The SF OpenData portal is a good source for detailed statistics about San Francisco. One of the most popular datasets on the portal is the SFPD Incidents dataset, which contains a tabular list of 1,842,050 reports (at time of writing) from 2003 to present.

The data can be exported into a 377.9 MB CSV; not large enough to be considered “big data,” but still too heavy for programs like Excel to process efficiently. Let’s take a look at the data using R and see if there’s anything interesting.
Processing the Data
For this article, I’m going to do something different and illustrate the data processing step-by-step, both as a teaching tool, and to show that I am not using vague methodology to generate a narratively-convenient conclusion. For more detailed code and output, a Jupyter notebook containing the code and visualizations used in this article is available open-source on GitHub.
Loading a 1.9 million row file into R can take awhile, even on modern computers with a SSD. Enter readr, another R package by ggplot2 author Hadley Wickham, which grants access to a read_csv() function that has nearly 10x the speed of the base read.csv() R function, with more sensible defaults too.
path <- "~/Downloads/SFPD_Incidents_-_from_1_January_2003.csv"
df <- read_csv(path)
In memory, the data set is 180.9 MB, and removing a few useless columns (e.g. IncidentNum) further reduces the size to 126.9 MB. Since there are many redundancies in the row data (e.g. only 10 distinct PdDistrict values), R can perform memory optimizations.
You may have noticed in the first article image that the text data in some of the columns is in ALL CAPS, which would look ugly if the text was used in a data visualization. We can create a helper function to convert a column of text values into proper case through the use of regular expression shenanigans.
proper_case <- function(x) {
return (gsub("\\b([A-Z])([A-Z]+)", "\\U\\1\\L\\2" , x, perl=TRUE))
}
Now we can do more through processing using dplyr, another Hadley Wickham R package. dplyr is a utility that makes R easier to use: it provides a new syntax that allows data manipulation with intuitive function names, the functions can be chained using the %>% operator for efficiency, and all data processing is significantly faster due to a C++ code base. (Fun fact: before the release of dplyr, I intended to quit using R for data analysis in favor of Python. Base R syntax is that difficult to use.)
In dplyr, mutate allows the creation and transformation of columns. We will transform the text columns by running the columns through the proper_case function earlier:
df <- df %>% mutate(Category = proper_case(Category),
Descript = proper_case(Descript),
PdDistrict = proper_case(PdDistrict),
Resolution = proper_case(Resolution))
After all that, the data looks like:
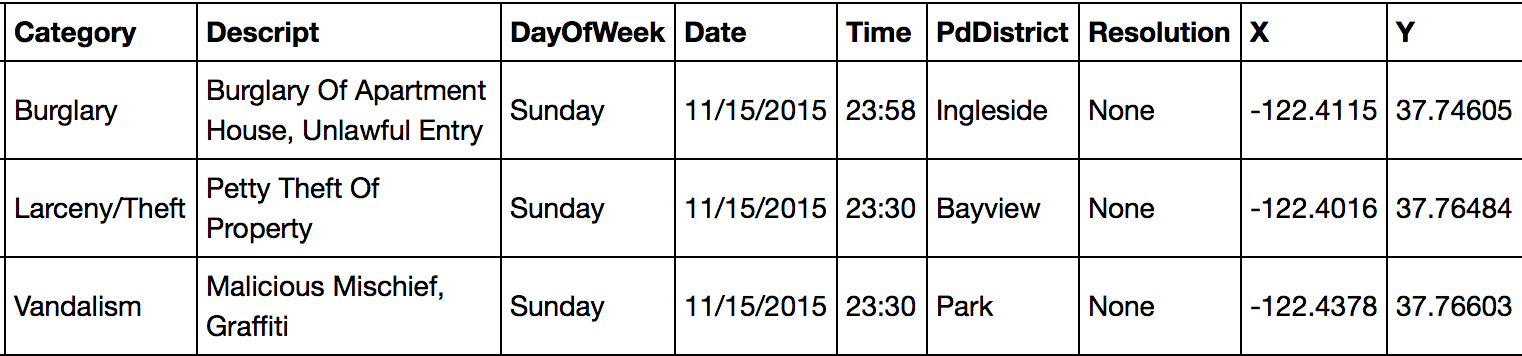
Much better!
However, many of the records have a “None” value for Resolution. This implies that the police appeared at the incident but did no action, which isn’t that helpful for analysis. How about we look at incidents which resulted in an arrest?
dplyr’s filter command does that, and we can use grepl() to do a text search for each Resolution value for the presence of “Arrest”.
df_arrest <- df %>% filter(grepl("Arrest", Resolution))
That’s it! There are 587,499 arrests total in the dataset.
