Reddit, “the front page of the internet” is a link aggregator where anyone can submit links to cool happenings. Over the years, Reddit has expanded from just being a link aggregator, to allowing image and videos, and as of recently, hosting images and videos itself.
Reddit is broken down into subreddits, where each subreddit represents each own community around a particular interest, like /r/aww for pet photos and /r/politics for U.S. politics. The posts on each subreddit are ranked by some function of both time elapsed since the submission was made, and the score of the submission as determined by upvotes and downvotes from other users.
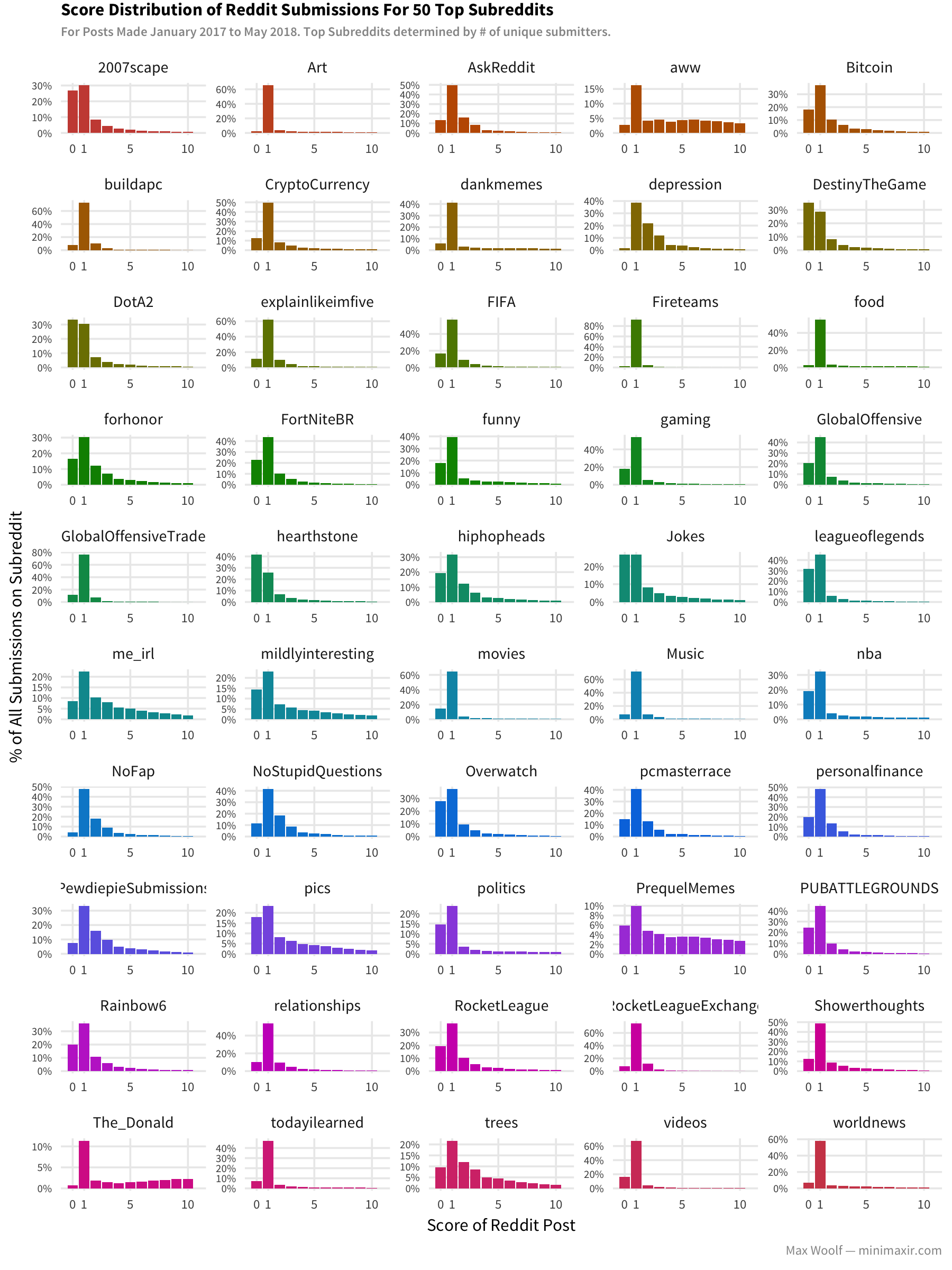
There’s also an intrinsic pride in having something you’re responsible for providing to the community get lots of upvotes (the submitter also earns karma based on received upvotes, although karma is meaningless and doesn’t provide any user benefits). But the reality is that even on the largest subreddits, submissions with 1 point (the default score for new submissions) are the most prominent, with some subreddits having over half of their submissions with only 1 point.
