So March Madness is happing right now. In celebration, Google uploaded massive basketball datasets from the NCAA and Sportradar to BigQuery for anyone to query and experiment. After learning that the dataset had location data on where basketball shots were made on the court, I played with it and a couple hours later, I created a decent heat map data visualization. The next day, I posted it to Reddit’s /r/dataisbeautiful subreddit where it earned about 40,000 upvotes. (!?)
Let’s dig a little deeper. Although visualizing basketball shots has been done before, this time we have access to an order of magnitude more public data to do some really cool stuff.
Full Court
The Sportradar play-by-play table on BigQuery mbb_pbp_sr has more than 1 million NCAA men’s basketball shots since the 2013-2014 season, with more being added now during March Madness. Here’s a heat map of the locations where those shots were made on the full basketball court:
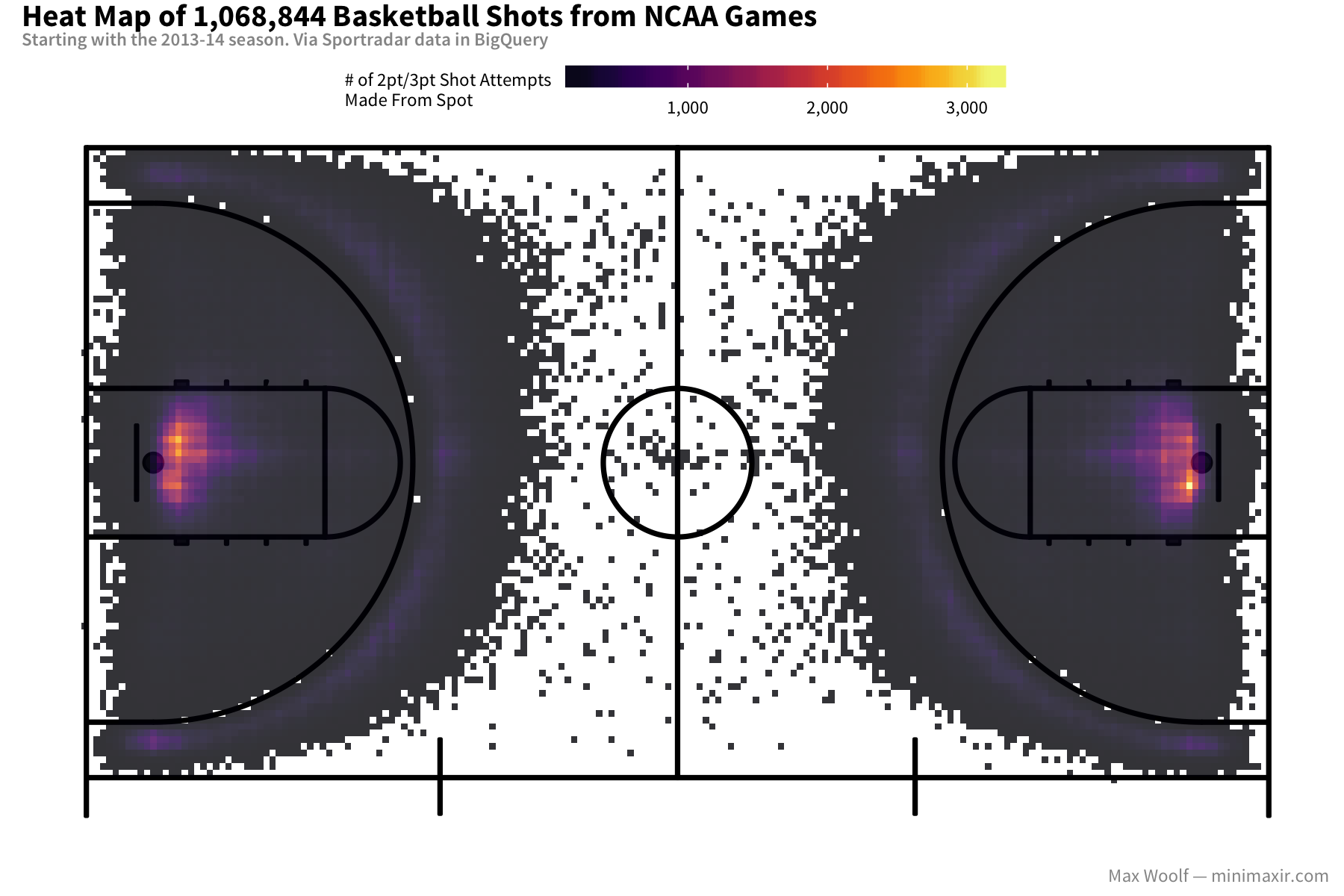
We can clearly see at a glance that the majority of shots are made right in front of the basket. For 3-point shots, the center and the corners have higher numbers of shot attempts than the other areas. But not much else since the data is so spatially skewed: setting the bin color scale to logarithmic makes trends more apparent and helps things go viral on Reddit.
