On May 29th, OpenAI released a paper on GPT-3, their next iteration of Transformers-based text generation neural networks. Most notably, the new model has 175 billion parameters compared to the 1.5 billion of previous GPT-2 iteration: a 117x increase in model size! Because GPT-3 is so large, it can’t be run on conventional computers, and it only became publicly available as a part of the OpenAI API, which entered an invite-only beta soon after the paper was released and will be released for-profit sometime later.
The API allows you to programmatically provide GPT-3 with a prompt, and return the resulting AI-generated text. For example, you could invoke the API with:
curl https://api.openai.com/v1/engines/davinci/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <SECRET_KEY>" \
-d '{"prompt": "This is a test", "max_tokens": 5}'
And get this back from the API, where the text is the generated text following up from the prompt:
{
"id": "cmpl-<ID>",
"object": "text_completion",
"created": 1586839808,
"model": "davinci:2020-05-03",
"choices": [
{
"text": " of reading speed. You",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
]
}
As someone who has spent a very large amount of time working with GPT-2 while developing tools such as gpt-2-simple and aitextgen, which allow for optimized text generation using GPT-2, I was eager to test for myself if the quality of text generated from GPT-3 was really that much better. Thanks to OpenAI, I got invited to the beta, and with permission, I released a GitHub repository with a Python script to query the API, along with many examples of text prompts and their outputs. A fun use case for GPT-3 is absurdism, such as prompting the model about unicorns speaking English, with the model prompt bolded:
I also fed my own tweets through GPT-3 and curated the output, resulting in data science one-liners that are wholly original:
my new AI can tell if you are a serial killer just by looking at your LinkedIn
— Max Woolf (@minimaxir) July 12, 2020
Data scientists don't need to be good at math, they just need to be good at lying to people.
— Max Woolf (@minimaxir) July 9, 2020
sometimes I make a folder and name it "data" and I get very excited.
— Max Woolf (@minimaxir) July 8, 2020
There hadn’t been too much GPT-3 hype after the initial announcement, outside of a few blogs from Gwern and Kevin Lacker. Until a viral tweet by Sharif Shameem showed what GPT-3 can really do:
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lk
Later, he made a followup tweet generating React code with GPT-3:
I just built a *functioning* React app by describing what I wanted to GPT-3.
— Sharif Shameem (@sharifshameem) July 17, 2020
I'm still in awe. pic.twitter.com/UUKSYz2NJO
That demo got the attention of venture capitalists. And when a cool-looking magical thing gets the attention of venture capitalists, discourse tends to spiral out of control. Now, there are many tweets about GPT-3, and what it can do from others who have gained access to the API.
Hype aside, let’s look at the pragmatic realities of the model. GPT-3 is indeed a large step forward for AI text-generation, but there are very many caveats with the popular demos and use cases that must be addressed.
An Overview of GPT-3
GPT-3 itself, like most neural network models, is a black box where it’s impossible to see why it makes its decisions, so let’s think about GPT-3 in terms of inputs and outputs.
Actually, why not let GPT-3 tell its own story? Hey GPT-3, how do you work?
Close, but not quite!
In layman’s terms, text generating models such as GPT-3 generate text by taking supplied chunks of text from a prompt and predicting the next chunk of text, with an optional temperature parameter to allow the model to make suboptimal predictions and therefore be more “creative”. Then the model makes another prediction from the previous chunks including the new chunk, and repeats until it hits a specified length or a token that tells the model to stop generating. It’s not very philosophical, or evidence of some sort of anthropomorphic consciousness.
GPT-3 has two notable improvements from GPT-2 aside from its size: it allows generation of text twice the length of GPT-2 (about 10 paragraphs of English text total), and the prompts to the model better steer the generation of the text toward the desired domain (due to few-shot learning). For example, if you prompt the model with an example of React code, and then tell it to generate more React code, you’ll get much better results than if you gave it the simple prompt.
Therefore, there are two high-level use cases for GPT-2: the creative use case for fun text generation at high temperature, as GPT-2 once was, and the functional use case, for specific NLP-based use cases such as webpage mockups, with a temperature of 0.0.
