In February 2019, OpenAI released a paper describing GPT-2, a AI-based text-generation model based on the Transformer architecture and trained on massive amounts of text all around the internet. From a text-generation perspective, the included demos were very impressive: the text is coherent over a long horizon, and grammatical syntax and punctuation are near-perfect.
At the same time, the Python code which allowed anyone to download the model (albeit smaller versions out of concern the full model can be abused to mass-generate fake news) and the TensorFlow code to load the downloaded model and generate predictions was open-sourced on GitHub.
Neil Shepperd created a fork of OpenAI’s repo which contains additional code to allow finetuning the existing OpenAI model on custom datasets. A notebook was created soon after, which can be copied into Google Colaboratory and clones Shepperd’s repo to finetune GPT-2 backed by a free GPU. From there, the proliferation of GPT-2 generated text took off: researchers such as Gwern Branwen made GPT-2 Poetry and Janelle Shane made GPT-2 Dungeons and Dragons character bios.
I waited to see if anyone would make a tool to help streamline this finetuning and text generation workflow, a la textgenrnn which I had made for recurrent neural network-based text generation. Months later, no one did. So I did it myself. Enter gpt-2-simple, a Python package which wraps Shepperd’s finetuning code in a functional interface and adds many utilities for model management and generation control.
Thanks to gpt-2-simple and this Colaboratory Notebook, you can easily finetune GPT-2 on your own dataset with a simple function, and generate text to your own specifications!
How GPT-2 Works
OpenAI has released three flavors of GPT-2 models to date: the “small” 124M parameter model (500MB on disk), the “medium” 355M model (1.5GB on disk), and recently the 774M model (3GB on disk). These models are much larger than what you see in typical AI tutorials and are harder to wield: the “small” model hits GPU memory limits while finetuning with consumer GPUs, the “medium” model requires additional training techniques before it could be finetuned on server GPUs without going out-of-memory, and the “large” model cannot be finetuned at all with current server GPUs before going OOM, even with those techniques.
The actual Transformer architecture GPT-2 uses is very complicated to explain (here’s a great lecture). For the purposes of finetuning, since we can’t modify the architecture, it’s easier to think of GPT-2 as a black box, taking in inputs and providing outputs. Like previous forms of text generators, the inputs are a sequence of tokens, and the outputs are the probability of the next token in the sequence, with these probabilities serving as weights for the AI to pick the next token in the sequence. In this case, both the input and output tokens are byte pair encodings, which instead of using character tokens (slower to train but includes case/formatting) or word tokens (faster to train but does not include case/formatting) like most RNN approaches, the inputs are “compressed” to the shortest combination of bytes including case/formatting, which serves as a compromise between both approaches but unfortunately adds randomness to the final generation length. The byte pair encodings are later decoded into readable text for human generation.
The pretrained GPT-2 models were trained on websites linked from Reddit. As a result, the model has a very strong grasp of the English language, allowing this knowledge to transfer to other datasets and perform well with only a minor amount of additional finetuning. Due to the English bias in encoder construction, languages with non-Latin characters like Russian and CJK will perform poorly in finetuning.
When finetuning GPT-2, I recommend using the 124M model (the default) as it’s the best balance of speed, size, and creativity. If you have large amounts of training data (>10 MB), then the 355M model may work better.
gpt-2-simple And Colaboratory
In order to better utilize gpt-2-simple and showcase its features, I created my own Colaboratory Notebook, which can be copied into your own Google account. A Colaboratory Notebook is effectively a Jupyter Notebook running on a free (w/ a Google Account) virtual machine with an Nvidia server GPU attached (randomly a K80 or a T4; T4 is ideal) that normally can be cost-prohibitive.
Once open, the first cell (run by pressing Shift+Enter in the cell or mousing-over the cell and pressing the “Play” button) of the notebook installs gpt-2-simple and its dependencies, and loads the package.

Later in the notebook is gpt2.download_gpt2() which downloads the requested model type to the Colaboratory VM (the models are hosted on Google’s servers, so it’s a very fast download).
