I’ve been working on a few personal deep learning projects with Keras and TensorFlow. However, training models for deep learning with cloud services such as Amazon EC2 and Google Compute Engine isn’t free, and as someone who is currently unemployed, I have to keep an eye on extraneous spending and be as cost-efficient as possible (please support my work on Patreon!). I tried deep learning on the cheaper CPU instances instead of GPU instances to save money, and to my surprise, my model training was only slightly slower. As a result, I took a deeper look at the pricing mechanisms of these two types of instances to see if CPUs are more useful for my needs.
The pricing of GPU instances on Google Compute Engine starts at $0.745/hr (by attaching a $0.700/hr GPU die to a $0.045/hr n1-standard-1 instance). A couple months ago, Google announced CPU instances with up to 64 vCPUs on the modern Intel Skylake CPU architecture. More importantly, they can also be used in preemptible CPU instances, which live at most for 24 hours on GCE and can be terminated at any time (very rarely), but cost about 20% of the price of a standard instance. A preemptible n1-highcpu-64 instance with 64 vCPUs and 57.6GB RAM plus the premium for using Skylake CPUs is $0.509/hr, about 2/3rds of the cost of the GPU instance.
If the model training speed of 64 vCPUs is comparable to that of a GPU (or even slightly slower), it would be more cost-effective to use the CPUs instead. But that’s assuming the deep learning software and the GCE platform hardware operate at 100% efficiency; if they don’t (and they likely don’t), there may be even more savings by scaling down the number of vCPUs and cost accordingly (a 32 vCPU instance with same parameters is half the price at $0.254/hr, 16 vCPU at $0.127/hr, etc).
There aren’t any benchmarks for deep learning libraries with tons and tons of CPUs since there’s no demand, as GPUs are the Occam’s razor solution to deep learning hardware. But what might make counterintuitive but economical sense is to use CPUs instead of GPUs for deep learning training because of the massive cost differential afforded by preemptible instances, thanks to Google’s economies of scale.
Setup
I already have benchmarking scripts of real-world deep learning use cases, Docker container environments, and results logging from my TensorFlow vs. CNTK article. A few minor tweaks allow the scripts to be utilized for both CPU and GPU instances by setting CLI arguments. I also rebuilt the Docker container to support the latest version of TensorFlow (1.2.1), and created a CPU version of the container which installs the CPU-appropriate TensorFlow library instead.
There is a notable CPU-specific TensorFlow behavior; if you install from pip (as the official instructions and tutorials recommend) and begin training a model in TensorFlow, you’ll see these warnings in the console:

In order to fix the warnings and benefit from these SSE4.2/AVX/FMA optimizations, we compile TensorFlow from source, and I created a third Docker container to do just that. When training models in the new container, most of the warnings no longer show, and (spoiler alert) there is indeed a speed boost in training time.
Therefore, we can test three major cases with Google Compute Engine:
- A Tesla K80 GPU instance.
- A 64 Skylake vCPU instance where TensorFlow is installed via
pip(along with testings at 8/16/32 vCPUs). - A 64 Skylake vCPU instance where TensorFlow is compiled (
cmp) with CPU instructions (+ 8/16/32 vCPUs).
Results
For each model architecture and software/hardware configuration, I calculate the total training time relative to the GPU instance training for running the model training for the provided test script. In all cases, the GPU should be the fastest training configuration, and systems with more processors should train faster than those with fewer processors.
Let’s start using the MNIST dataset of handwritten digits plus the common multilayer perceptron (MLP) architecture, with dense fully-connected layers. Lower training time is better. All configurations below the horizontal dotted line are better than GPUs; all configurations above the dotted line are worse than GPUs.