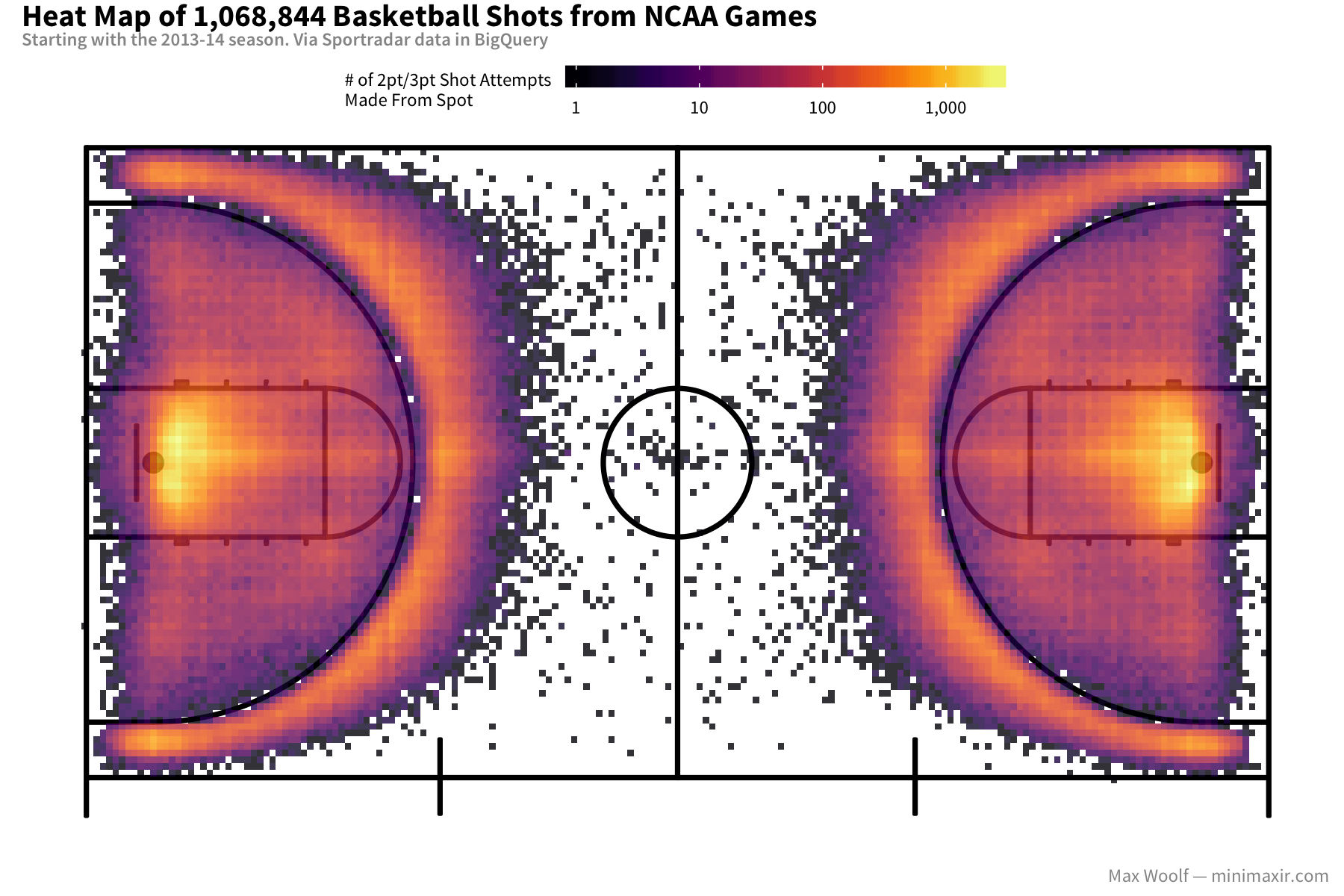
Now there’s more going on here: shot behavior is clearly symmetric on each side of the court, and there’s a small gap between the 3-point line and where 3-pt shots are typically made, likely to ensure that it it’s not accidentally ruled as a 2-pt shot.
How likely is it to score a shot from a given spot? Are certain spots better than others?
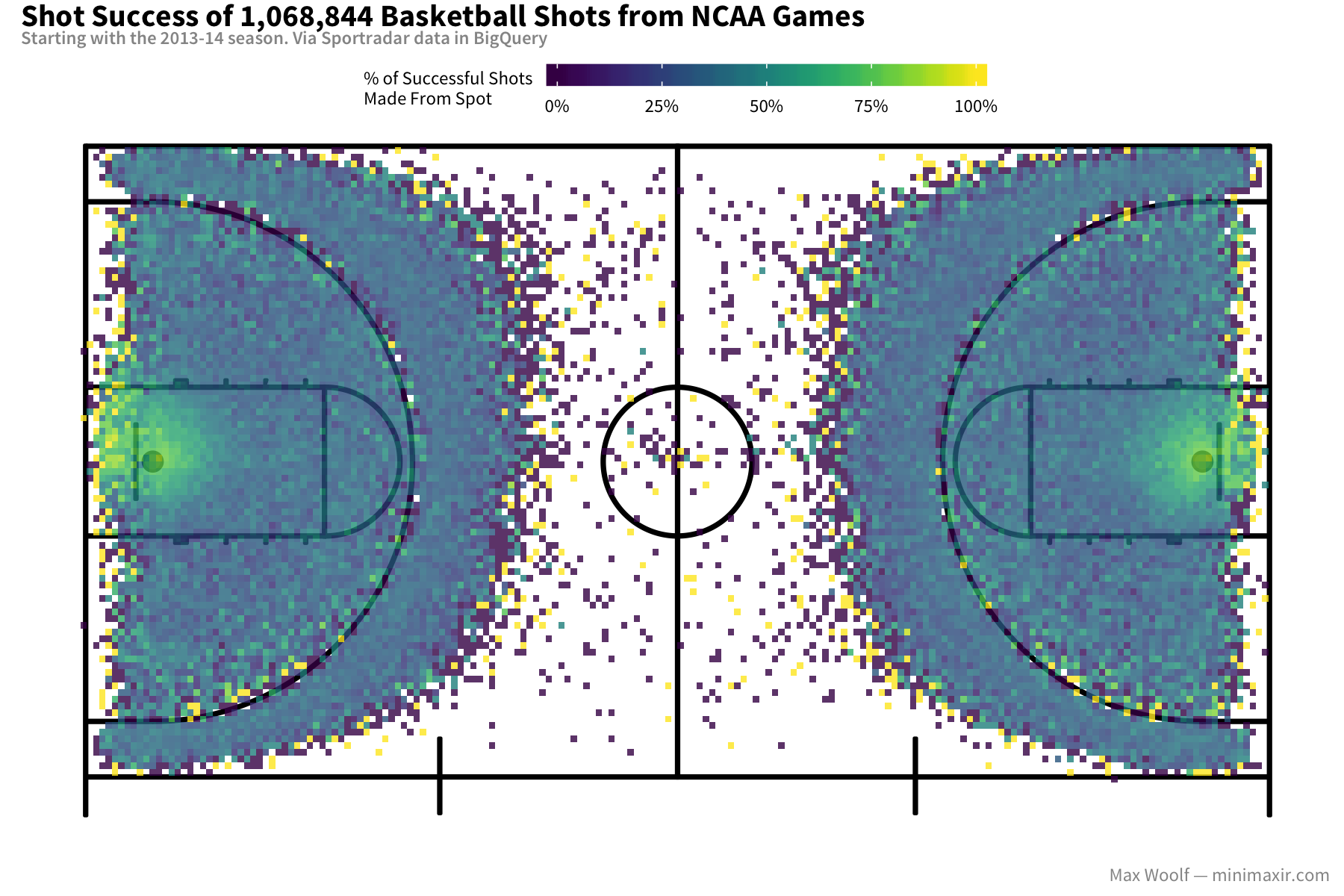
Surprisingly, shot accuracy is about equal from anywhere within typical shooting distance, except directly in front of the basket where it’s much higher. What is the expected value of a shot at a given position: that is, how many points on average will they earn for their team?