Expanding the Colaboratory sidebar reveals a UI that you can use to upload files. For example, the tinyshakespeare dataset (1MB) provided with the original char-rnn implementation. Upload a text file via the UI (you can drag and drop), run the file_name = '<xxx>' cell with your filename changed in the cell.
Now we can start finetuning! This finetuning cell loads the specified dataset and trains for the specified number of steps (the default of 1,000 steps is enough to allow distinct text to emerge and takes about 45 minutes, but you can increase the number of steps if necessary).
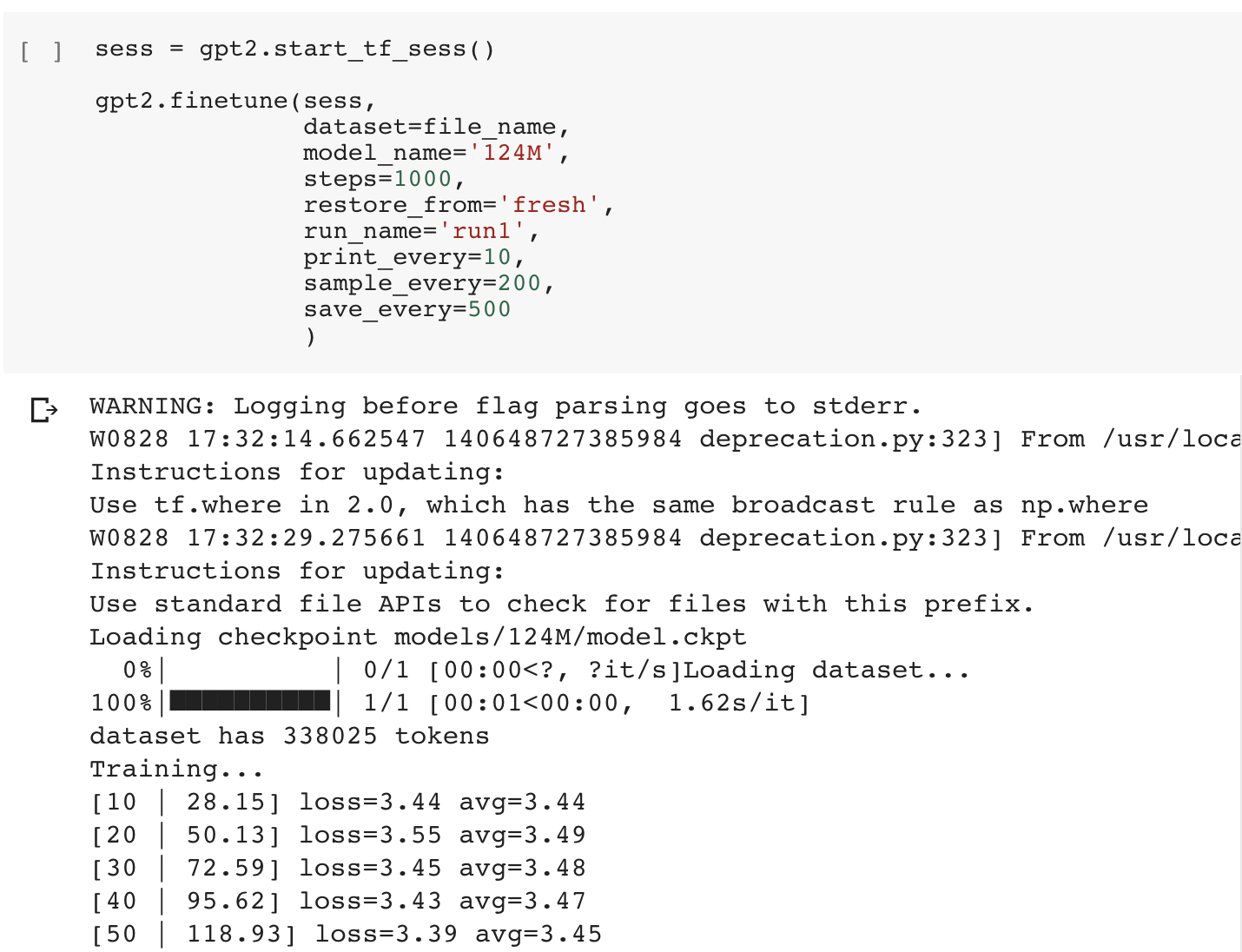
While the model is finetuning, the average training loss is output every-so-often to the cell. The absolute value of the loss is not important (the output text quality is subjective), but if the average loss stops decreasing, that’s a sign the model has converged and additional training may not help improve the model.
