Reddit threads can be a crowded place. In popular subreddits such as /r/AskReddit and /r/pics, Reddit submissions can receive hundreds, even thousands of unique comments. Some comments inevitably become lost in the noise. Reddit’s ranking algorithm attempts to rectify this by determining comment ranking using both time and community voting; comments in a thread, by default, are ordered based on the points score (upvotes - downvotes) the comment receives, subject to a rank decay based on the age of the comment.
In theory, this system should allow comments that posted later in the thread’s lifetime to rank much higher temporarily, then Redditors can vote on the new comment; if the new comment is good, it can now rise to the top and therefore the content which would otherwise be buried is now surfaced. Anecdotally, that doesn’t be the case with Reddit’s modern algorithm; comments made late in the thread appear at the bottom, where they likely will not receive any upvotes (this led to a minor “I know I’m late to this thread but…” meme).
I, of course, am not satisfied with anecdotes. A month ago, a Redditor asked “What percentage of the top comment in threads were also the first comment?” Why not calculate it exactly using big data?
Getting the Reddit Data
You can view all the R and ggplot2 code used to query, analyze, and visualize the Reddit data in this R Notebook.
In order to process a great amount of Reddit data, I turned to BigQuery, which now has data for all Reddit comments until September 2016.
For this analysis, I will only look at the top-level comments (i.e. comments which are not replies to other comments), since those are the ones most affected by the ordering and submission of new comments. Additionally I will only look at comments within Reddit threads with atleast 30 top-level comments to ensure I only look at threads with sufficient discussion and where late posts are more likely to become hidden. It also mirrors the “late to this thread” meme: can posts be too late?
The queried data will be all comments posted from January 2015 to September 2016: this give a good balance of sample size and foundation around the modern comment ranking algorithms. The total number of Reddit comments analyzed, after filtering on threads with sufficient conversation and limiting the scope to the first 100 comments of a thread scoring within the Top 100, is n = 86,561,476.
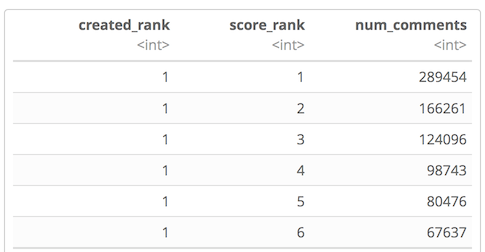
With clever use of BigQuery window functions, I obtained the aggregate data, counting the number of comments from the filtered Reddit threads at each voting rank and created rank.
Visualizing the Discussion
Filtering on the top-voted comments (score_rank = 1) only, what percent of the top-voted comments in Reddit threads were also 1st Comment?
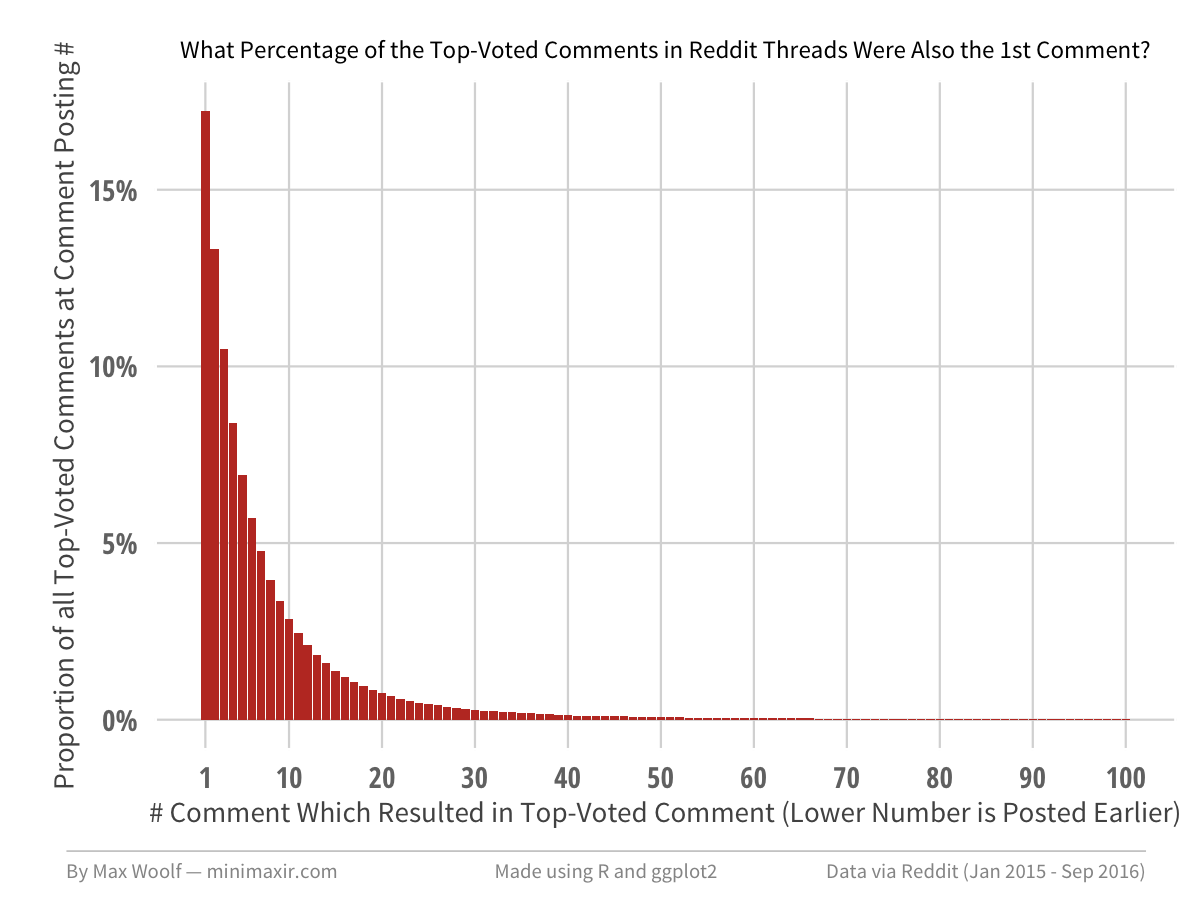
The answer is 17.24% of all top-voted comments! That’s certainly more than what I expected! Additionally, 56% of the top-voted comments were posted within the first 5 comments, and 77% within the first 10 comments. The chart follows a power-law distribution.