Arrests Over Time
One of the most simple data visualizations is a line chart, and it’s a good starting point to use for analyzing arrests. Has the number of daily arrests been changing over time? dplyr and ggplot2 make this very easy to visualize in R.
First, the Date column must be formatted as a Date internally in R instead of text. Then we group_by the Date, and then use summarize to perform an aggregate on each group; in this case, count how many entries for the group. (n() is a convenient shortcut). We can also ensure that the dates are in ascending order.
df_arrest_daily <- df_arrest %>%
mutate(Date = as.Date(Date, "%m/%d/%Y")) %>%
group_by(Date) %>%
summarize(count = n()) %>%
arrange(Date)
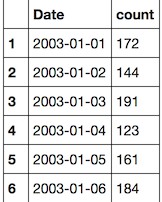
Nifty! However, keep in mind that there are thousands of days in this dataset.
Now we can make a pretty line chart in ggplot2. Here’s the code, and I will explain what everything does afterward:
plot <- ggplot(df_arrest_daily, aes(x = Date, y = count)) +
geom_line(color = "#F2CA27", size = 0.1) +
geom_smooth(color = "#1A1A1A") +
fte_theme() +
scale_x_date(breaks = date_breaks("2 years"), labels = date_format("%Y")) +
labs(x = "Date of Arrest", y = "# of Police Arrests", title = "Daily Police Arrests in San Francisco from 2003 – 2015")
ggplot()sets up the base chart and axes.geom_line()creates the line for the line chart. “color” and “size” parameters do just that.geom_smooth()adds a smoothing spline on top of the chart to serve as a trendline, which is helpful since there are a lot of points.fte_theme()is my theme based on the FiveThirtyEight style.scale_x_date()explicitly sets the x-axis to scale with date values. However, there are a few extremely useful formatting parameters with this function: “breaks” lets you set the chart breaks in plain English, and “labels” lets you format the dates at this breaks; in this case, there are breaks every 2 years, and only the year will be displayed for minimalism.labs()is a quick shortcut for labeling your axes and plot (always label!)
Running the code and saving the output results in this image:
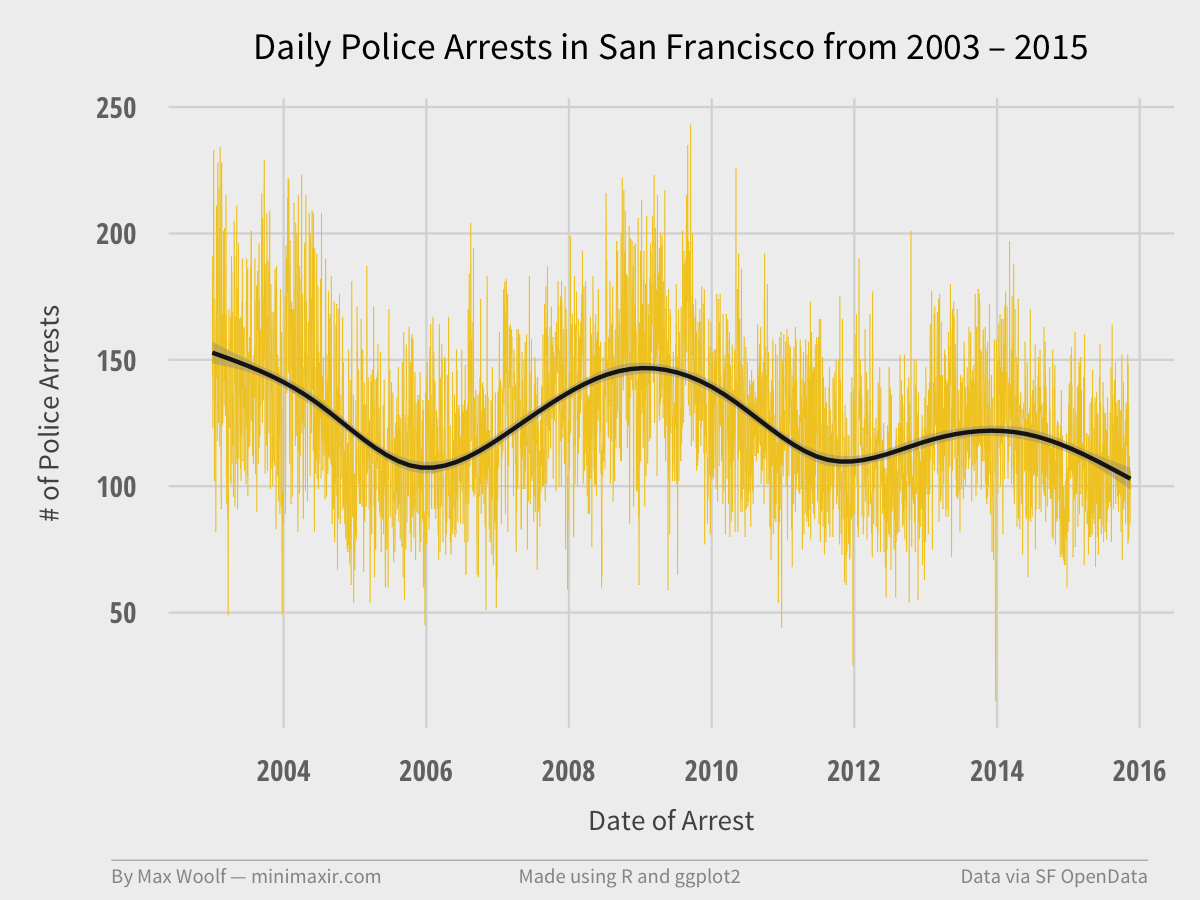
The line chart has high variation due to the number of points (in retrospect, a 30-day moving average of arrests would work better visually). As the trendline indicates, the trend is actually multimodal, with daily arrest peaks in 2009 and 2014. Definitely interesting. The number of arrests appears to be on a downward trend since then.