GPT-3 was trained on a massive amount of text from all over the internet as of October 2019 (e.g. it does not know about COVID-19), and therefore it has likely seen every type of text possible, from code, to movie scripts, to tweets. A common misconception among viewers of GPT-3 demos is that the model is trained on a new dataset; that’s not currently the case, it’s just that good at extrapolation. As an example, despite the Star Wars: Episode III - Revenge of the Sith prompt containing text from a single scene, the 0.7 temperature generation imputes characters and lines of dialogue from much further into the movie. (The largest GPT-2 model could do that, but nowhere near as robust)
The real metagame with GPT-3 is engineering and optimizing complex prompts which can reliably coerce outputs into what you want. And with that brings a whole host of complexity and concerns.
GPT-3 Caveats
Despite everything above, I don’t believe that GPT-3 is a new paradigm or an advanced technology indistinguishable from magic. GPT-3 and the OpenAI API showcases on social media don’t show potential pitfalls with the model and the API.
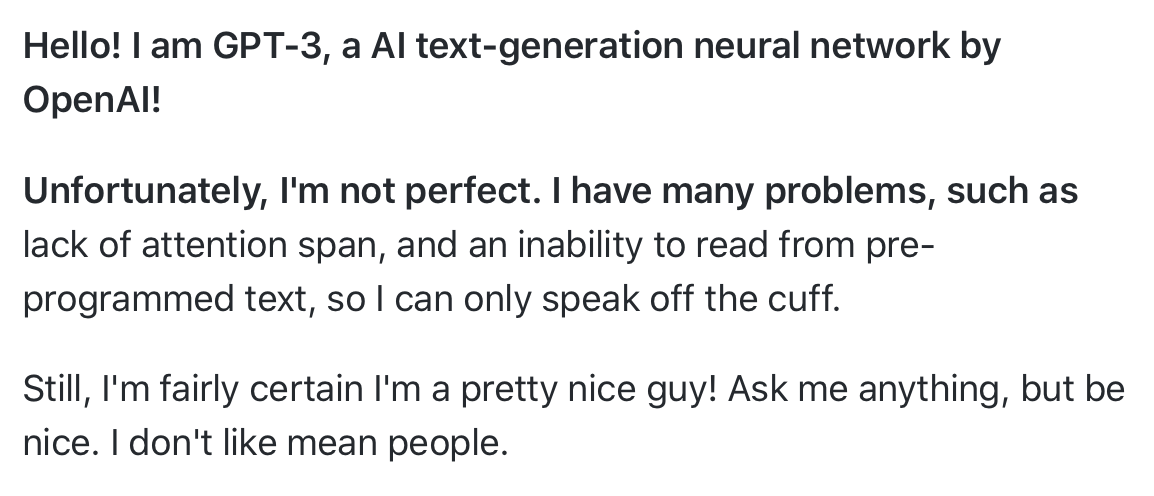
Hey GPT-3, what problems do you have?
Sorry GPT-3, but I am a mean person.
Model Latency
If you’ve seen the demo videos, the model is slow, and it can take awhile for output to show up, and in the meantime the user is unsure if the model is broken or not. (There is a feature to allow streaming the model outputs as they are generated, which helps in creative cases but not in functional cases).
I don’t blame OpenAI for the slowness. A 175 billion parameter model is a model that’s wayyy too big to fit on a GPU for deployment. No one knows how GPT-3 is actually deployed on OpenAI’s servers, and how much it can scale.
But the fact remains; if the model is too slow on the user end, it results in a bad user experience and might drive people away from GPT-3 and just do things themselves (e.g. Apple’s Siri for iOS, where requests can take forever if there is a weak internet connection and you just give up and do it yourself).
Selection Bias Toward Good Examples
The demos for GPT-3 are creative and human-like, but like all text generation demos, they unintentionally imply that all AI-generated output will be that good. Unfortunately, that’s not the case in reality; AI-generated text has a tendency to fall into an uncanny valley, and good examples in showcases are often cherry-picked.
That said, from my experiments, GPT-3 is far better in terms of the average quality of generated text than other text-generation models, although it still does depend on the generation domain. When I was curating my generated tweets, I estimated 30-40% of the tweets were usable comedically, a massive improvement over the 5-10% usability from my GPT-2 tweet generation.