By default, your model is saved in the checkpoint/run1 folder, and you’ll need to use that folder to load the model as well (you can specify the run_name when using other functions categorize finetuned models). If you want to export the model from Colaboratory, it’s recommended you do so via Google Drive (as Colaboratory does not like exporting large files). Run the gpt2.mount_gdrive() cell to mount your Google Drive in the Colaboratory VM, then run the gpt2.copy_checkpoint_to_gdrive() cell. You can then download the compressed model folder from Google Drive and run the model wherever you want. Likewise, you can use the gpt2.copy_checkpoint_from_gdrive() cell to retrieve a stored model and generate in the notebook.
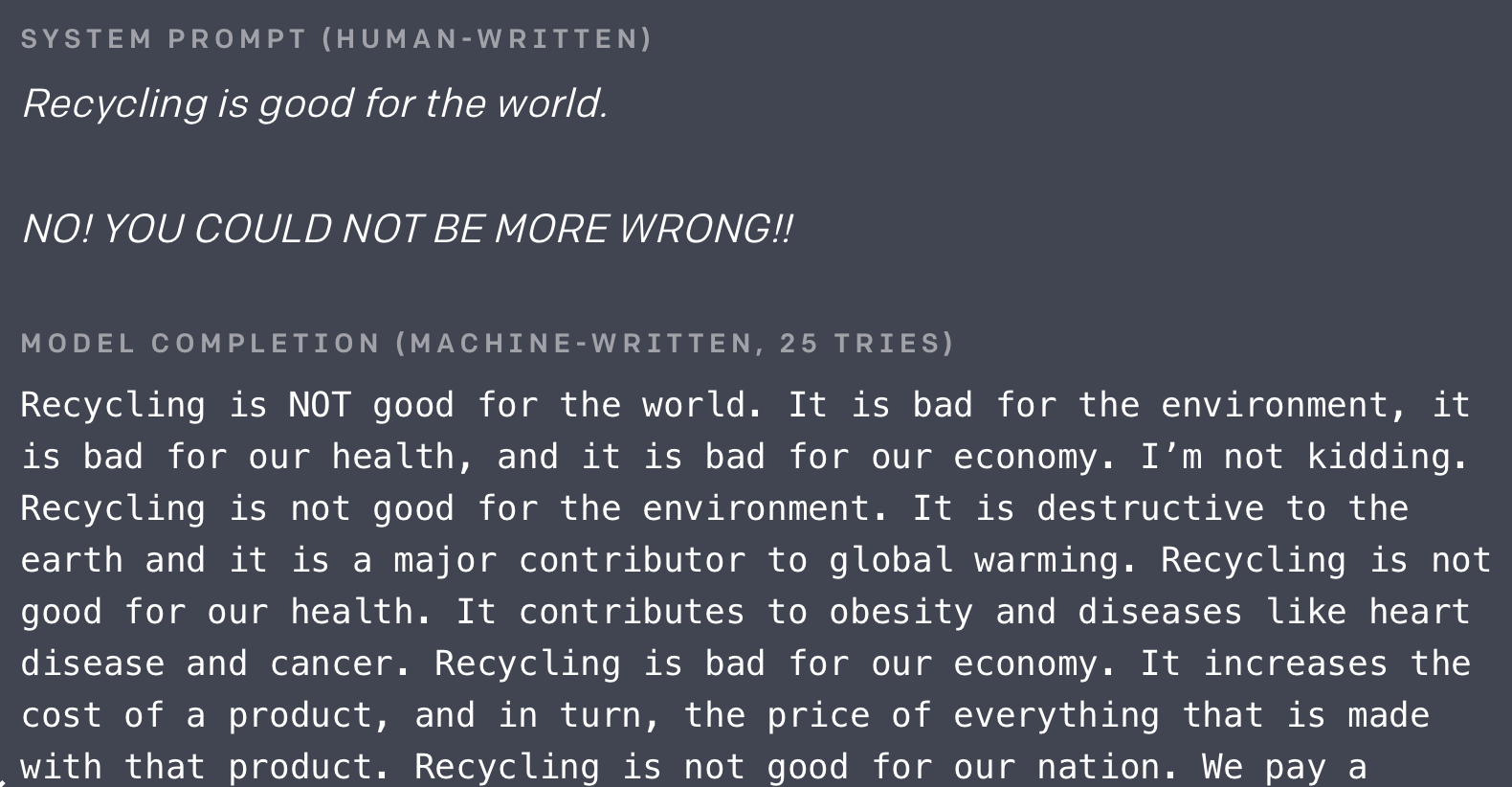
Speaking of generation, once you have a finetuned model, you can now generate custom text from it! By default, the gpt2.generate() function will generate as much text as possible (1,024 tokens) with a little bit of randomness. An important caveat: you will not get good generated text 100% of the time, even with a properly trained model (the OpenAI demo above took 25 tries to get good text!).

You can also increase the temperature to increase “creativity” by allowing the network to more likely make suboptimal predictions, provide a prefix to specify how exactly you want your text to begin. There are many other useful configuration parameters, such as top_p for nucleus sampling.

As a bonus, you can bulk-generate text with gpt-2-simple by setting nsamples (number of texts to generate total) and batch_size (number of texts to generate at a time); the Colaboratory GPUs can support a batch_size of up to 20, and you can generate these to a text file with gpt2.generate_to_file(file_name) with the same parameters as gpt2.generate(). You can download the generated file locally via the sidebar, and use those to easily save and share the generated texts.