The next step is to look into possible answers for the day-by-day variation.
When Do Arrests Happen?
One of my go-to data visualizations is a heat map of times of week; in this case, we can find which day-of-week and time-of-day when the most Arrests occur in San Francisco, and compare that with other time slots at a glance.
This requires the Hour and Day-of-Week to be present in separate columns: we have a DOY column already, but we need to parse the Hour component out of the HH:MM values in the Time column.
This requires another helper function which uses strsplit() to split a single time value to Hour and Minute components, take the first value (Hour), and convert that value to a numeric value (instead of text) For example, “09:40” input returns 9.
get_hour <- function(x) {
return (as.numeric(strsplit(x,":")[[1]][1]))
}
Unfortunately, this will not work for an entire column. Using sapply() applies a specified function to each element in a column, which accomplishes the same goal.
The goal is to count how many Arrests occur for a given day-of-week and hour combination. In dplyr, we group_by both “DayOfWeek” and “Hour”, and then use summarize again.
df_arrest_time <- df_arrest %>%
mutate(Hour = sapply(Time, get_hour)) %>%
group_by(DayOfWeek, Hour) %>%
summarize(count = n())
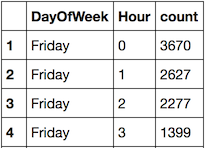
A few more tweaks are done (off camera) to convert the Hours to representations like “12 PM” and get everything in the correct order.
Now, it’s time to make the heatmap using ggplot2. Here’s the code, and I will explain what the new functions do:
plot <- ggplot(df_arrest_time, aes(x = Hour, y = DayOfWeek, fill = count)) +
geom_tile() +
fte_theme() +
theme(...) +
labs(x = "Hour of Arrest (Local Time)", y = "Day of Week of Arrest", title = "# of Police Arrests in San Francisco from 2003 – 2015, by Time of Arrest") +
scale_fill_gradient(low = "white", high = "#27AE60", labels = comma)
geom_title()creates tiles. (instead of lines)theme()is needed for a few additional theme tweaks to get the gradient bar to render (tweaks not shown)scale_fill_gradient()tells the tiles to fill on a gradient, from white as the lowest value to a green as the highest value. The “labels = comma” parameter is a hidden helpful tip to allow any values in the legend to show with commas.