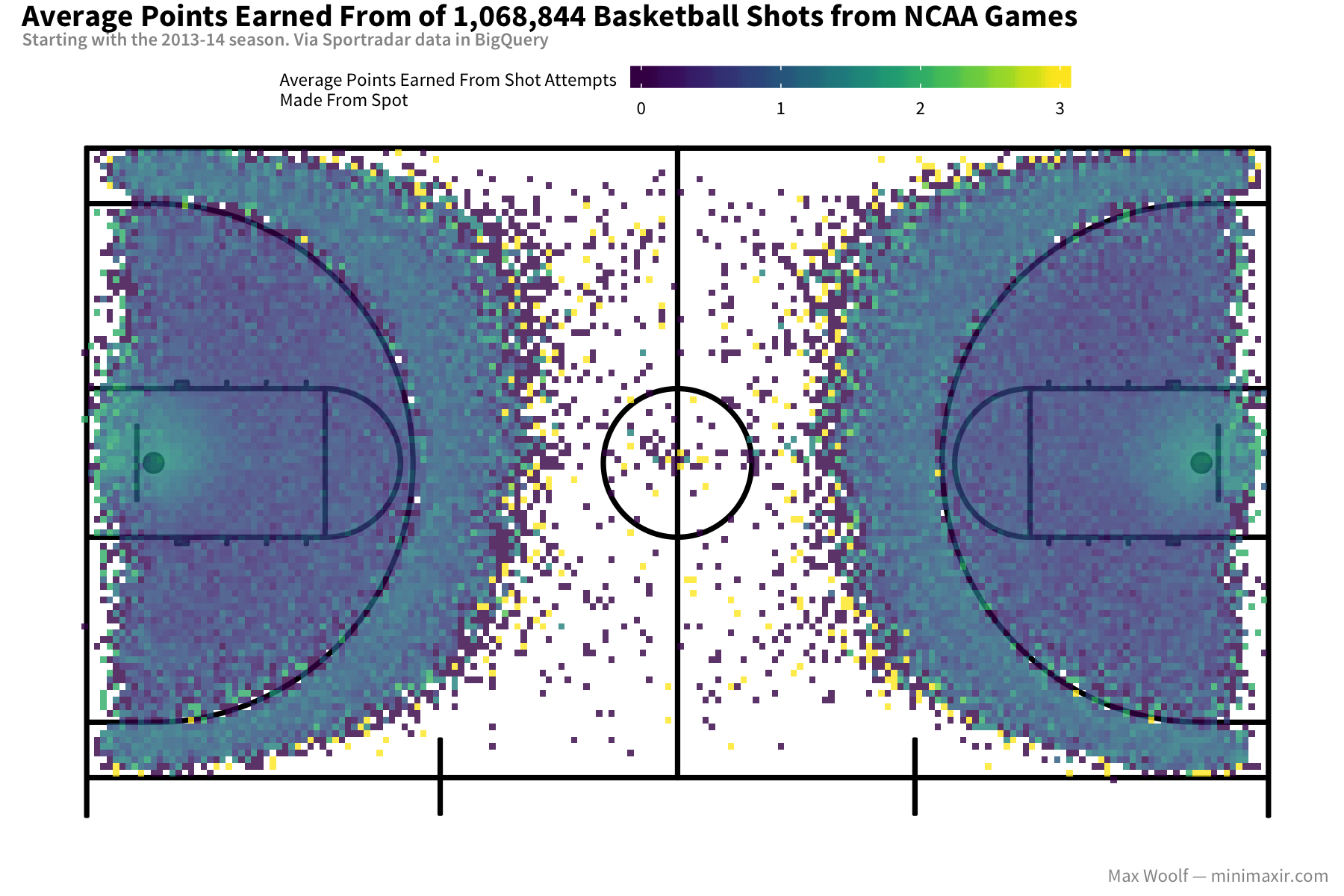
The average points earned for 3-pt shots is about 1.5x higher than many 2-pt shot locations in the inner court due to the equal accuracy, but locations next to the basket have an even higher expected value. Perhaps the accuracy of shots close to the basket is higher (>1.5x) than 3-pt shots and outweighs the lower point value?
Since both sides of the court are indeed the same, we can combine the two sides and just plot a half-court instead. (Cross-court shots, which many Redditors argued that they invalidated my visualizations above, constitute only 0.16% of the basketball shots in the dataset, so they can be safely removed as outliers).
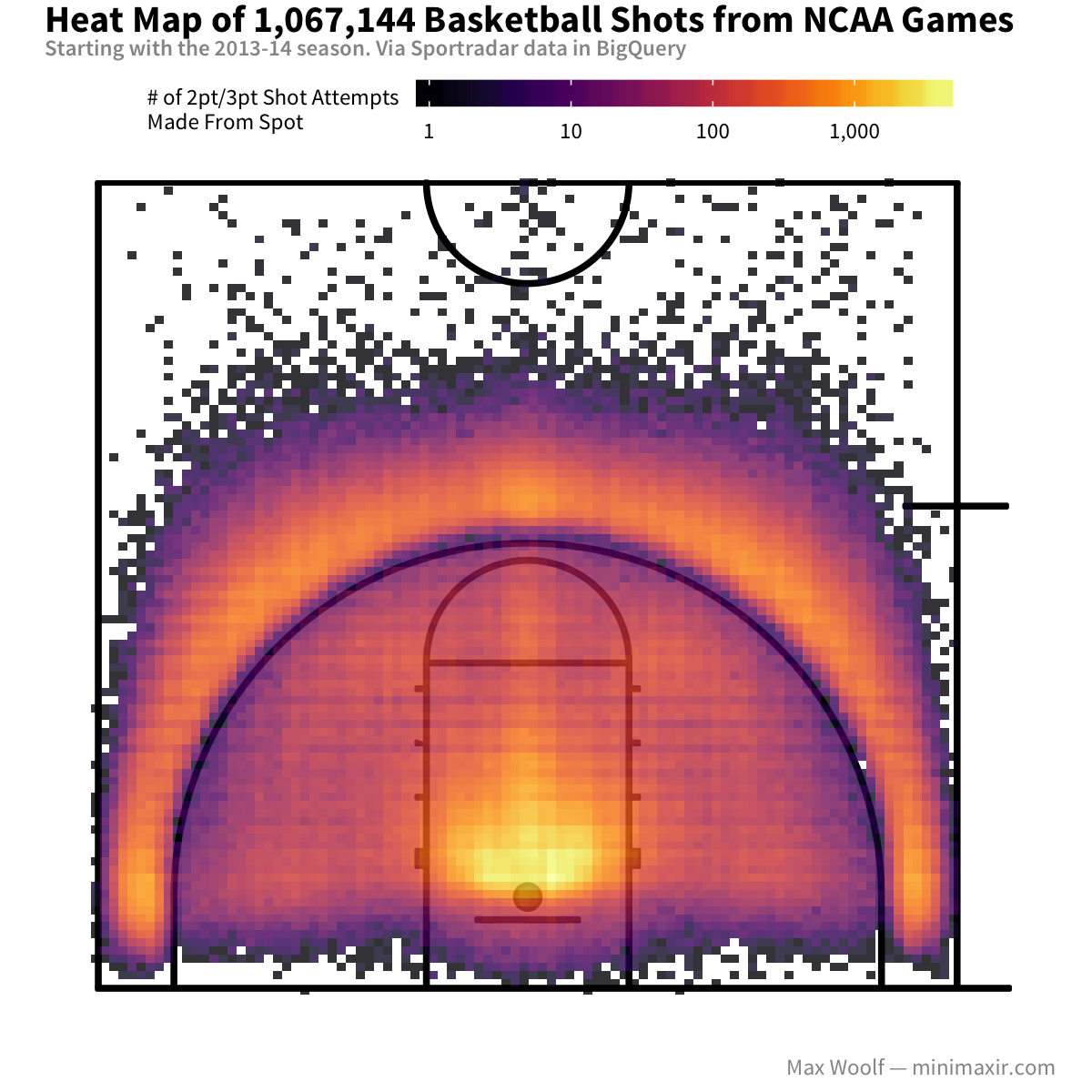
There are still a few oddities, such as shots being made behind the basket. Let’s drill down a bit.