The exposure from having a submission go viral on Reddit (especially on larger subreddits) can be valuable especially if its your own original content. As a result, there has been a lot of analysis/stereotypes on what techniques to do to help your submission make it to the top of the front page. But almost all claims of “cracking” the Reddit algorithm are post hoc rationalizations, attributing success to things like submission timing and title verbiage of a single submission after the fact. The nature of algorithmic feeds inherently leads to a survivorship bias: although users may recognize certain types of posts that appear on the front page, there are many more which follow the same patterns but fail, which makes modeling a successful post very tricky.
I’ve touched on analyzing Reddit post performance before, but let’s give it another look and see if we can drill down on why Reddit posts do and do not do well.
Submission Timing
As with many US-based websites, the majority of Reddit users are most active during work hours (9 AM — 5 PM Eastern time weekdays). Most subreddits have submission patterns which fit accordingly.
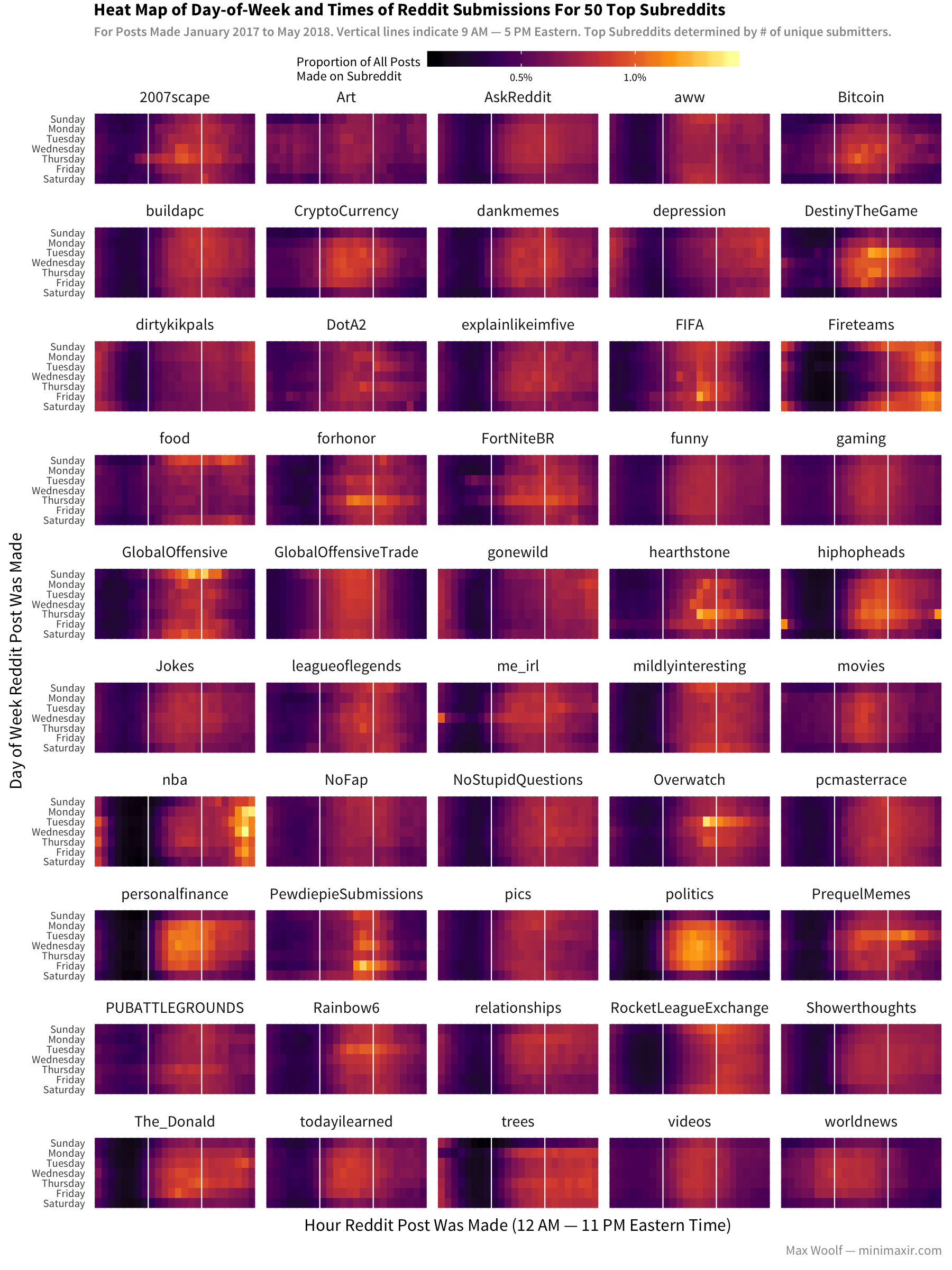
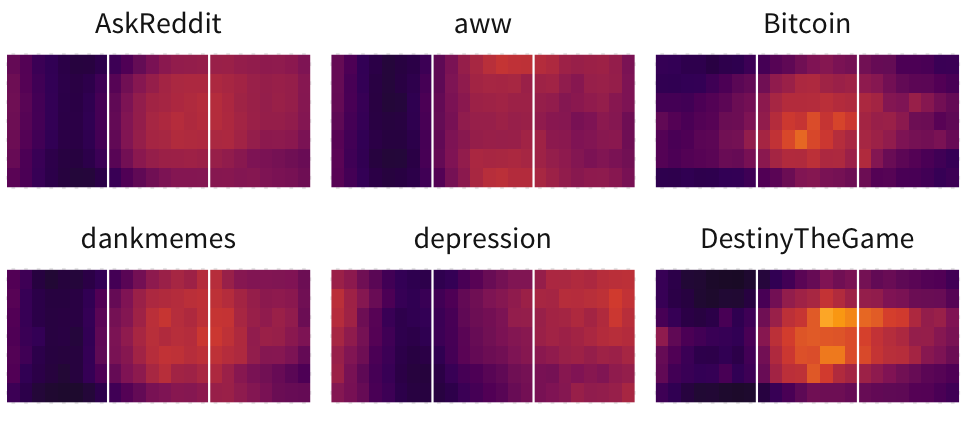