Putting it all together:
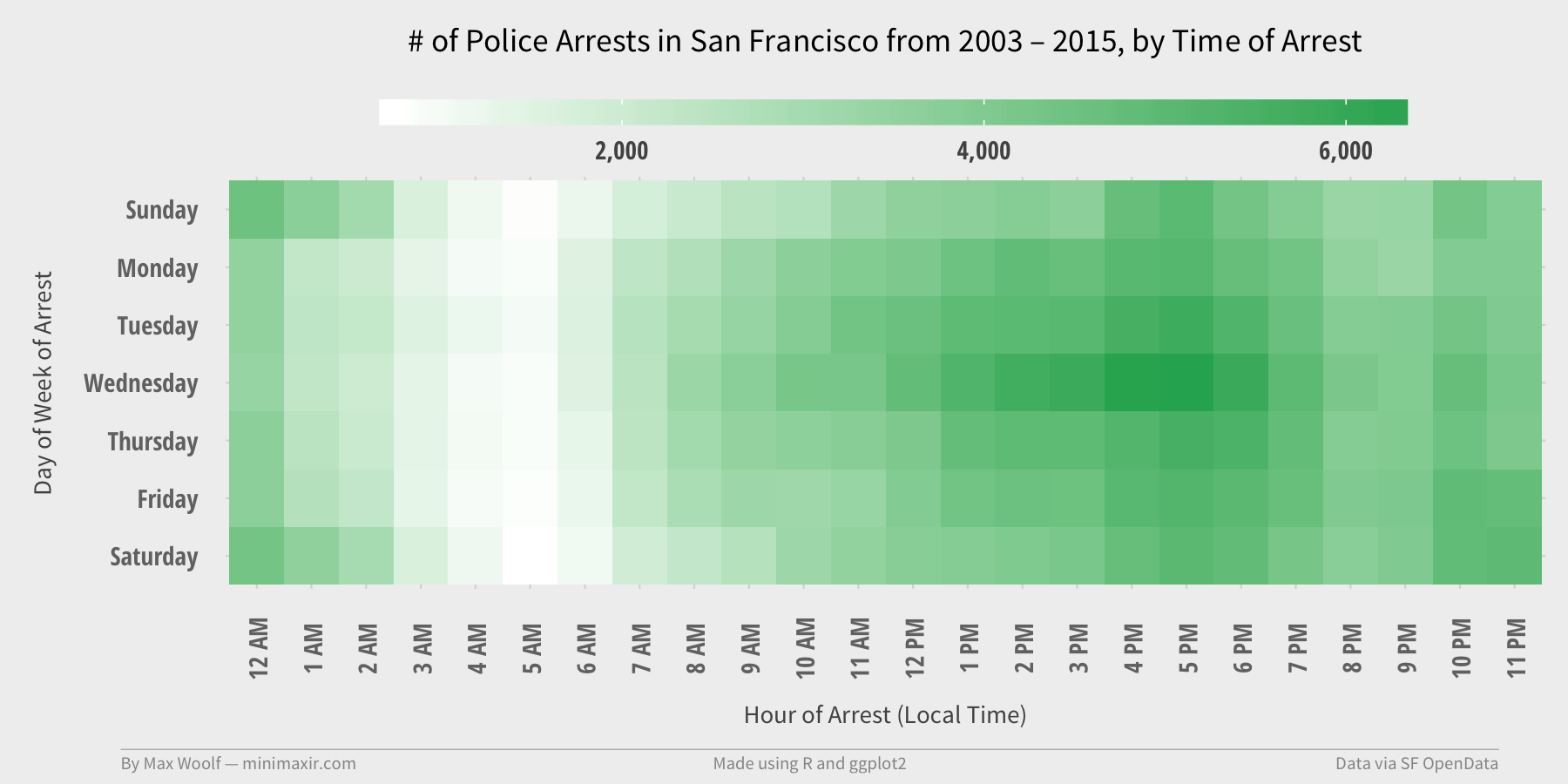
The heatmap is an intuitive result. Arrests don’t happen in the early morning, and arrests tend to be elevated Friday and Saturday night, when everyone is out on the town.
However, the peak arrest time is apparently on Wednesdays at 4-5 PM. Wednesdays and the 4-5 PM timeslot in general have elevated arrest frequency, too. Why is that the case?
This requires further analysis.
Facets of Arrest
Perhaps the odd results can be explained by another lurking variable. Logically, certain types of crime, such as DUIs, should happen primarily at night. ggplot2 has tool known as faceting that makes such analysis easy by rendering a chart for each instance of another value in another variable. In this case, with only one line of ggplot2 code, we can plot a heatmap for each of the top types of arrests, and see if there is any significant variation in the heatmap.
After quickly using dplyr to aggregate and sort the top categories of arrest, by number of occurrences:
df_top_crimes <- df_arrest %>%
group_by(Category) %>%
summarize(count = n()) %>%
arrange(desc(count))
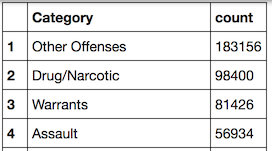
“Other Offenses” is a catch-all, so we will ignore that. Filter on the top 18 types of crime excluding Other Offenses and aggregate as usual.
df_arrest_time_crime <- df_arrest %>%
filter(Category %in% df_top_crimes$Category[2:19]) %>%
mutate(Hour = sapply(Time, get_hour)) %>%
group_by(Category, DayOfWeek, Hour) %>%
summarize(count = n())
Time for the heat map! The ggplot code is nearly identical to the previous heatmap code, except we add facet_wrap().