Focusing on Basketball Shot Type
The Sportradar dataset classifies a shot as one of 5 major types: a jump shot where the player jumps-and-throws the basketball, a layup where the player runs down the field toward the basket and throws a one-handed shot, a dunk where the player slams the ball into the basket (looking cool in the process), a hook shot where the player close to the basket throws the ball with a hook motion, and a tip shot where the player intercepts a basket rebound at the tip of the basket and pushes it in.
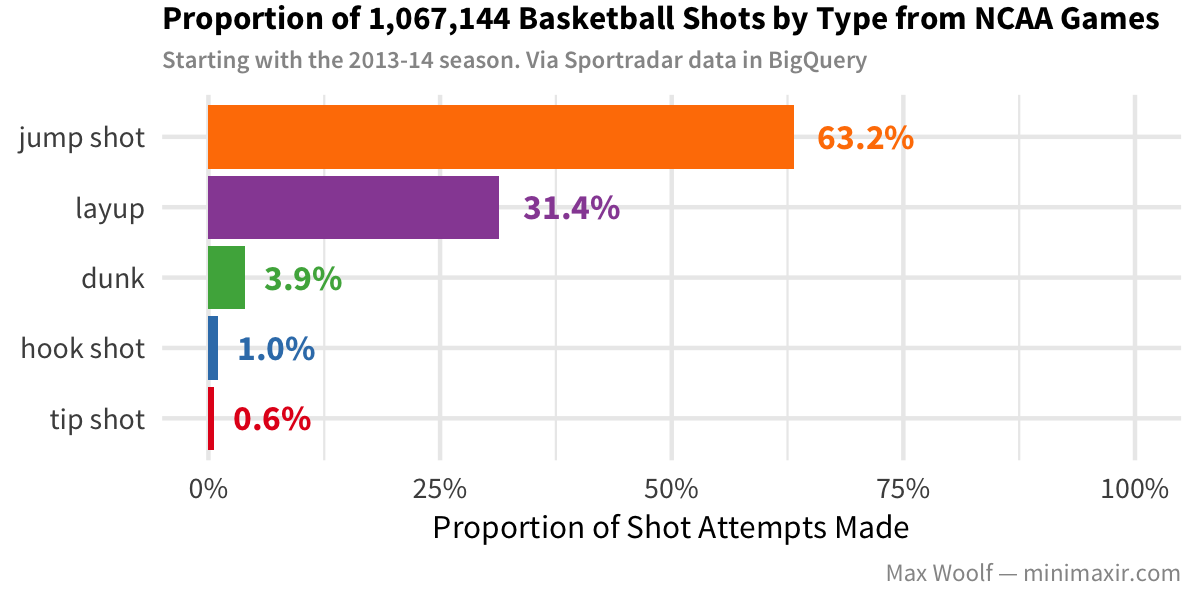
However, the most frequent types of shots are the less flashy, more practical jump shots and layups. But is a certain type of shot “better?”
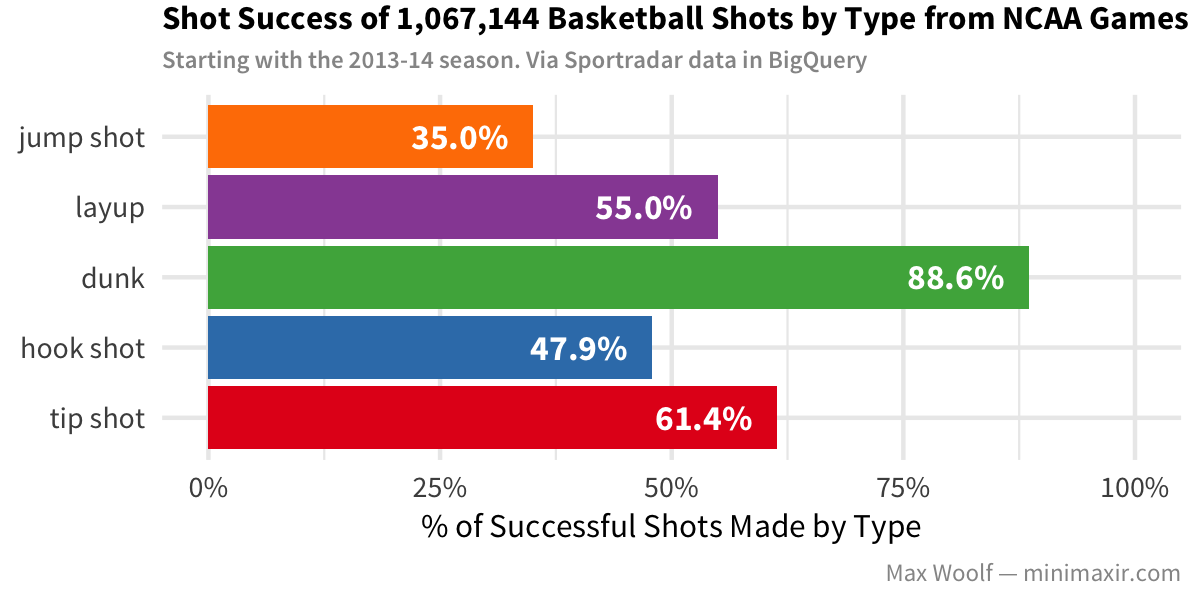
Layups are safer than jump shots, but dunks are the most accurate of all the types (however, players likely wouldn’t attempt a dunk unless they knew it would be successful). The accuracy of layups and other close-to-basket shots is indeed more than 1.5x better than the jump shots of 3-pt shots, which explains the expected value behavior above.