Let’s invert it: filtering on only the first comments (created_rank = 1) made in comment threads, what percentage of the 1st Comments in Reddit threads were also the top-voted comment?
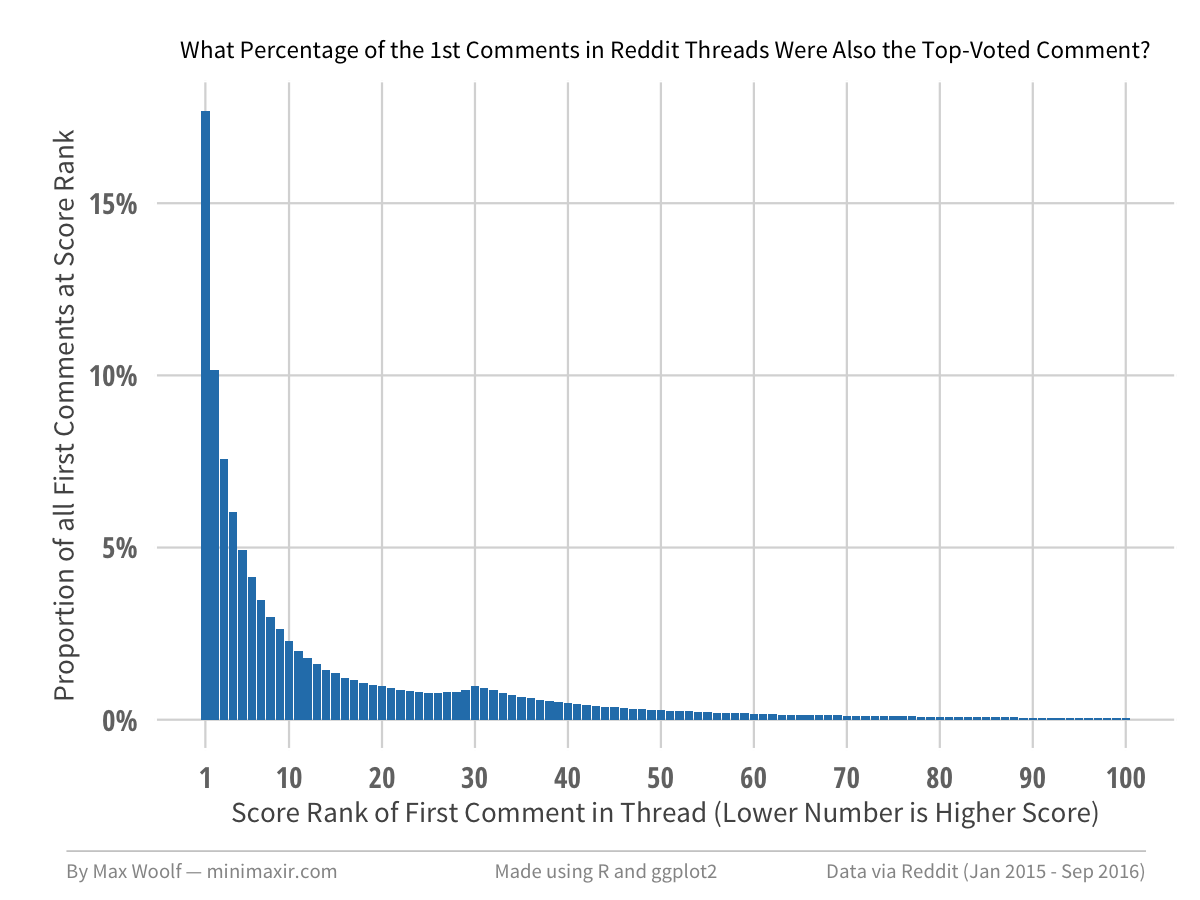
By construction, the answer is the same as before (17.24%), however the followup proportions are slightly different, with the first comment ranking within the Top 5 comments 46% of the time, and within the Top 10 comments 62% of the time.