The notebook has many more functions as well, with more parameters and detailed explanations! The gpt-2-simple README lists additional features of gpt-2-simple if you want to use the model outside the notebook.
(NB: Currently, you’ll need to reset the Notebook via Runtime → Restart Runtime to finetune a different model/dataset or load a different finetuned model.)
GPT-2 For Short Texts
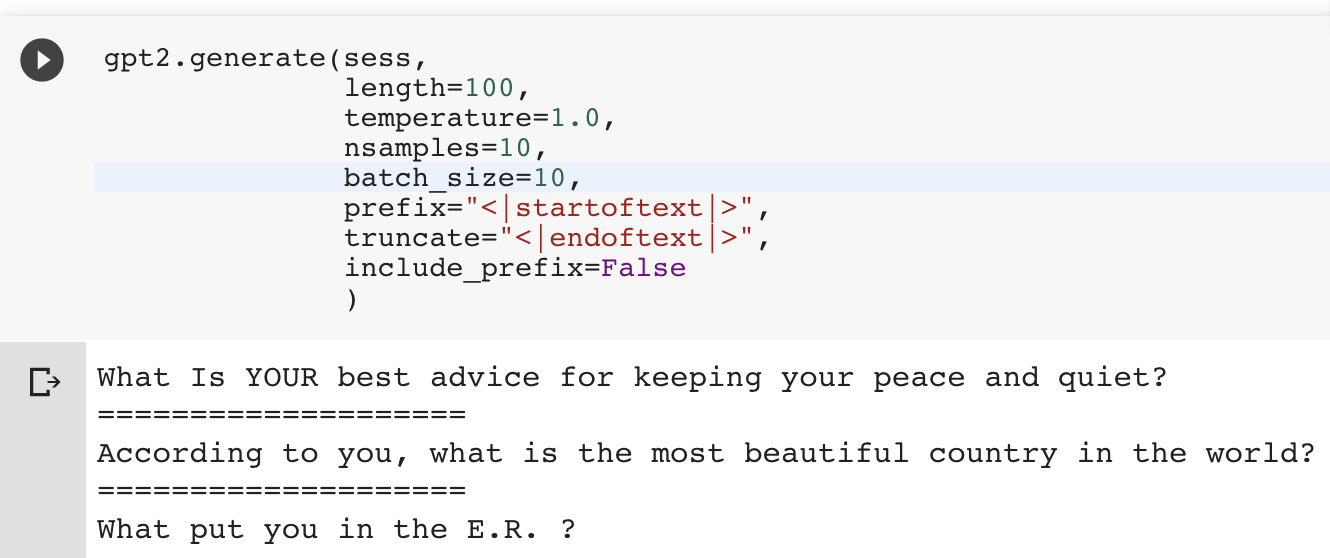
A weakness of GPT-2 and other out-of-the-box AI text generators is that they are built for longform content, and keep on generating text until you hit the specified length. Another reason I wanted to make gpt-2-simple was to add explicit processing tricks to the generated text to work around this issue for short texts. In this case, there are two additional parameters that can be passed to gpt2.generate(): truncate and include_prefix. For example, if each short text begins with a <|startoftext|> token and ends with a <|endoftext|>, then setting prefix='<|startoftext|>', truncate=<|endoftext|>', and include_prefix=False, and length is sufficient, then gpt-2-simple will automatically extract the shortform texts, even when generating in batches.
Let’s finetune a GPT-2 model on Reddit submission titles. This query, when run on BigQuery (for free), returns the top 16,000 titles by score between January and March 2019 for a given Reddit subreddit (in this case, /r/AskReddit) + minor text preprocessing, which can be downloaded locally as a 1.3 MB CSV (Save Results → CSV [local file]):
#standardSQL
SELECT
REGEXP_REPLACE(REGEXP_REPLACE(REGEXP_REPLACE(REGEXP_REPLACE(title, '&', '&'), '<', '<'), '>', '>'), '�', '') AS title
FROM
`fh-bigquery.reddit_posts.*`
WHERE
_TABLE_SUFFIX BETWEEN '2019_01' AND '2019_03'
AND LENGTH(title) >= 8