Plotting the heat maps for each type of shot offers more insight into how they work:
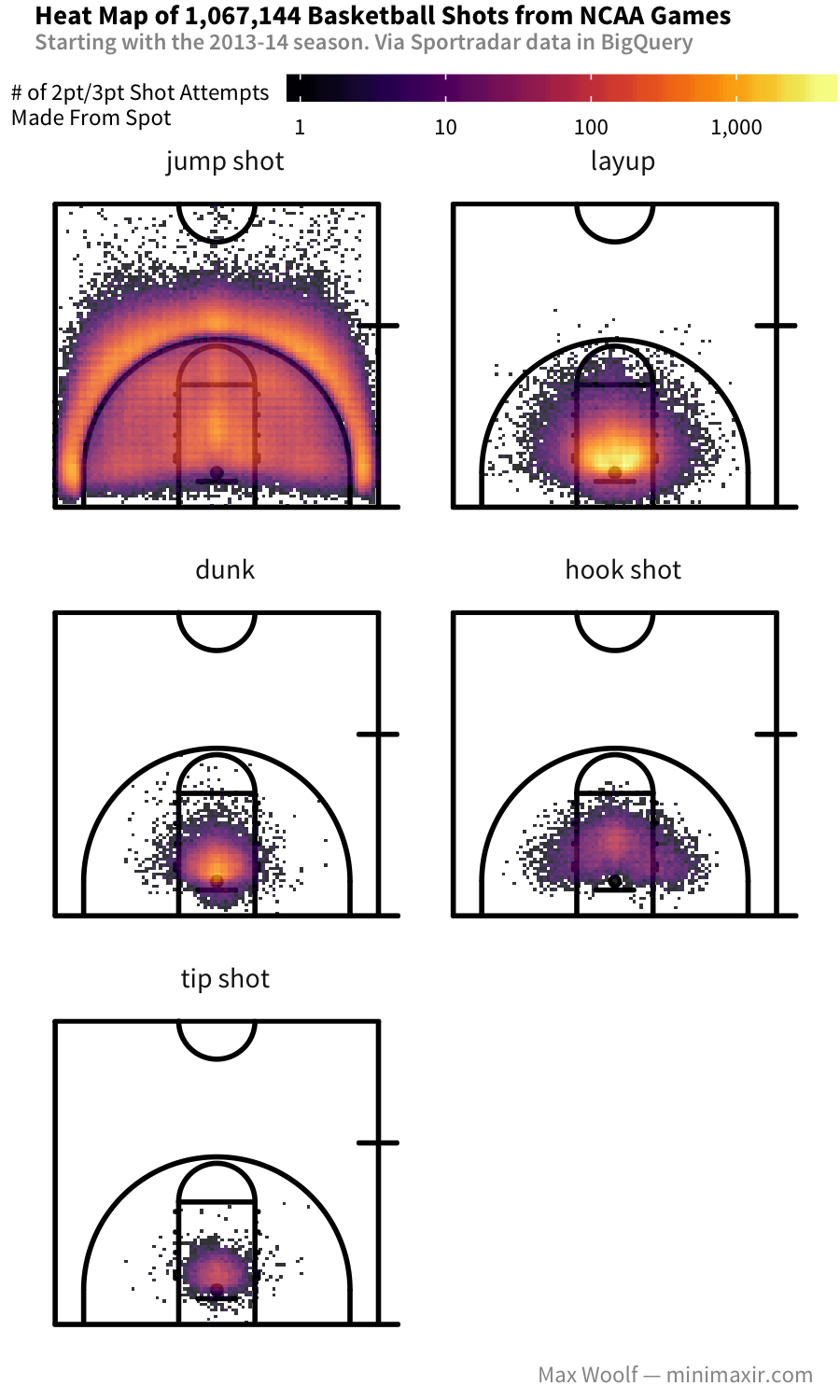
They’re wildly different heat maps which match the shot type descriptions above, but show we’ll need to separate data visualizations by type to accurately see trends.
Impact of Game Elapsed Time At Time of Shot
A NCAA basketball game lasts for 40 minutes total (2 halves of 20 minutes each), with the possibility of overtime. The example BigQuery for the NCAA-provided data compares the percentage of 3-point shots made during the first 35 minutes of the game versus the last 5 minutes: at the end of the game, accuracy was lower by 4 percentage points (31.2% vs. 35.1%). It might be interesting to facet these visualizations by the elapsed time of the game to see if there are any behavioral changes.