It may be worth it to visualize both dimensions at the same time using a heatmap, with the created rank on one axis, score rank on the other, and a z-axis representing the number of comments at each rank pairing. We can also add a faint contour line to help visualize clusters of the data. Putting it together:
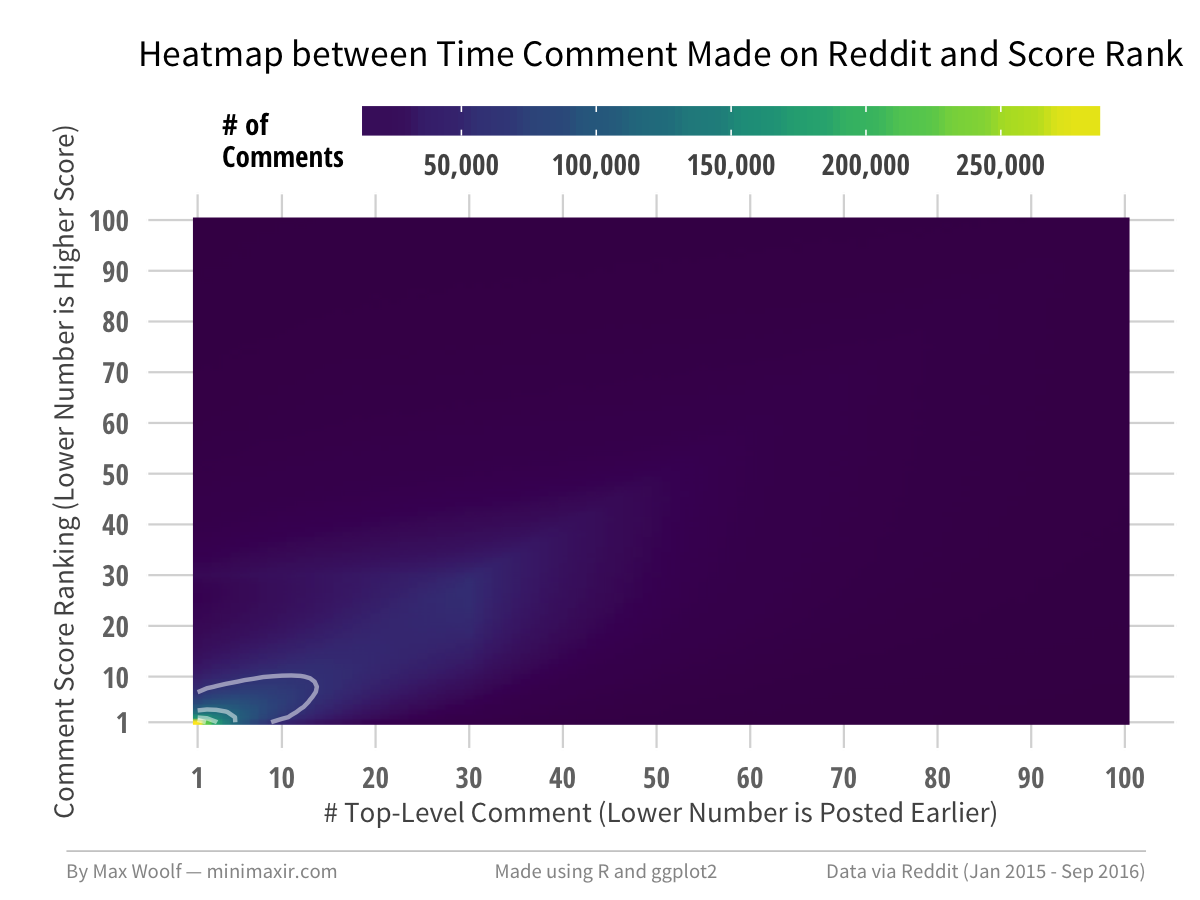
Woah, most of the values are constrained between the semisquare constrained by the first 5 comments and the top 5 comments! But it’s harder to see trends, so let’s try applying a logarithmic base-10 scaling on the comment count:
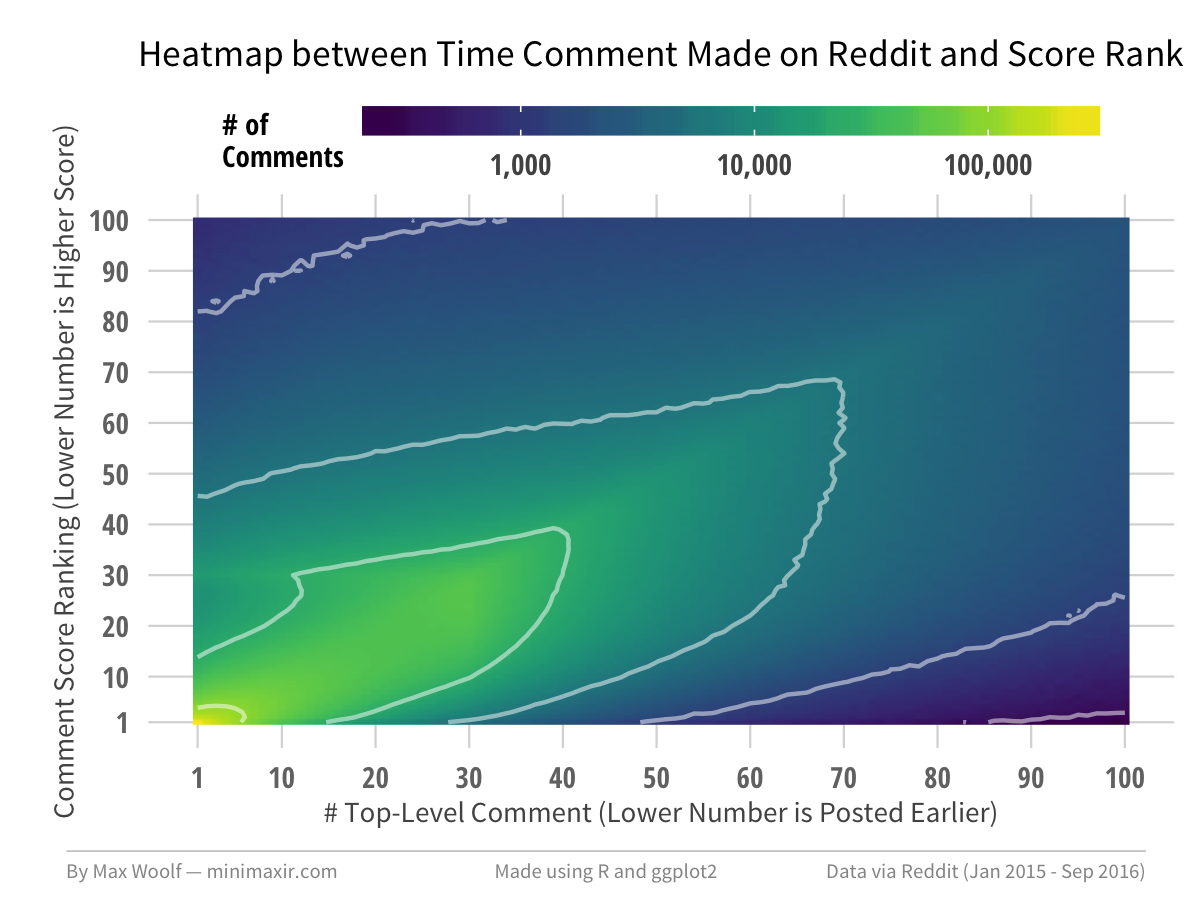
Much better! We can see a grouping of the 5x5 semisquare, but also smaller groupings of a 30x30 shape (this may possibly be due to the 30 comment filter threshold), a faint 60x60 shape, and voids in the upper-left and lower-right corners.
From the 2D heatmap, there appears to be a positive correlation between the rank of the comment and the time it was submitted. Ideally, if Reddit’s algorithm correctly cycled posts so that each comment gets a fair chance at going viral, then there should be no correlation between score rank and time posted.
Analysis by Subreddit