But what’s interesting are the subreddits which deviate from that standard. Gaming subreddits (/r/DestinyTheGame, /r/Overwatch) have short activity after a Tuesday game update/patch, game communication subreddits (/r/Fireteams, /r/RocketLeagueExchange) are more active outside of work hours as they assume you are playing the game at the time, and Not-Safe-For-Work subreddits (/r/dirtykikpals, /r/gonewild) are incidentally less active during work hours and more active late-night than other subreddits.
Whenever you make a submission to Reddit, the submission appears in the subreddit’s /new queue of the most recent submissions, where hopefully kind souls will find your submission and upvote it if it’s good.
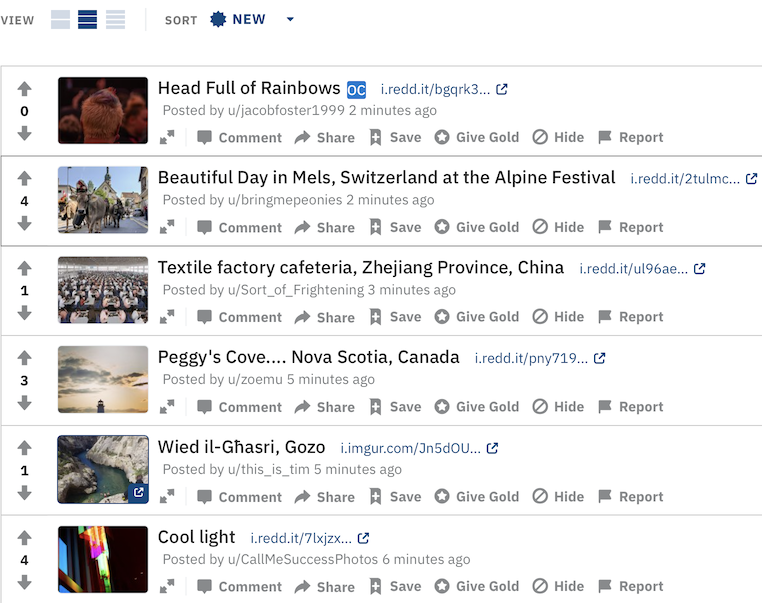
However, if it falls off the first page of the /new queue, your submission might be as good as dead. As a result, there’s an element of game theory to timing your submission if you want it to not become another 1-point submission. Is it better to submit during peak hours when more users may see the submission before it falls off of /new? Is it better to submit before peak usage since there will be less competition, then continue the momentum once it hits the front page?