plot <- ggplot(df_arrest_time_crime, aes(x = Hour, y = DayOfWeek, fill = count)) +
geom_tile() +
fte_theme() +
theme(...) +
labs(x = "Hour of Arrest (Local Time)", y = "Day of Week of Arrest", title = "# of Police Arrests in San Francisco from 2003 – 2015, by Category and Time of Arrest") +
scale_fill_gradient(low = "white", high = "#2980B9") +
facet_wrap(~ Category, nrow = 6)

Easy visualization to make, but it’s not fully correct. There can only be one scale for the whole visualization, which is why the categories with lots of arrests appear colored and others do not (however, it shows that Drugs/Narcotics arrests are a large contributor to the Wednesday emphasis of the data). We need to normalize the counts by facet. dplyr has a nice trick for normalization: group by the normalization variable (Category), then mutate to add a column based on the aggregate for each unique value.
df_arrest_time_crime <- df_arrest_time_crime %>%
group_by(Category) %>%
mutate(norm = count/sum(count))
Setting the “fill” to “norm” and rerunning the heatmap code yields:
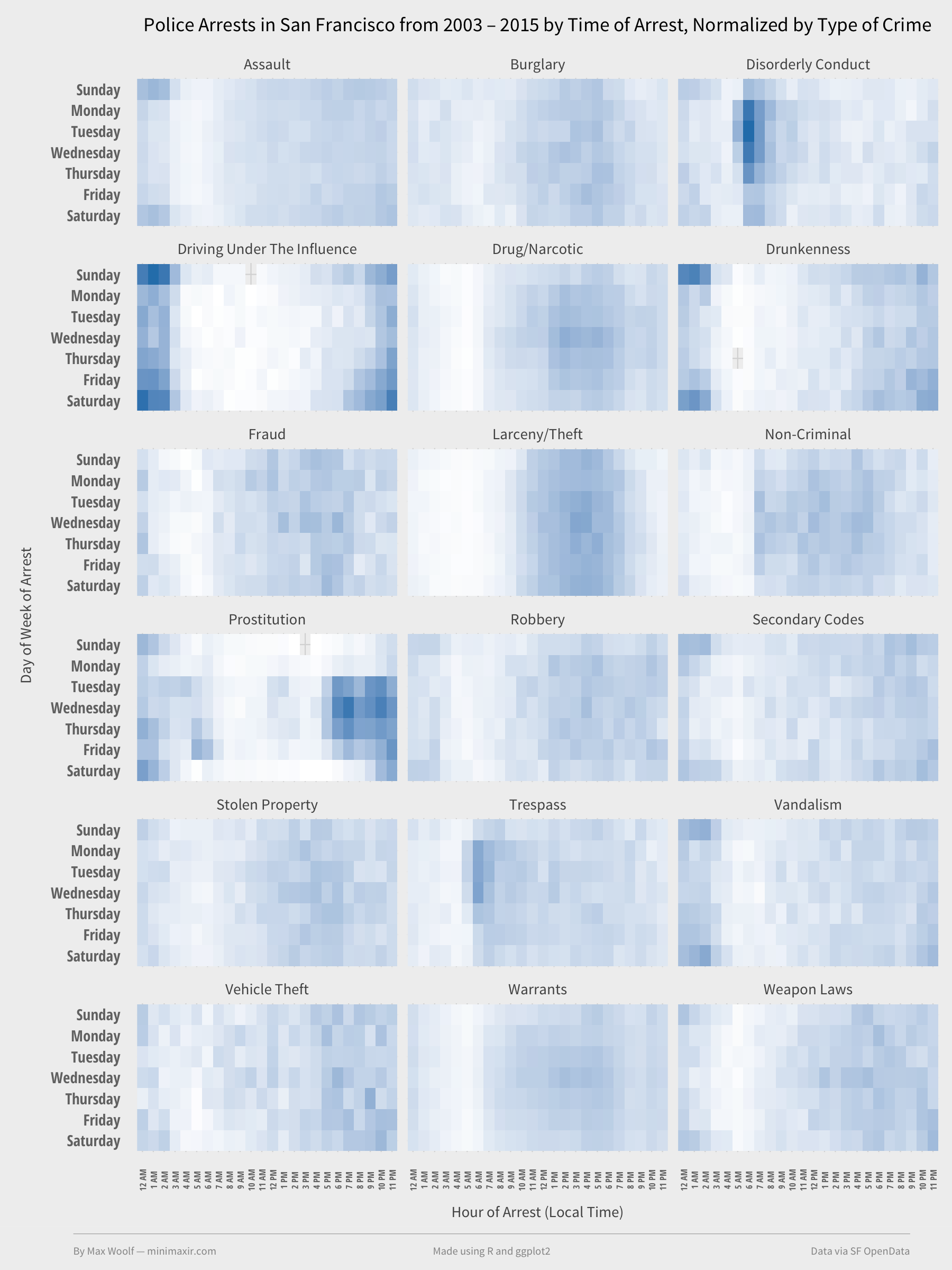
Now things get interesting.