When working with Reddit data, it is always important to facet the analysis by subreddit, as subreddits can have idiosyncratic behaviors which deviate from general Reddit behavior. As noted in the original Reddit thread with the initial question, it is possible that the percentage of first comments becoming top comment is “higher in lighter subs (funny, pics, videos) than more serious subs (askscience, history, etc).”
I tweaked the BigQuery above to retrieve the same data for each of the Top 100 subreddits (determined by unique commenter count over the same time period). Afterward, via scripting, I created a 1D proportion-of-first-comments-by-score-rank and 2D heatmaps for each subreddit. You can view and download the 1D charts here, and the 2D heatmaps here.
For example, here’s the chart of first-comment-rankings for /r/IAmA, one of Reddit’s biggest subreddits where normal Redditors can ask celebrities any question they want.
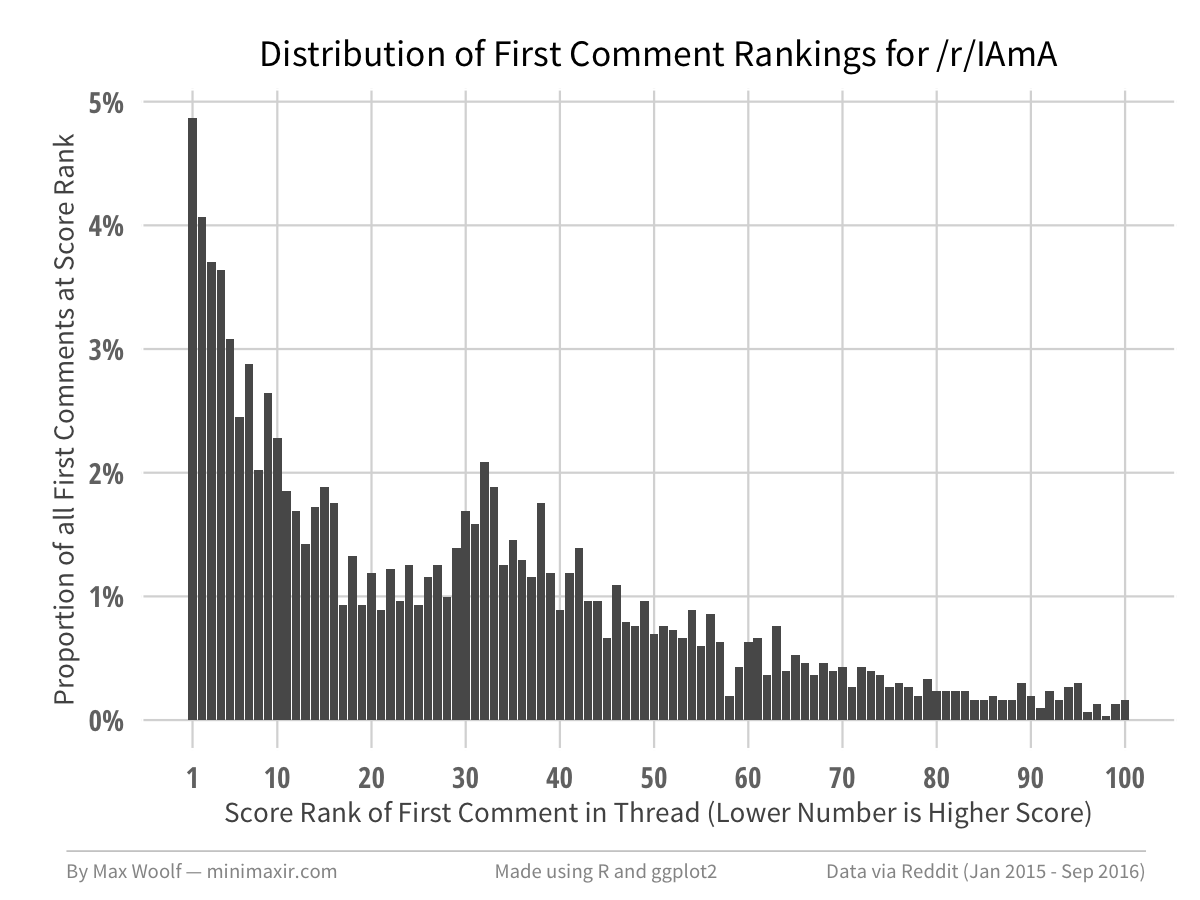
Unlike the all-Reddit chart, the distribution of first-comment proportions is more uniform instead of following a power law. It makes sense in theory; people would likely upvote top-level questions which the original poster replied to, so there should be less of a bias toward the first top-level comment.