Here’s a look at the median post performance at each given time slot for top subreddits:
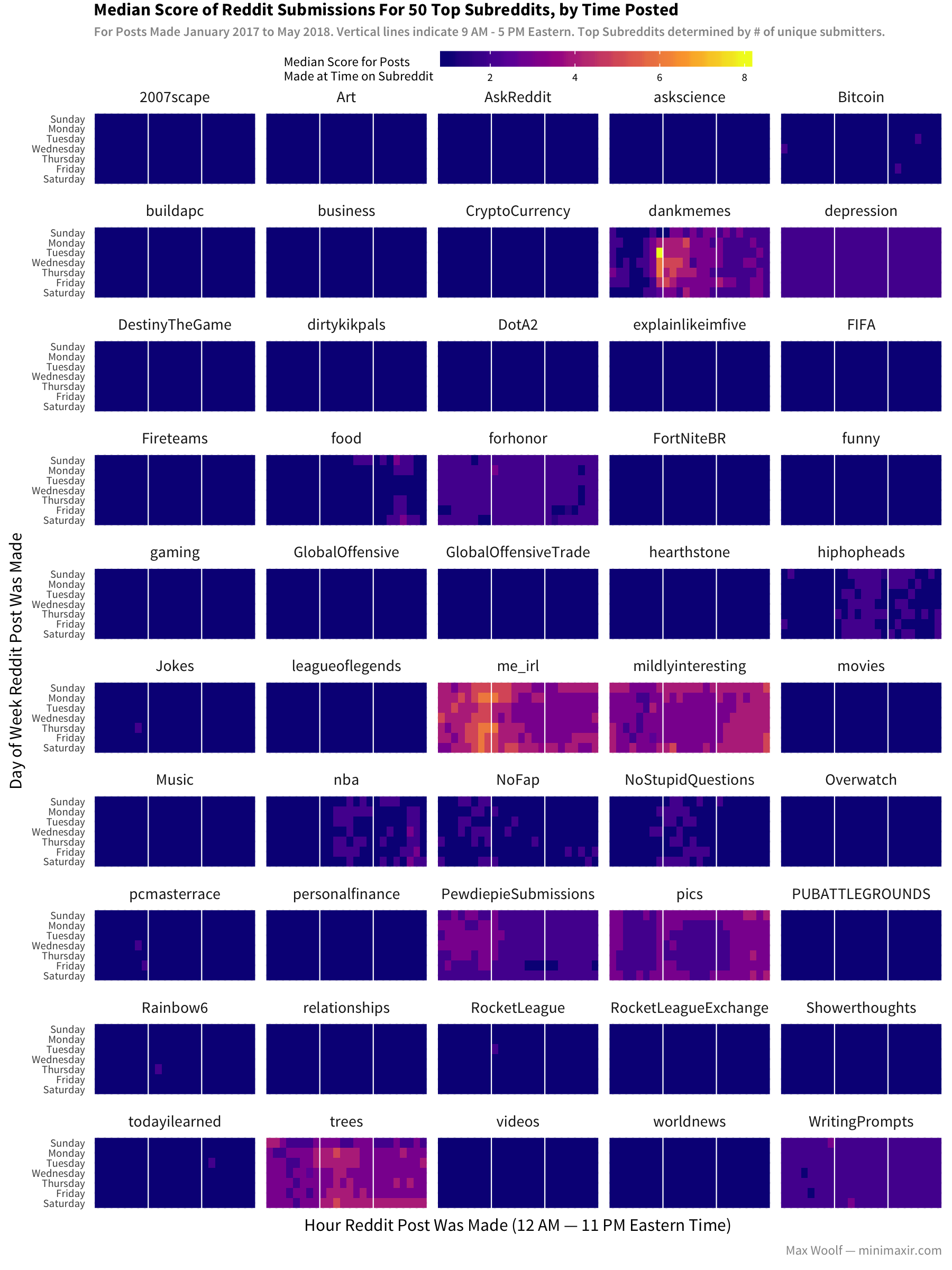
As the earlier distribution chart implied, the median score is around 1-2 for most subreddits, and that’s consistent across all time slots. Some subreddits with higher medians like /r/meirl do appear to have a _slight benefit when posting before peak activity. When focusing on subreddits with high overall median scores, the difference is more explicit.
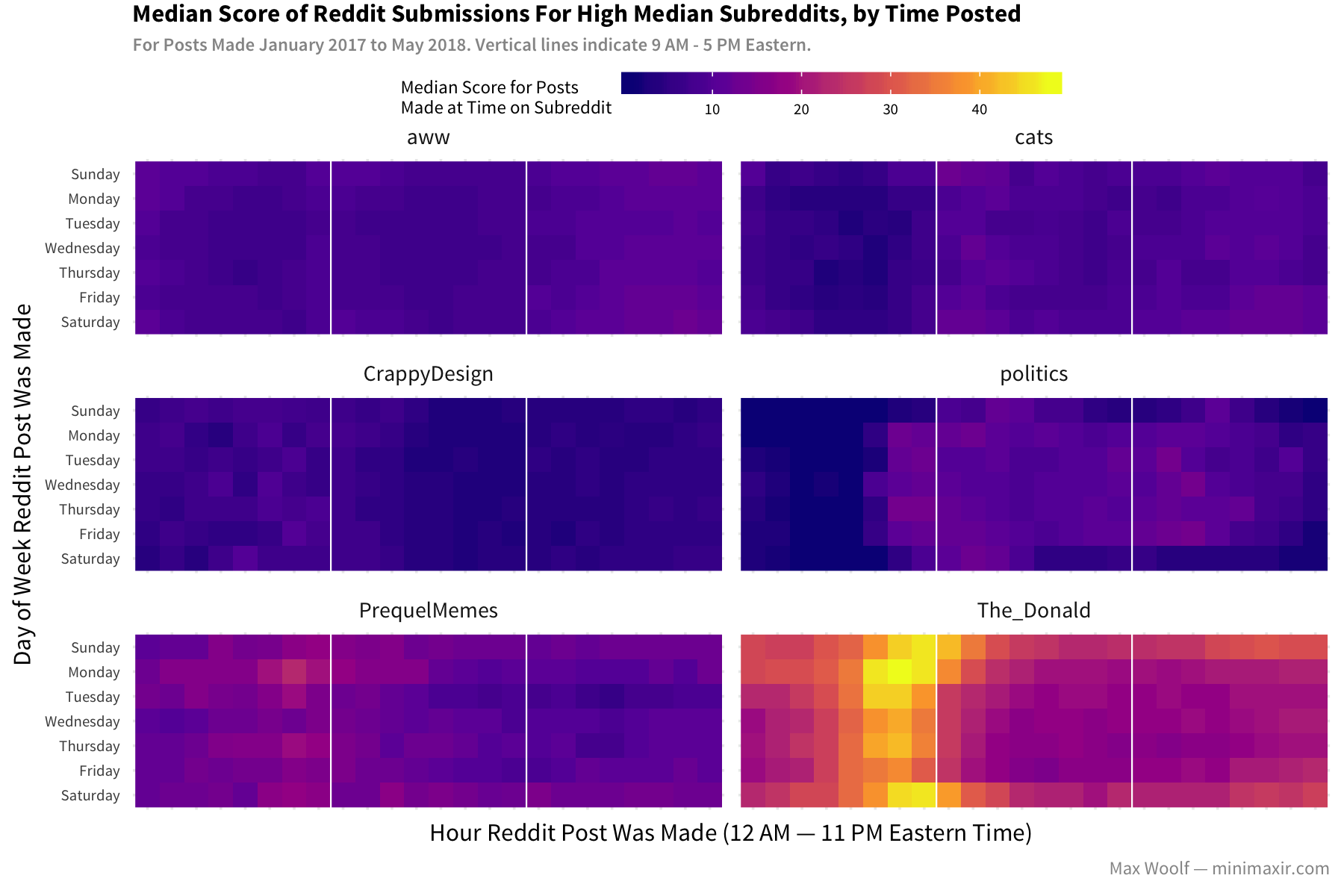
Subreddits like /r/PrequelMemes and /r/TheDonald _definitely have better performance on average when made before peak activity! Posting before peak usage does appear to be a viable strategy, however for the majority of subreddits it doesn’t make much of a difference.