Prostitution has the most notably unique behavior, which high concentrations of arrests at night on weekdays. Drunkenness and DUIs have high concentrations at night on weekends. And Disorderly Conduct has a high concentration of arrests at 5 AM on weekdays? That’s not intuitive.
Notably, some offenses have relatively random times of arrests, such as Stolen Property and Vehicle Theft.
However, this doesn’t help explain why arrests tend to happen Wednesdays/4-5PM. Maybe faceting by another variable will provide more information.
Perhaps Police district? Maybe some PDs in San Francisco are more zealous than others. Since we created a code workflow earlier, we can apply it to any other variable very easily; in this case, it’s mostly just replacing instances of “Category” with “PdDistrict.”
Doing thus yields this heatmap.
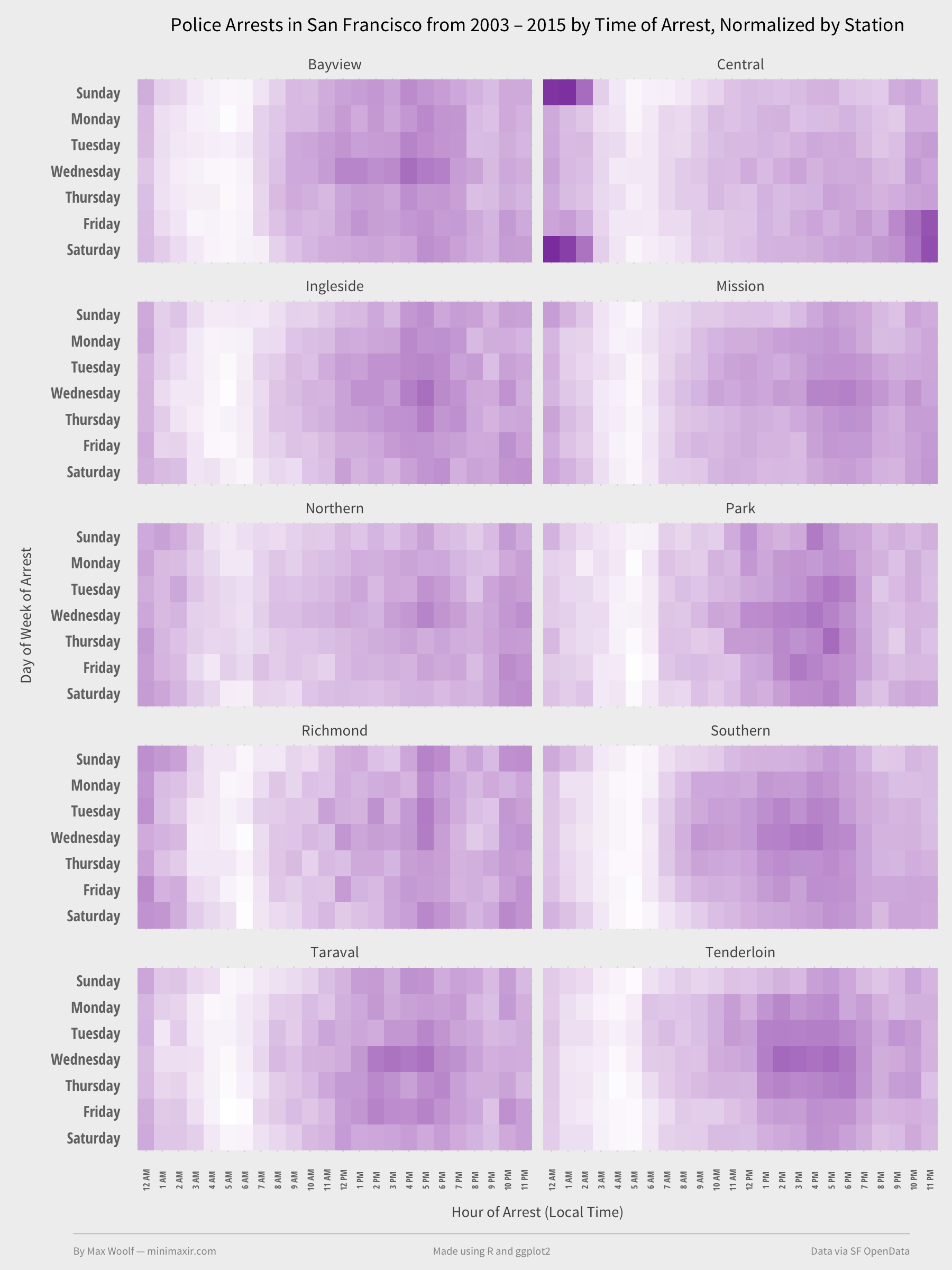
Which isn’t helpful. The charts are mostly identical to each other, and to the original heatmap. (Central Station (coverage map), however, has activity correlated to Drunkenness arrests.)