What does the 2D heatmap show?
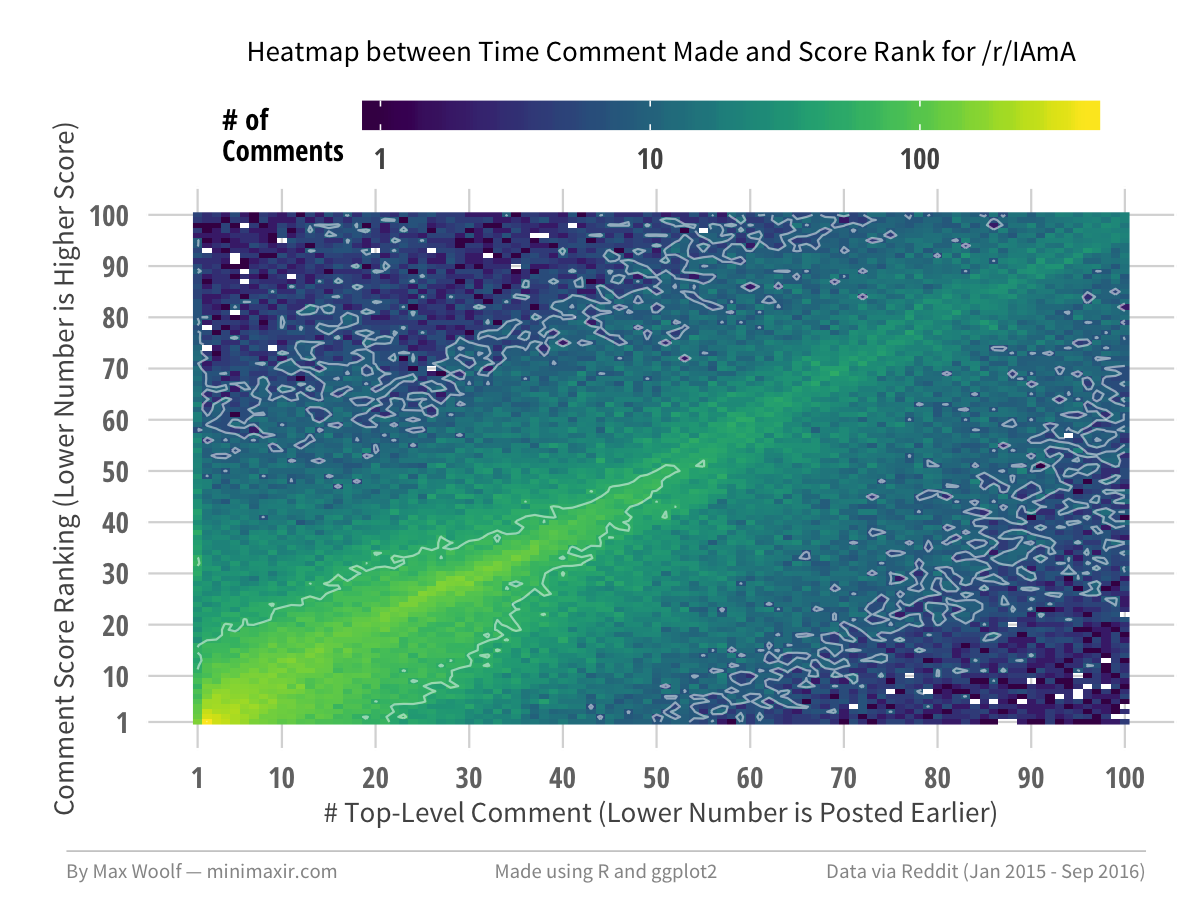
Damn it.
While the 1D behavior is different, the overall 2D behavior is the same albeit with larger voids (indeed, in the heatmap, you can see at created_rank = 1, the vertical strip doesn’t fit the pattern).