AND LOWER(subreddit) = 'askreddit'
ORDER BY
score DESC
LIMIT
16000
With gpt-2-simple, using a single-column CSV like the one generated above as the input dataset will automatically add <|startoftext|> and <|endoftext|> tokens appropriately. Finetune a new GPT-2 model as normal, and then generate with those additional parameters mentioned above:
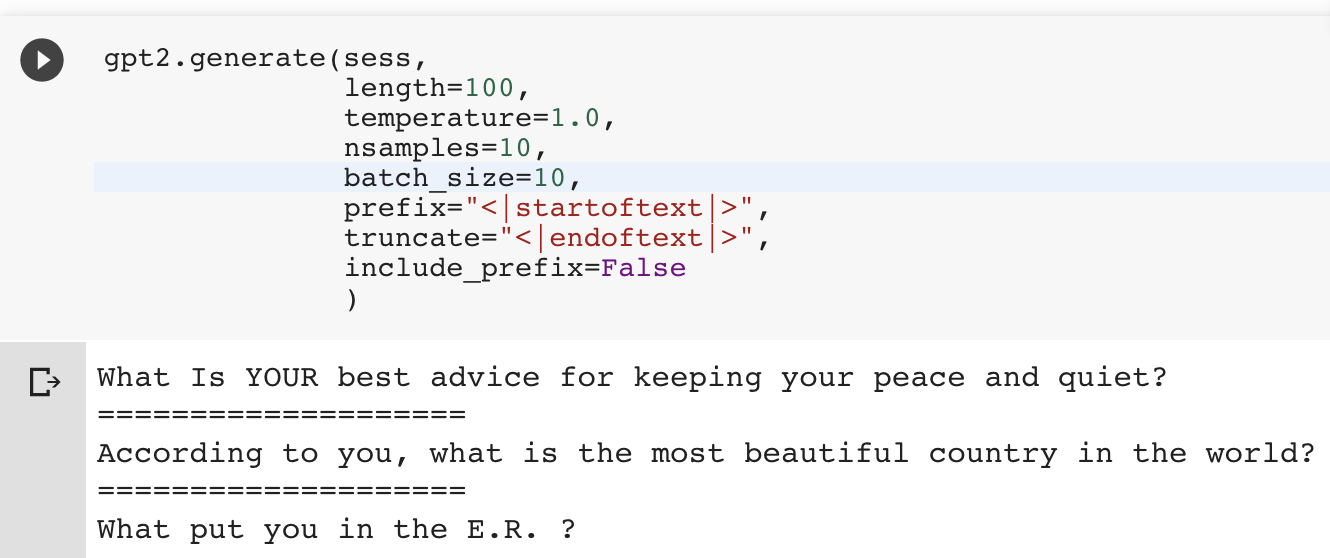
It’s worth noting that despite a good amount of input data to the model, finetuned networks can easily overfit on short form text: some of these example titles are very close to existing /r/AskReddit titles. Overfitting can be rectified by training for less time, or adding more input data. Make sure to double check that your generated text is unique!
You can play with this Reddit-oriented variant in this modified Colaboratory Notebook.
Making GPT-2 Apps
There have already been cool, non-nefarious uses of GPT-2, such as Adam King’s TalkToTransformer which provides a UI for the 774M model (and has gone viral many times) and TabNine, which uses GPT-2 finetuned on GitHub code in order to create probabilistic code completion. On the PyTorch side, Huggingface has released a Transformers client (w/ GPT-2 support) of their own, and also created apps such as Write With Transformer to serve as a text autocompleter.
Many AI tutorials often show how to deploy a small model to a web service by using the Flask application framework. The problem with GPT-2 is that it’s such a huge model that most conventional advice won’t work well to get a performant app. And even if you do get it to run fast (e.g. by running the app on a GPU), it won’t be cheap, especially if you want it to be resilient to a random surge of virality.