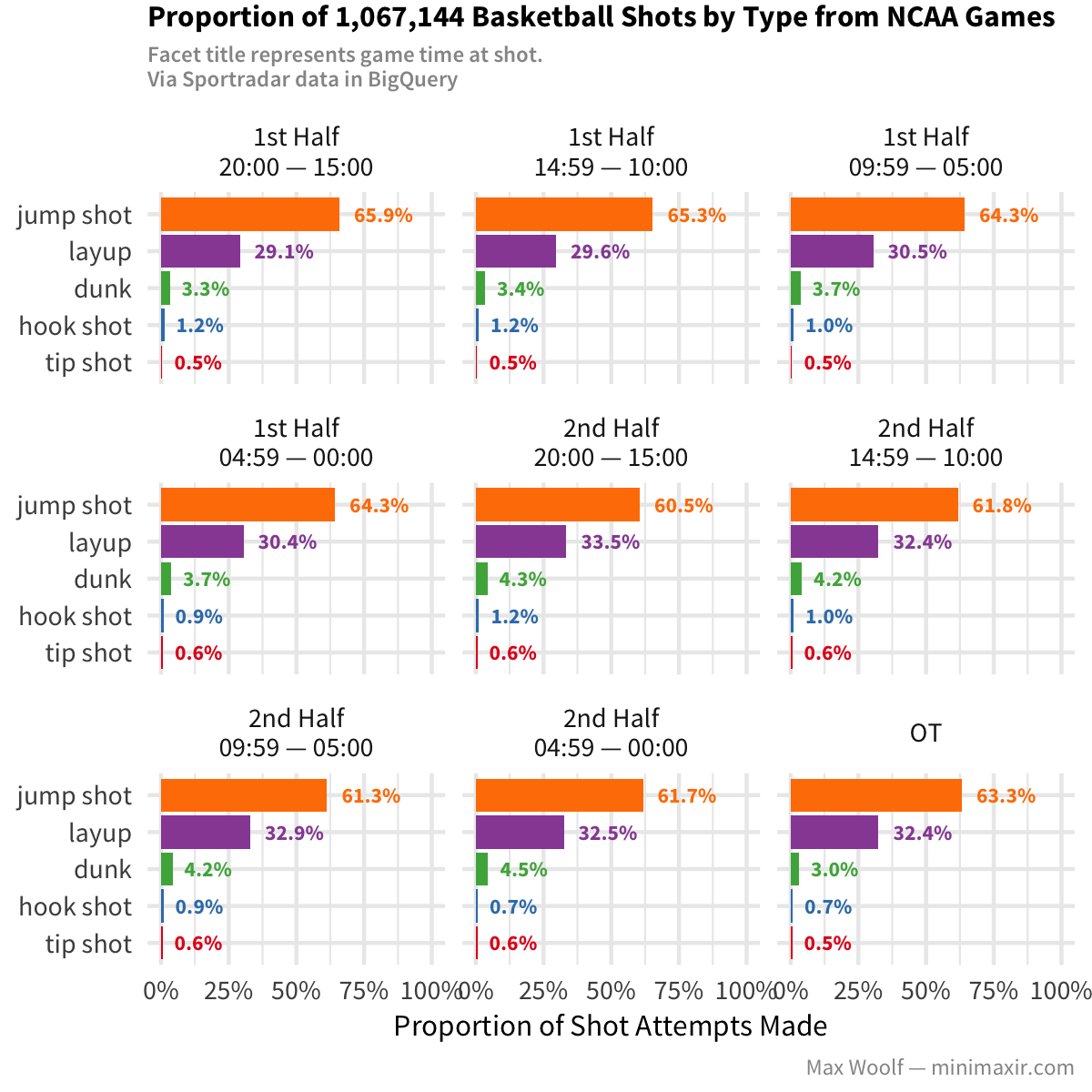
There isn’t much difference between the proportions within a given half, but there is a difference between the first half and the second half, where the second half has fewer jump shots and more aggressive layups and dunks. After looking at shot success percentage:
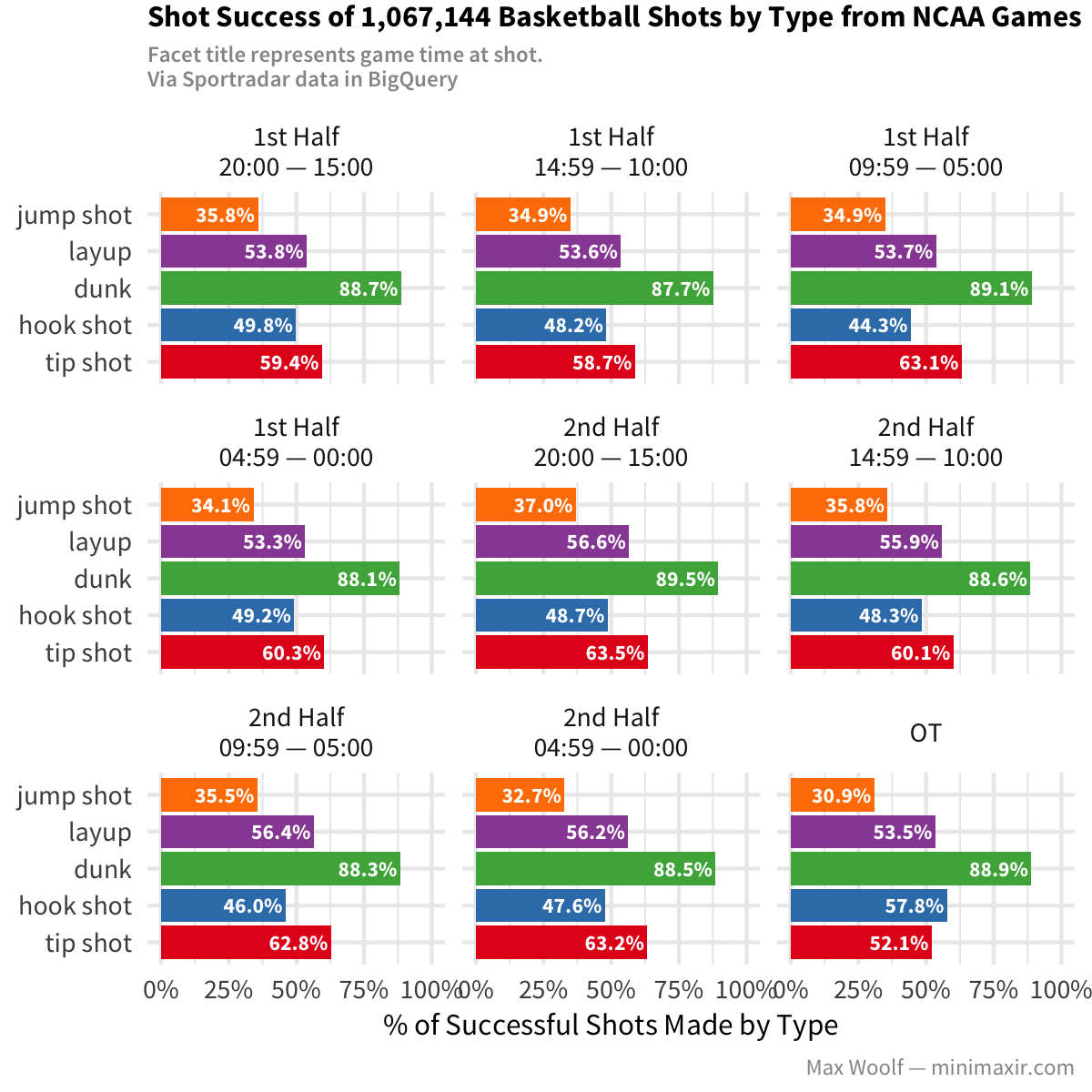
The jump shot accuracy loss at the end of the game with Sportradar data is similar to that of the NCAA data, which is a good sanity check (but it’s odd that the accuracy drop only happens in the last 5 minutes and not elsewhere in the 2nd half). Layup accuracy increases in the second half with the number of layups.