It turns out that most /r/IAmA threads have this comment:
As it’s made by a robot, it’s always the first comment, and it gets ignored/downvoted in normal circumstances. Other subreddits with the same pattern of 1D irregularities, 2D regularities, and AutoModerator usage are /r/gameofthrones, /r/photoshopbattles, and /r/WritingPrompts.
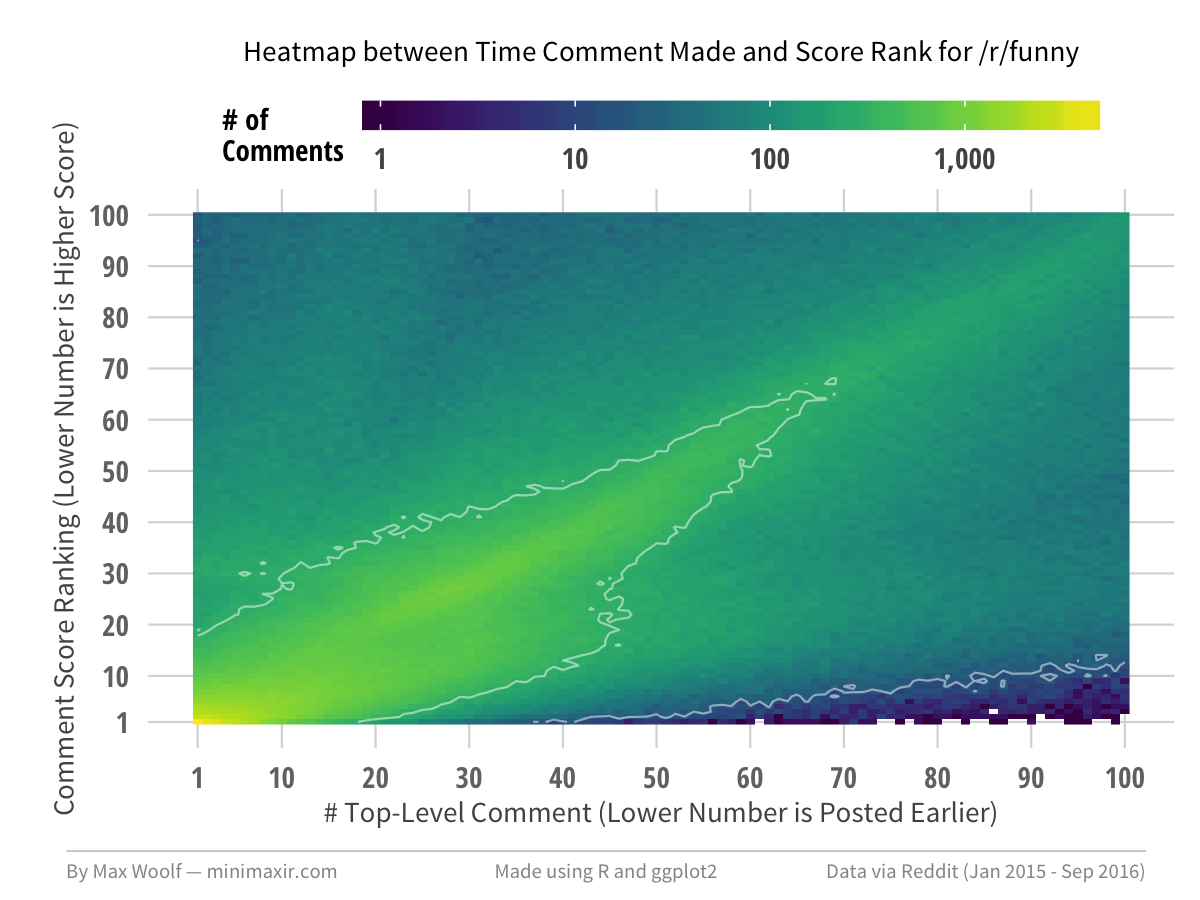
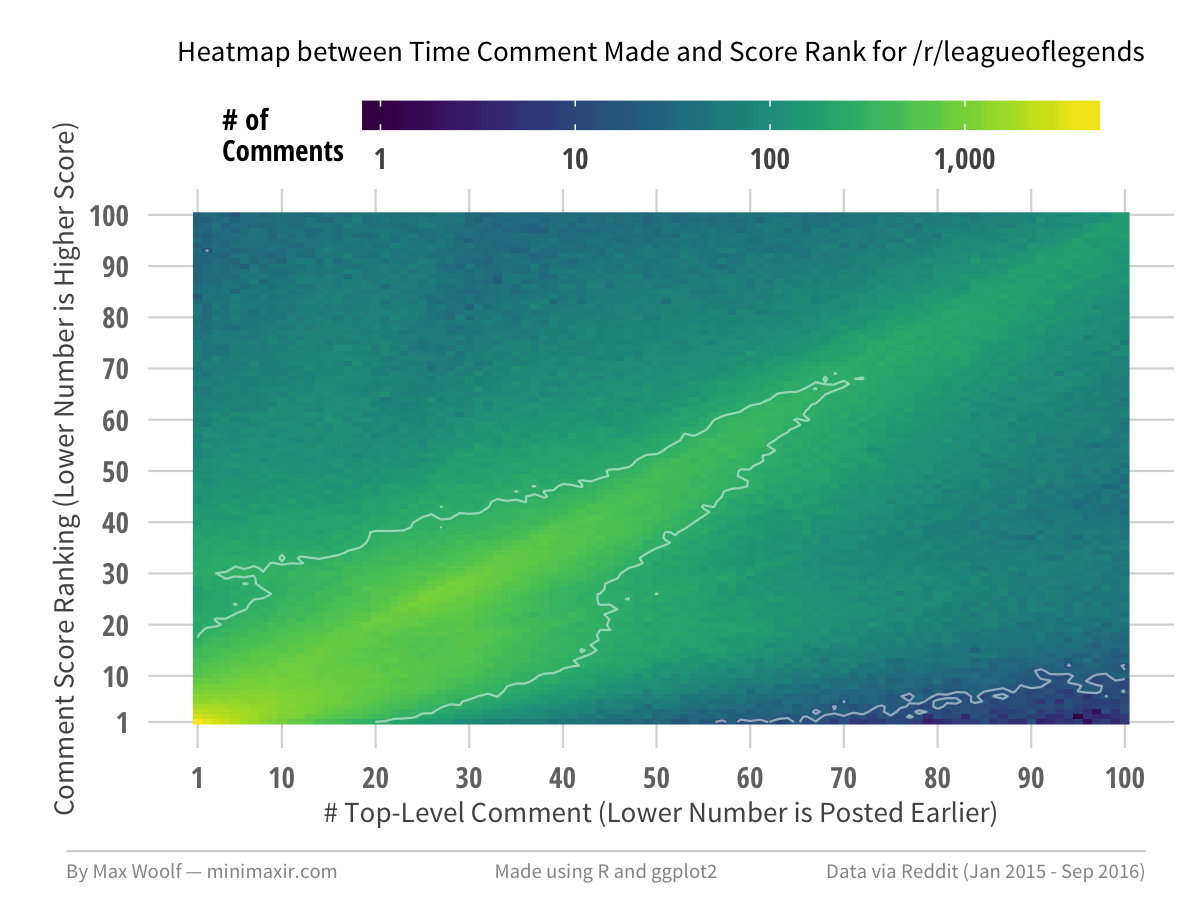
Some subreddits have more uniformity than typical Reddit rank behavior. In /r/funny, /r/leagueoflegends, /r/pics, /r/todayilearned, and /r/videos (i.e. many default subreddits), there is no upper-left void (early comments can be poorly ranked) and the bottom-right void is minimized but still present.
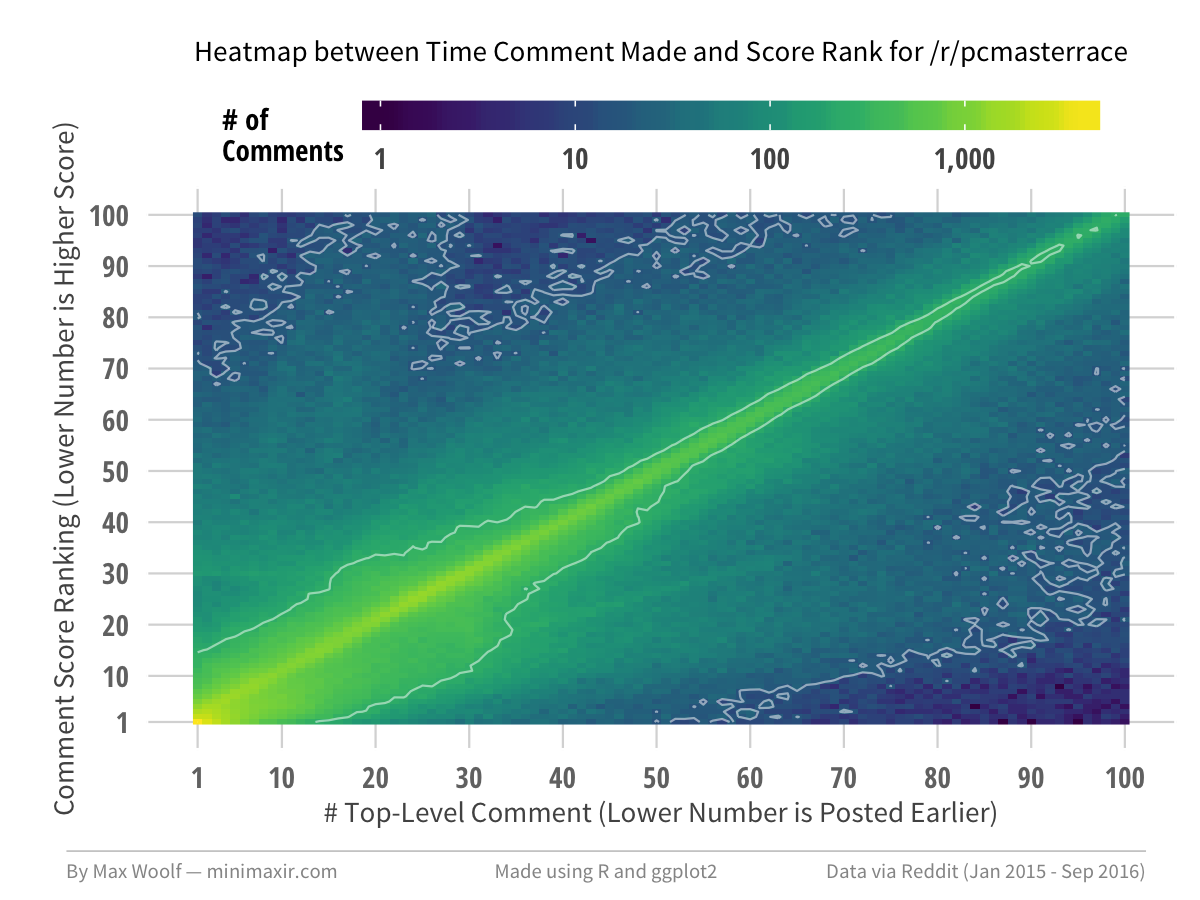