Perhaps the frequency of arrests is correlated to the time of year? How about faceting by month?
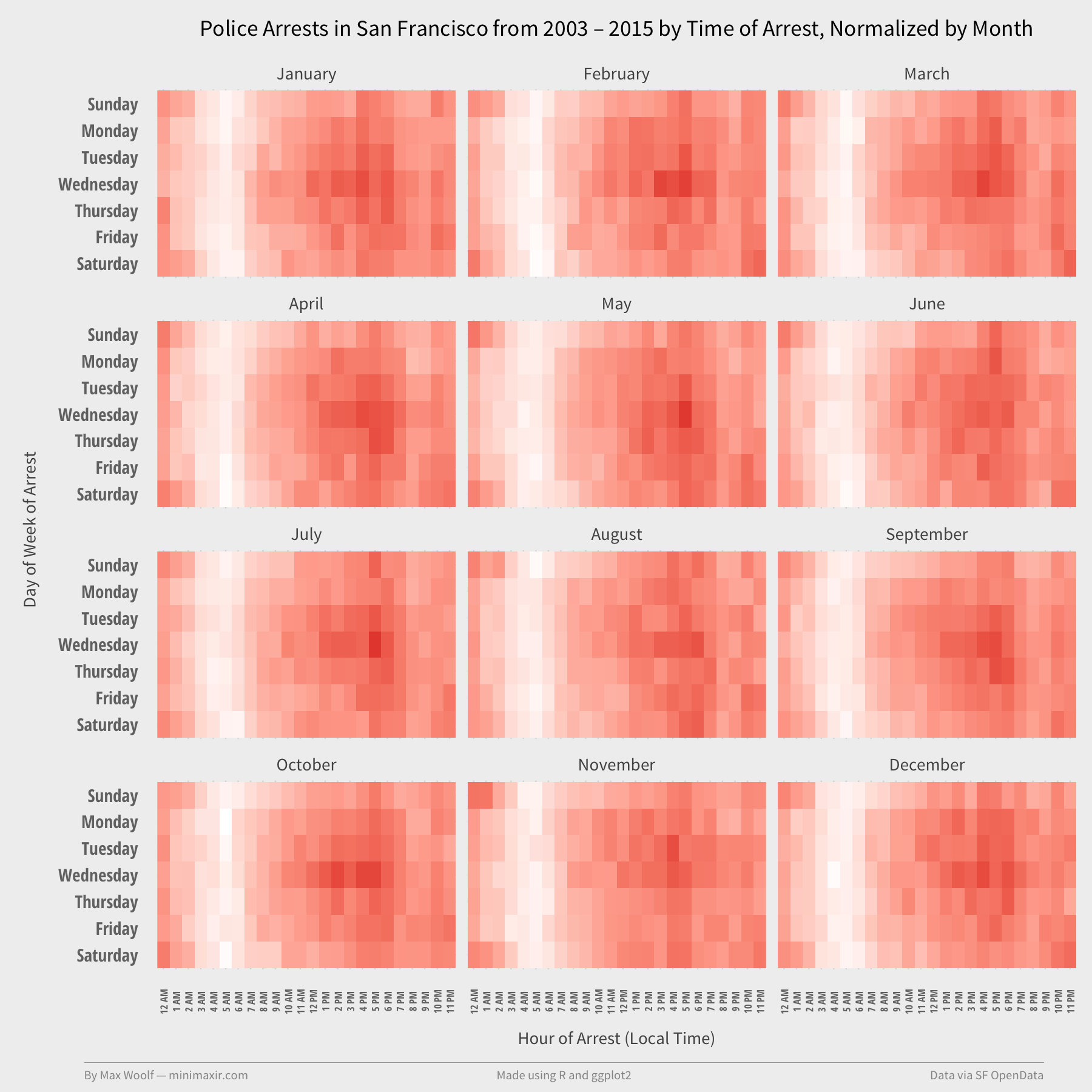
Nope. Zero difference.