Submission Titles
Each Reddit subreddit has their own vocabulary and topics of discussion. Let’s break down text by subreddit by looking at the 75th percentile for score on posts containing a given two-word phrase:
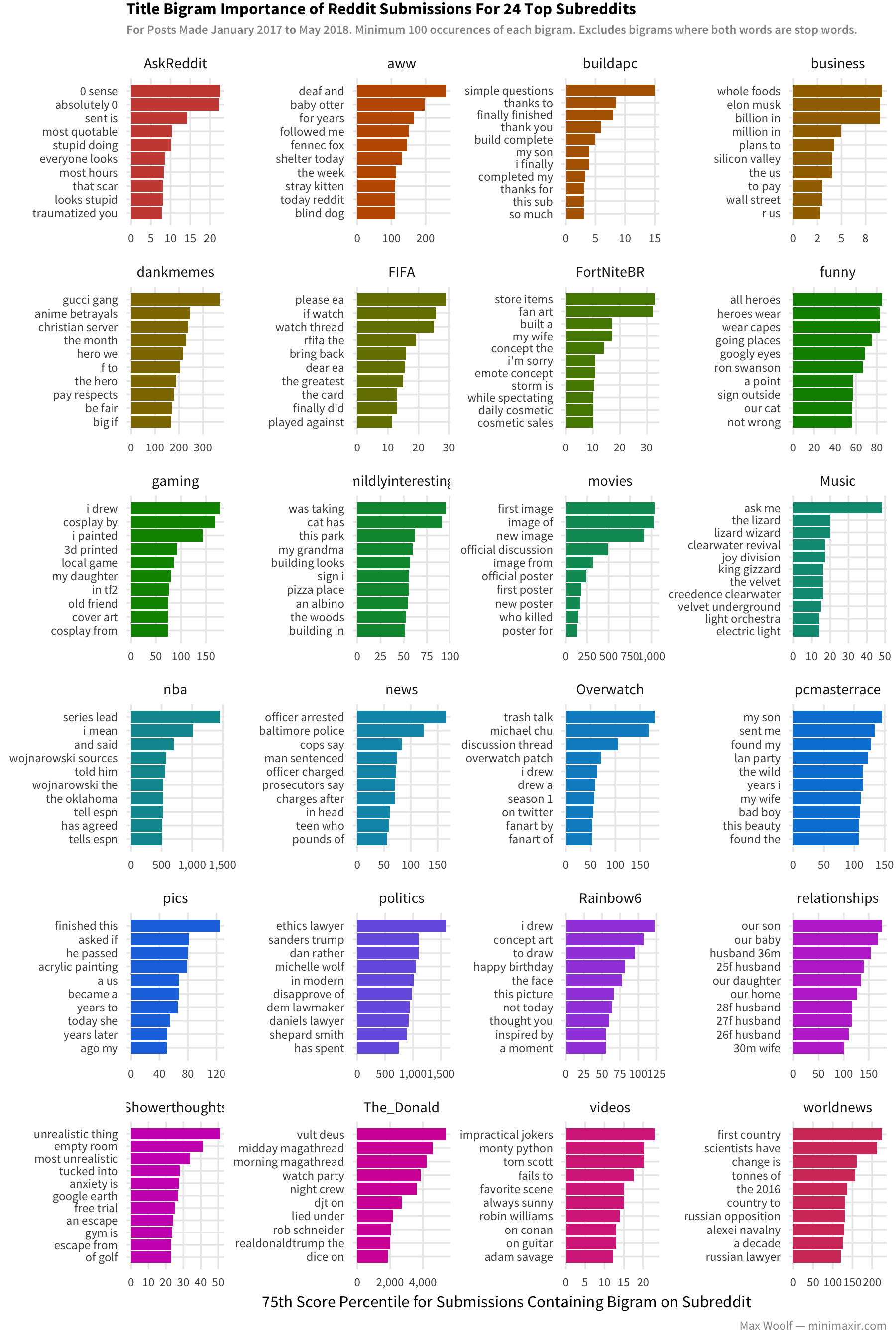
The one trend consistent across all subreddits is the effectiveness of first-person pronouns (I/my) and original content (fan art). Other than that, the vocabulary and sentiment for successful posts is very specific to the subreddit and culture is represents; no universal guaranteed-success memes.
Can Deep Learning Predict Post Performance?
Some might think “oh hey, this is an arbitrary statistical problem, you can just build an AI to solve it!” So, for the sake of argument, I did.