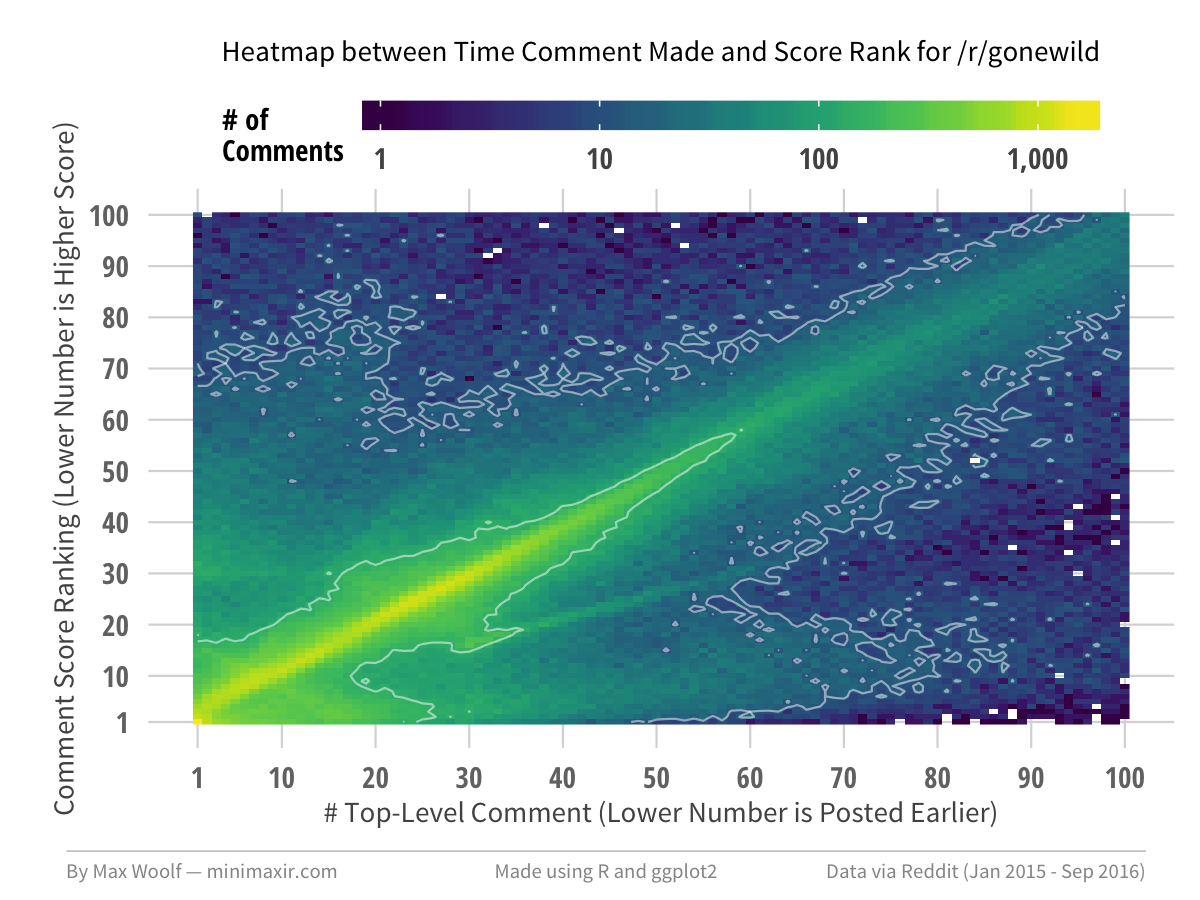
Inversely, there are subreddits where the correlation is obvious. /r/pcmasterrace and /r/gonewild both exhibit very straight lines, and are subreddits where the comments themselves are not very constructive, so whatever gets posted gets upvoted anyways.
Rushing to say FIRST!!1!11! in a comments section of a blog post or forum thread is a meme that long predates Reddit. However, rushing to make the first comment in a Reddit thread may have strategic merit if you want to get your voice heard.
Even in the most optimistic circumstances, comments that are late to a thread have a very, very low probability of becoming one of the top comments. In fairness, it’s hard to determine with public Reddit data if tweaking the ranking algorithm such that new comments will always rank at the top initially will actually improve the Reddit user experience as a whole. On the other hand, this behavior presents an opportunity: if there is a long tail of Reddit content that is unjustifiably being buried due to lack of attention, then perhaps there is a business opportunity in creating a service to discover and resurface quality comments…
You can view all the R and ggplot2 code used to query, analyze, and visualize the Reddit data in this R Notebook. You can also view the images/data used for this post in this GitHub repository.
You are free to use the data visualizations from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