Last try. As shown in the line chart, the # of Arrests has oscillated over the years. Perhaps there’s a specific year that’s skewing the results. Let’s facet by Year.
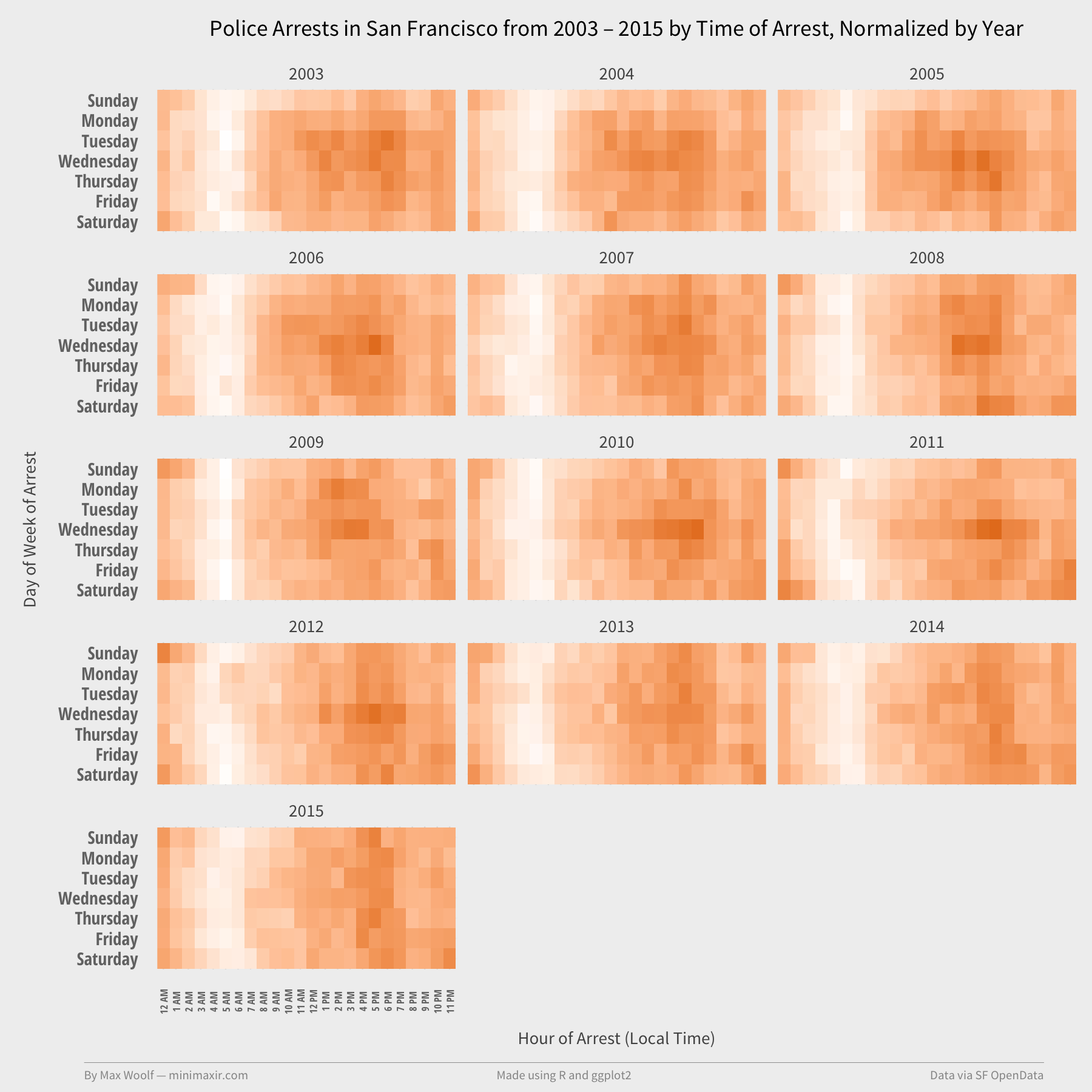
Nope^2. 2010-2012 have elevated Wednesday activity, but not by much.
This is frustrating. As of this posting, I don’t have an obvious answer for the elevated arrests Wednesdays at 4-5PM. That being said, there definitely is still more to learn from looking at SF Crime data, although that’s enough analysis for the time being.
My next article discusses how to plot arrests on a map using the ggmap R library, which hopefully will provide more answers. The GitHub repository contains a Jupyter notebook with code and visualizations for both for this article, and for the upcoming ggmap visualizations (if you want a sneak peek) which will show where arrests in San Francisco frequently occur.
If you use the code or data visualization designs contained within this article, it would be greatly appreciated if proper attribution is given back to this article and/or myself. Thanks!