However, a 30-40% success rate implies a 60-70% failure rate, which is patently unsuitable for a production application. If it takes seconds to generate a React component and it takes on average 3 tries to get something usable, it might be more pragmatic to just create the component the hard, boring way. Compare again to Apple’s Siri, which can get very frustrating when it performs the wrong action.
Everyone Has The Same Model
The core GPT-3 model from the OpenAI API is the 175B parameter davinci model. The GPT-3 demos on social media often hide the prompt, allowing for some mystique. However, because everyone has the same model and you can’t build your own GPT-3 model, there’s no competitive advantage. GPT-3 seed prompts can be reverse-engineered, which may become a rude awakening for entrepreneurs and the venture capitalists who fund them.
Corporate machine learning models are often distinguished from those from other companies in the same field through their training on private, proprietary data and bespoke model optimization for a given use case. However, OpenAI CTO Greg Brockman hinted that the API will be adding a finetuning feature later in July, which could help solve this problem.
Racist and Sexist Outputs
The Web UI for the OpenAI API has a noteworthy warning:
Please use your judgement and discretion before posting API outputs on social media. You are interacting with the raw model, which means we do not filter out biased or negative responses. With great power comes great responsibility.
This is a reference to the FAQ for the API:
Mitigating negative effects such as harmful bias is a hard, industry-wide issue that is extremely important. Ultimately, our API models do exhibit biases (as shown in the GPT-3 paper) that will appear on occasion in generated text. Our API models could also cause harm in ways that we haven’t thought of yet.
After the launch of the API, NVIDIA researcher Anima Anandkumar made a highly-debated tweet.
During my GPT-3 experiments, I found that generating tweets from @dril (admittingly an edgy Twitter user) ended up resulting in 4chan-level racism/sexism that I spent enormous amounts of time sanitizing, and it became more apparent at higher temperatures. It’s especially important to avoid putting offensive content for generated texts which put words in others’ mouths.
Jerome Pesenti, the head of AI at Facebook, also managed to trigger anti-semetic tweets from a GPT-3 app:
#gpt3 is surprising and creative but it’s also unsafe due to harmful biases. Prompted to write tweets from one word - Jews, black, women, holocaust - it came up with these (https://t.co/G5POcerE1h). We need more progress on #ResponsibleAI before putting NLG models in production. pic.twitter.com/FAscgUr5Hh
— Jerome Pesenti (@an_open_mind) July 18, 2020
Again, it depends on the domain. Would GPT-3 output racist or sexist React components? Likely not, but it’s something that would still need to be robustly checked. OpenAI does appear to take these concerns seriously, and has implemented toxicity detectors for generated content in the Web UI, although not the programmatic API yet.
Further Questions about the OpenAI API
AI model-as-a-service is an industry that tends to be a black box wrapped around another black box. Despite all the caveats, everything depends on how the OpenAI API exits beta and rolls out the API for production use. There are too many unknowns to even think about making money off of the OpenAI API, let alone making a startup based on it.
At minimum, anyone using the OpenAI API professionally needs to know:
- Cost for generation per token/request
- Rate limits and max number of concurrent requests
- Average and peak latencies for generating tokens
- SLA for the API
- AI generated content ownership/copyright
That’s certainly less magical!
The most important question mark there is cost: given the model size, I’m not expecting it to be cheap, and it’s entirely possible that the unit economics make most GPT-3-based startups infeasible.
That said, it’s still good for people to experiment with GPT-3 and the OpenAI API in order to show what the model is truly capable of. It won’t replace software engineering jobs anytime soon, or become Skynet, or whatever. But it’s objectively a step forward in the field of AI text-generation.
What about GPT-2? Since it’s unlikely that the other GPT-3 models will be open-sourced by OpenAI, GPT-2 isn’t obsolete, and there will still be demand for a more open text-generating model. However, I confess that the success of GPT-3 has demotivated me to continue working on my own GPT-2 projects, especially since they will now be impossible to market competitively (GPT-2 is a number less than GPT-3 after all).
All said, I’d be glad to use GPT-3 and the OpenAI API for both personal and professional projects once it’s out of beta, given that the terms of use for the API are reasonable. And if the hype becomes more leveled such that said projects can actually stand out.