Instead of using Reddit data for building a deep learning model, we’ll use data from Hacker News, another link aggregator similar to Reddit with a strong focus on technology and startup entrepreneurship. The distribution of scores on posts, submission timings, upvoting, and front page ranking systems are all the same as on Reddit.
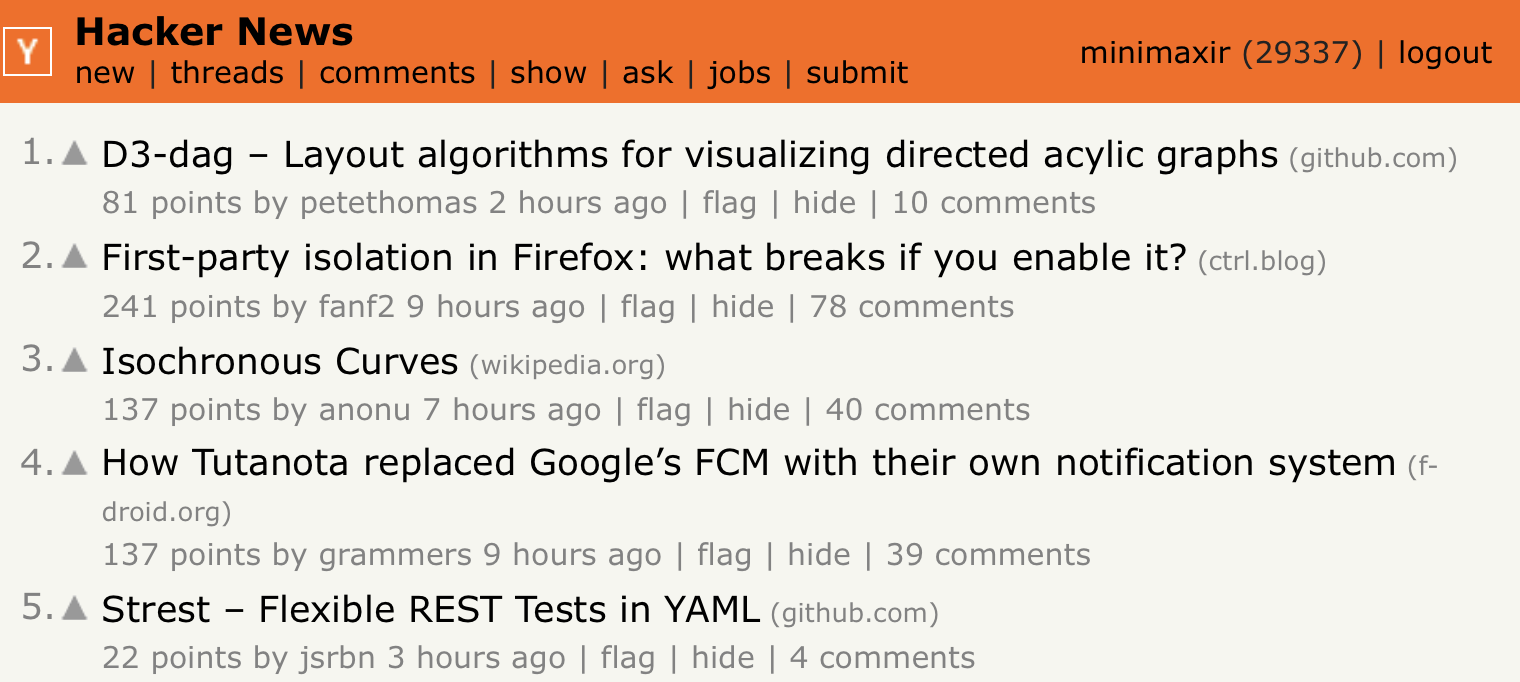
The titles on Hacker News submissions are also shorter (80 characters max vs. Reddit’s 300 character max) and in concise English (no memes/shitposts allowed), which should help the model learn the title syntax and identify high-impact keywords easier. Like Reddit, the score data is super-skewed with most HN submissions at 1-2 points, and typical model training will quickly converge but try to predict that every submission has a score of 1, which isn’t helpful!