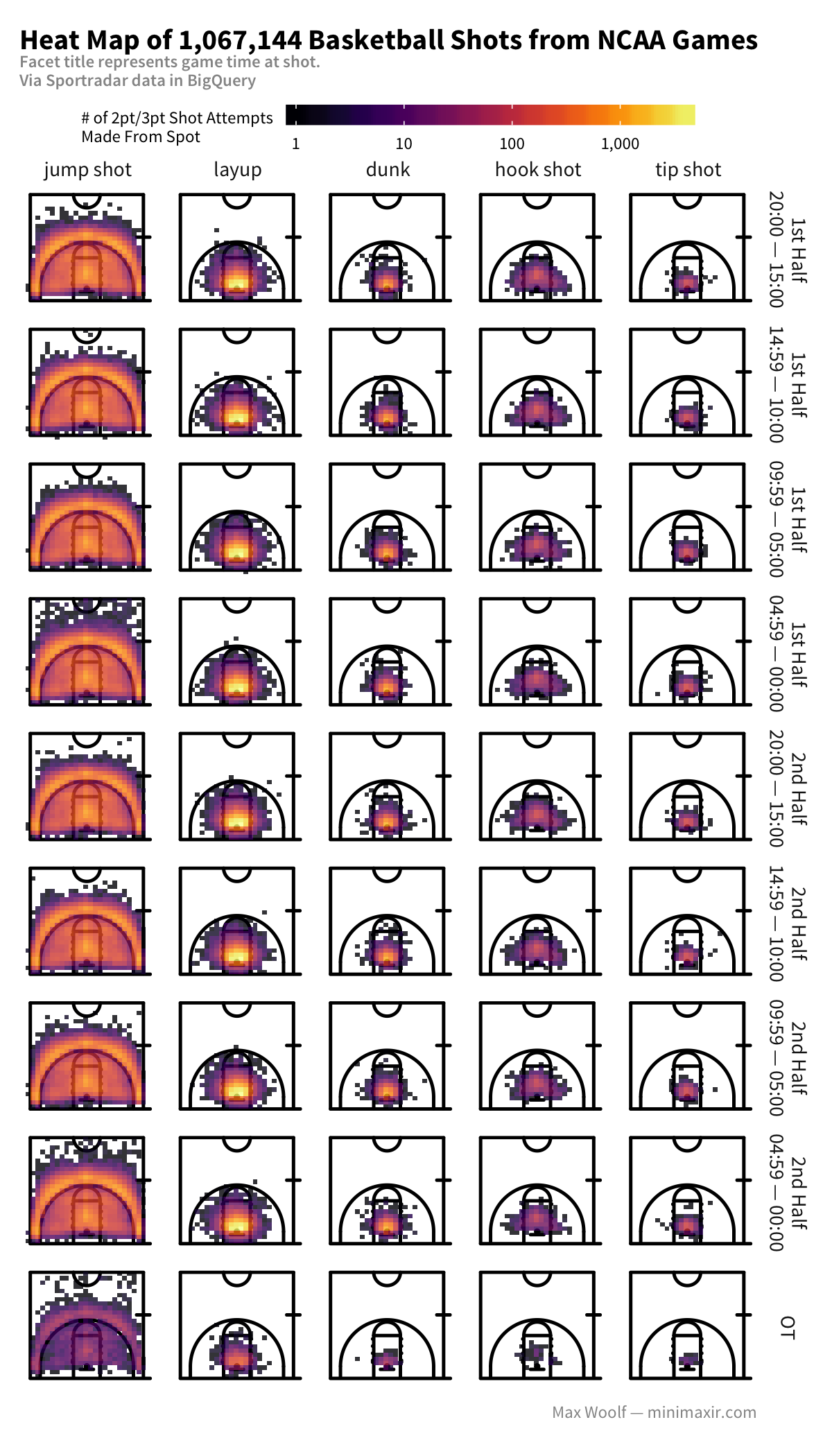
We can also visualize heat maps for each combo of shot type with time elapsed bucket, but given the results above, the changes in behavior over time may not be very perceptible.
Impact of Winning/Losing Before Shot
Another theory worth exploring is determining if there is any difference whether a team is winning or losing when they make their shot (technically, when the delta between the team score and the other team score is positive for winning teams, negative for losing teams, or 0 if tied). Are players more relaxed when they have a lead? Are players more prone to making mistakes when losing?
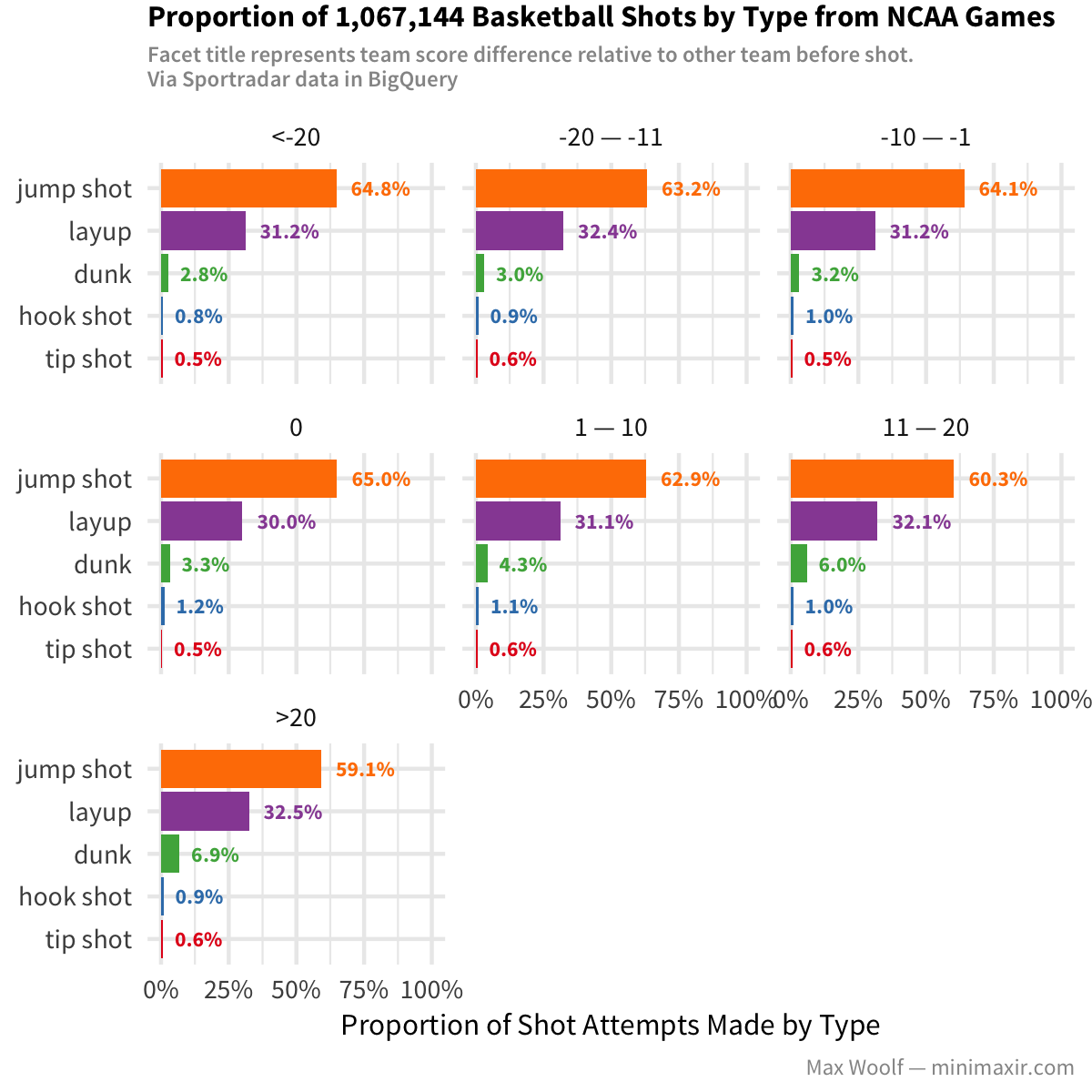
Layups are the same across all buckets, but for teams that are winning, there are fewer jump shots and more dunkin’ action (nearly double the dunks!). However, the accuracy chart illustrates an issue:
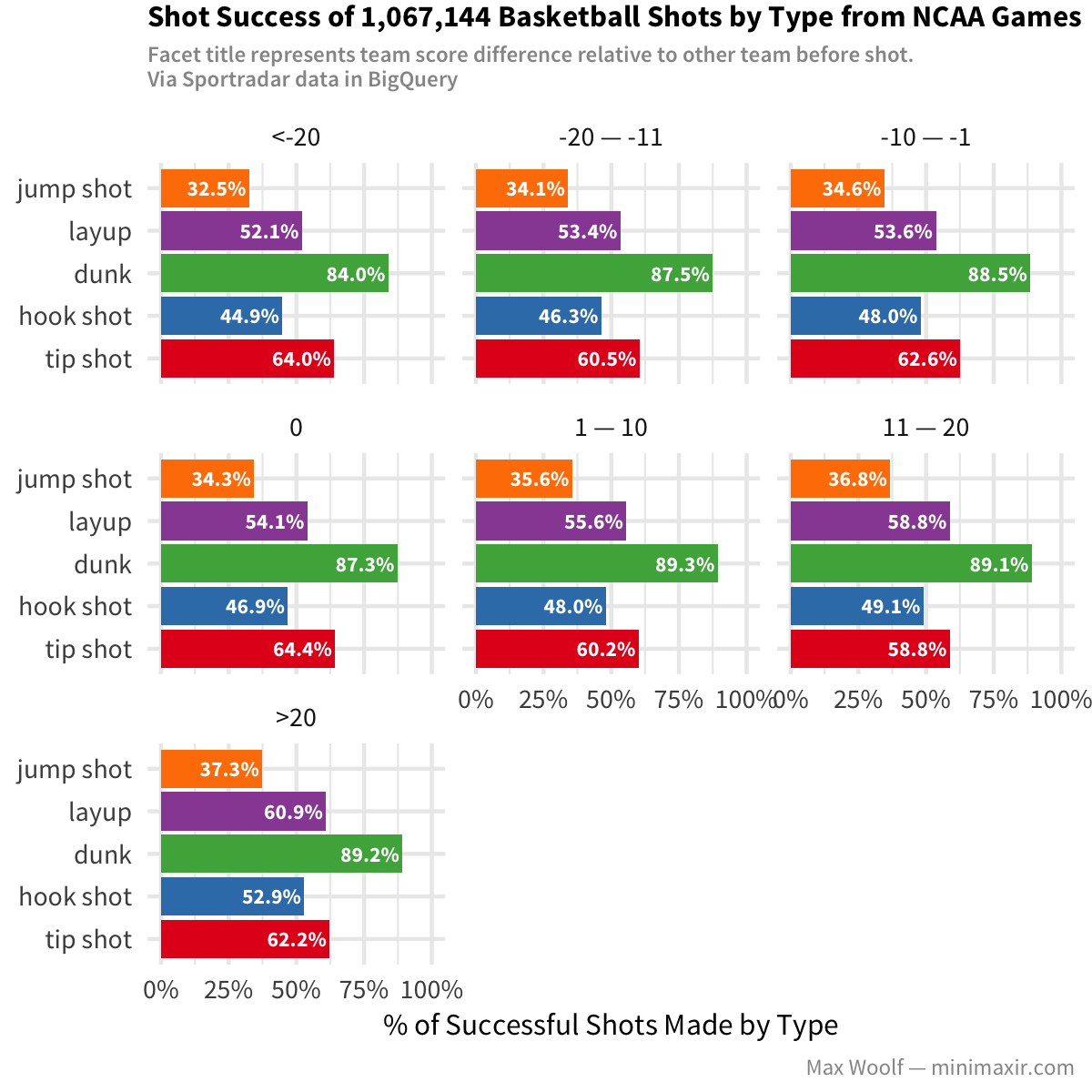
Accuracy for most types of shots is much better for teams that are winning…which may be the reason they’re winning. More research can be done in this area.
Conclusion
I fully admit I am not a basketball expert. But playing around with this data was a fun way to get a new perspective on how collegiate basketball games work. There’s a lot more work that can be done with big basketball data and game strategy; the NCAA-provided data doesn’t have location data, but it does have 6x more shots, which will be very helpful for further fun in this area.
You can view the R code, ggplot2 code, and BigQueries used to create the data visualizations in this R Notebook. You can also view the images/code used for this post in this GitHub repository.
You are free to use the data visualizations from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
Special thanks to Ewen Gallic for his implementation of a basketball court in ggplot2, which saved me a lot of time!