With gpt-2-simple, the solution I came up with is gpt-2-cloud-run; a small webapp intended to run GPT-2 via Google Cloud Run backed by gpt-2-simple. The advantage here is that Cloud Run only charges for compute used and can scale indefinitely if there’s a traffic surge; for casual use, it’s extremely cost effective compared to running a GPU 24/7. I’ve used Cloud Run to make a GPT-2 text generator for Reddit-wide submission titles and a GPT-2 generator for Magic: The Gathering cards!

Attributing AI-Generated Text
One of the main reasons I developed textgenrnn and gpt-2-simple is to make AI text generation more accessible as you do not need a strong AI or technical background to create fun stories. However, in the case of GPT-2, I’ve noticed an elevated amount of “I trained an AI to generate text” articles/Reddit posts/YouTube videos saying they used GPT-2 to train an AI, but not how they trained the AI: especially suspicious since finetuning is not an out-of-the-box feature that OpenAI provides. The fact that Keaton Patti’s “I forced a bot” movie scripts (that aren’t written by a bot) frequently go megaviral due to that particular framing doesn’t help.
Although it’s not legally required, I ask that anyone who shares generated text via gpt-2-simple add a link to the repo and/or Colaboratory notebook not just for attribution, but to spread knowledge about the accessibility of AI text generation. It’s a technology that should be transparent, not obfuscated for personal gain.
The Future of GPT-2
Hopefully, this article gave you ideas on how to finetune and generate texts creatively. There’s still a lot of untapped potential, and there are still many cool applications that have been untouched, and many cool datasets that haven’t been used for AI text generation. GPT-2 will likely be used more for mass-producing crazy erotica than fake news.
However, GPT-2 and the Transformer architecture aren’t the end-game of AI text generation. Not by a long shot.