By constructing a model employing many deep learning tricks with Keras/TensorFlow to prevent model cheating and training on hundreds of thousands of HN submissions (using post title, day-of-week, hour, and link domain like github.com as model features), the model does converge and finds some signal among the noise (training R2 ~ 0.55 when trained for 50 epochs). However, it fails to offer any valuable predictions on new, unseen posts (test R2 < 0.00) because it falls into the same exact human biases regarding titles: it saw submissions with titles that did very well during training, but can’t isolate the random chance why X and Y submissions are similar but X goes viral while Y does not.

I’ve made the Keras/TensorFlow model training code available in this Kaggle Notebook if you want to fork it and try to improve the model.
Other Potential Modeling Factors
The deep learning model above makes optimistic assumptions about the underlying data, including that each post behaves independently, and the included features are the sole features which determine the score. These assumptions are questionable.
The simple model forgoes the content of the submission itself, which is hard to retrieve for hundreds of thousands of data points. On Hacker News that’s mostly OK since most submissions are links/articles which accurately correlate to the content, although occasionally there are idiosyncratic short titles which do the opposite. On Reddit, obviously looking at content is necessary for image/video-oriented subreddits, which is hard to gather and analyze at scale.
A very important concept of post performance is momentum. A post having a high score is a positive signal in itself, which begets more votes (a famous Reddit problem is brigading from /r/all which can cause submission scores to skyrocket). If the front page of a subreddit has a large number of high-performing posts, they might also suppress posts coming out of the /new queue because the score threshold is much higher. A simple model may not be able to capture these impacts; the model would need to incorporate the state of the front page at the time of posting.
Some also try to manipulate upvotes. Reddit became famous for adding the rule “asking for upvotes is a violation of intergalactic law” to their Content Policy, although some subreddits do it anyway without consequence. On Reddit, obvious spam posts can be downvoted to immediately counteract illicit upvotes. Hacker News has a similar don’t-upvote rule, although there aren’t downvotes, just a flagging mechanism which quickly neutralizes spam/misleading posts. In general, there’s no legitimate reason to highlight your own submission immediately after its posted (except for Reddit’s AMAs). Fortunately, gaming the system is less impactful on Reddit and Hacker News due to their sheer size and countermeasures, but it’s a good example of potential user behavior that makes modeling post performance difficult, and hopefully link aggregators of the future aren’t susceptible to such shenanigans.
Do We Really to Predict Post Score?
Let’s say you are submitting original content to Reddit or your own tech project to Hacker News. More points means a higher ranking means more exposure for your link, right? Not exactly. As noted from Reddit/HN screenshots above, the scores of popular submissions are all over the place ranking-wise, having been affected by age penalties.
In practical terms, from my own purely anecdotal experience, submissions at a top ranking receive substantially more clickthroughs despite being spatially close on the page to others.
…and now traffic at #3.
Placement is absurdly important for search engines/social media sites. Difference between #1 and #3 is dramatic. pic.twitter.com/nGjWJBx6dU
In that case, falling from #1 to #3 immediately halved the referral traffic coming from Hacker News.
Therefore, an ideal link aggregator predictive model to maximize clicks should try to predict the rank of a submission (max rank, average rank over n period, etc.), not necessarily the score it receives. You could theoretically create a model by making a snapshot of a Reddit subreddit/front page of Hacker News every minute or so which includes the post position at the time of the snapshot. As mentioned earlier, the snapshots can also be used as a model feature to identify whether the front page is active or stale. Unfortunately, snapshots can’t be retrieved retroactively, and both storing, processing, and analyzing snapshots at scale is a difficult and expensive feat of data engineering.
Presumably Reddit’s data scientists would be incorporating submission position as a part of their data analytics and modeling, but after inspecting what’s sent to Reddit’s servers when you perform an action like upvoting, I wasn’t able to find a sent position value when upvoting from the feed: only the post score and post upvote percentage at the time of the action were sent.
