the biggest blocker to making money off of VQGAN + CLIP in a scalable manner is generation speed; unlike most commercial AI models which use inference and can therefore be optimized to drastically increase performance, VQGAN + CLIP requires training, which is much slower and can’t allow content generation in real time like GPT-3. Even with expensive GPUs and generating at small images sizes, training takes a couple minutes at minimum, which correlates with a higher cost-per-image and annoyed users. It’s still cheaper per image than what OpenAI charges for their GPT-3 API, though, and many startups have built on that successfuly.
Of course, if you just want make NFTs from manual usage of VQGAN + CLIP, go ahead.
The Next Steps for AI Image Generation
CLIP itself is just the first practical iteration of translating text-to-images, and I suspect this won’t be the last implementation of such a model (OpenAI may pull a GPT-3 and not open-source the inevitable CLIP-2 since now there’s a proven monetizeable use case).
However, the AI Art Generation industry is developing at a record pace, especially on the image-generating part of the equation. Just the day before this article was posted, Katherine Crawson released a Colab Notebook for CLIP with Guided Diffusion, which generates more realistic images (albeit less fantastical), and Tom White released a pixel art generating Notebook which doesn’t use a VQGAN variant.
The possibilities with just VQGAN + CLIP alone are endless.