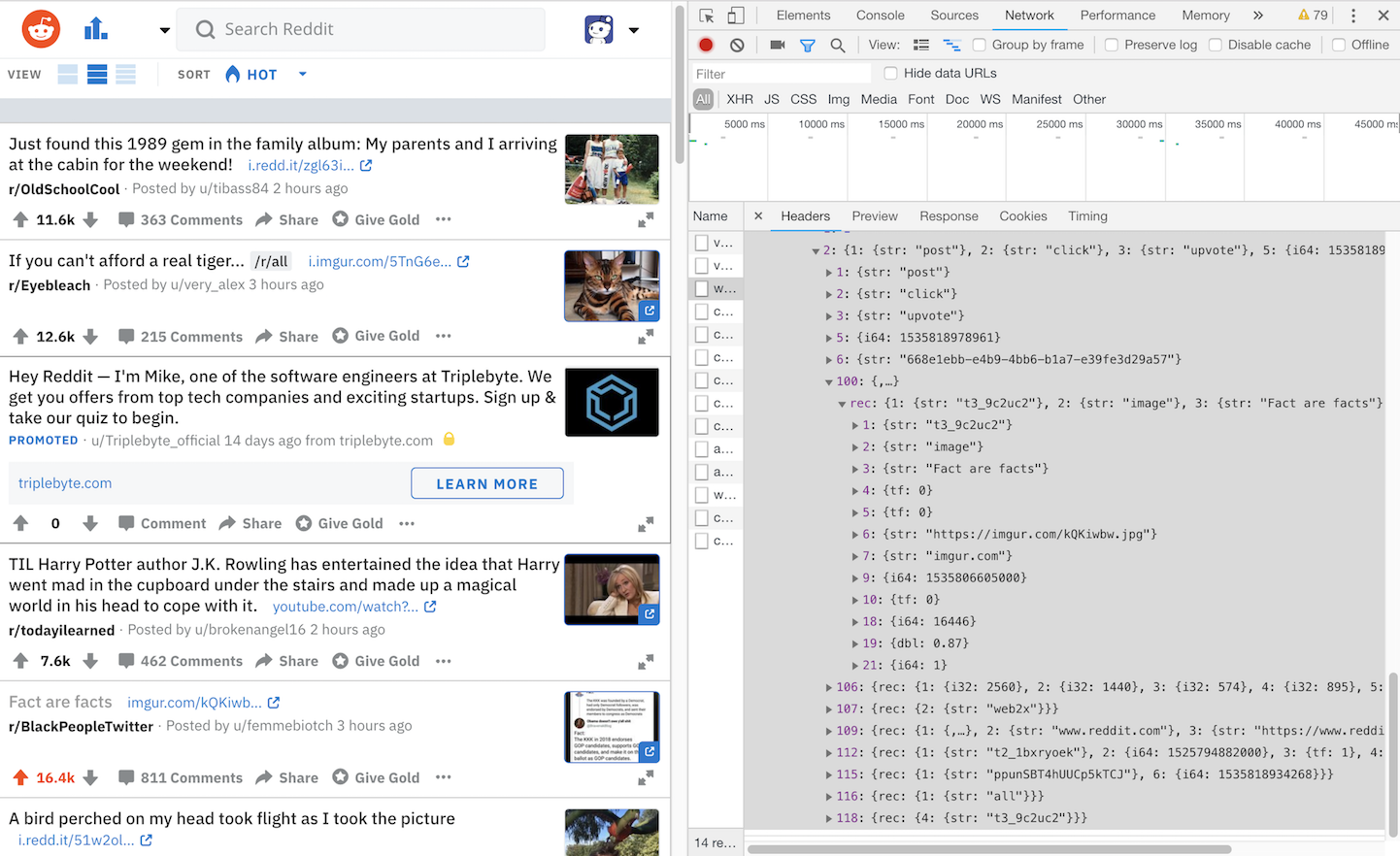
In this example, I upvoted the Fact are facts submission at position #5: we’d expect a value between 3 and 5 be sent with the post metadata within the analytics payload, but that’s not the case.
Optimizing ranking instead of a tangible metric or classification accuracy is a relatively underdiscussed field of modern data science (besides SEO for getting the top spot on a Google search), and it would be interesting to dive deeper into it for other applications.
In the future
The moral of this post is that you should not take it personally if a submission fails to hit the front page. It doesn’t necessarily mean it’s bad. Conversely, if a post does well, don’t assume that similar posts will do just as well. There’s a lot of quality content that falls through the cracks due to dumb luck. Fortunately, both Reddit and Hacker News allow reposts, which helps alleviate this particular problem.
There’s still a lot that can be done to more deterministically predict the behavior of these algorithmic feeds. There’s also room to help make these link aggregators more fair. Unfortunately, there’s even more undiscovered ways to game these algorithms, and we’ll see how things play out.
You can view the BigQuery queries used to get the Reddit and Hacker News data, plus the R and ggplot2 used to create the data visualizations, in this R Notebook. You can also view the images/code used for this post in this GitHub repository.
You are free to use the data visualizations from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