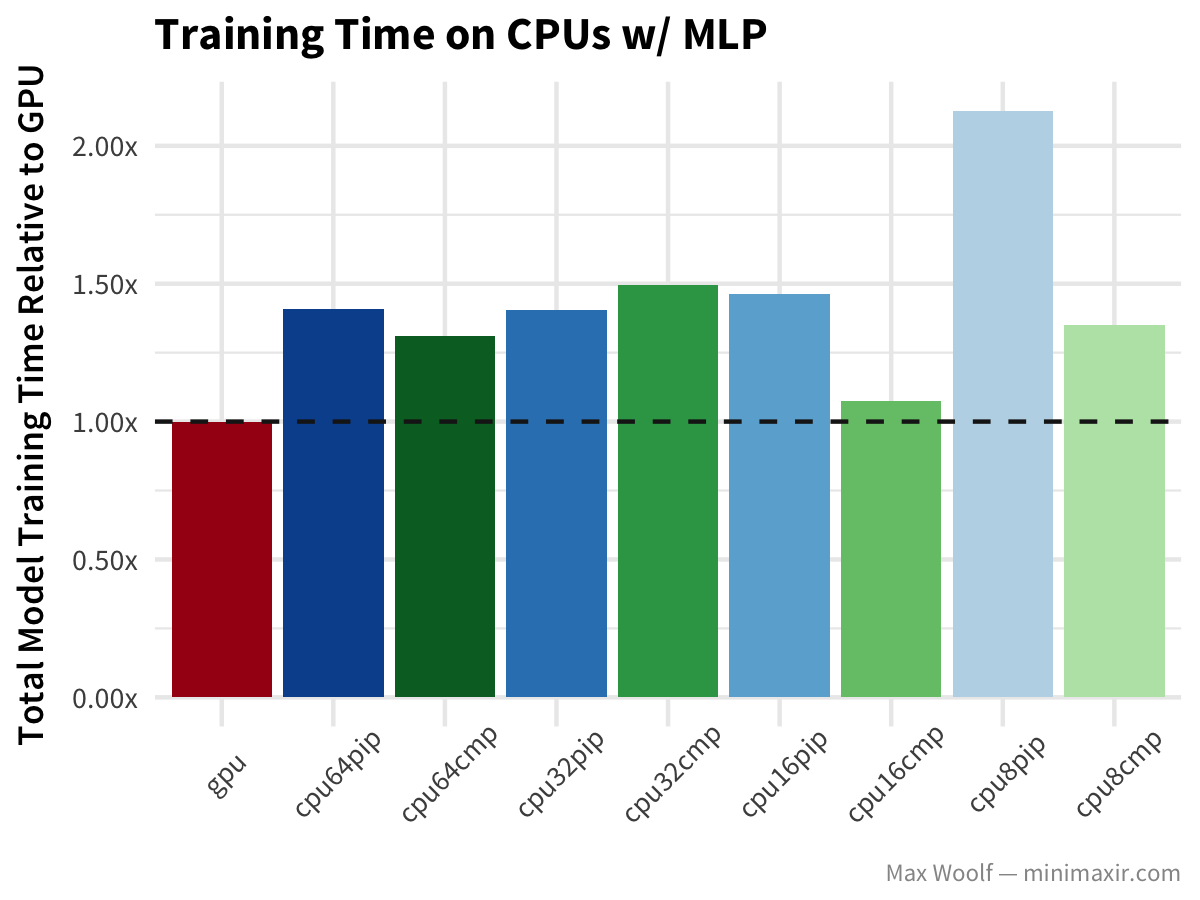
Here, the GPU is the fastest out of all the platform configurations, but there are other curious trends: the performance between 32 vCPUs and 64 vCPUs is similar, and the compiled TensorFlow library is indeed a significant improvement in training speed but only for 8 and 16 vCPUs. Perhaps there are overheads negotiating information between vCPUs that eliminate the performance advantages of more vCPUs, and perhaps these overheads are different with the CPU instructions of the compiled TensorFlow. In the end, it’s a black box, which is why I prefer black box benchmarking all configurations of hardware instead of theorycrafting.
Since the difference between training speeds of different vCPU counts is minimal, there is definitely an advantage by scaling down. For each model architecture and configuration, I calculate a normalized training cost relative to the cost of GPU instance training. Because GCE instance costs are prorated (unlike Amazon EC2), we can simply calculate experiment cost by multiplying the total number of seconds the experiment runs by the cost of the instance (per second). Ideally, we want to minimize cost.
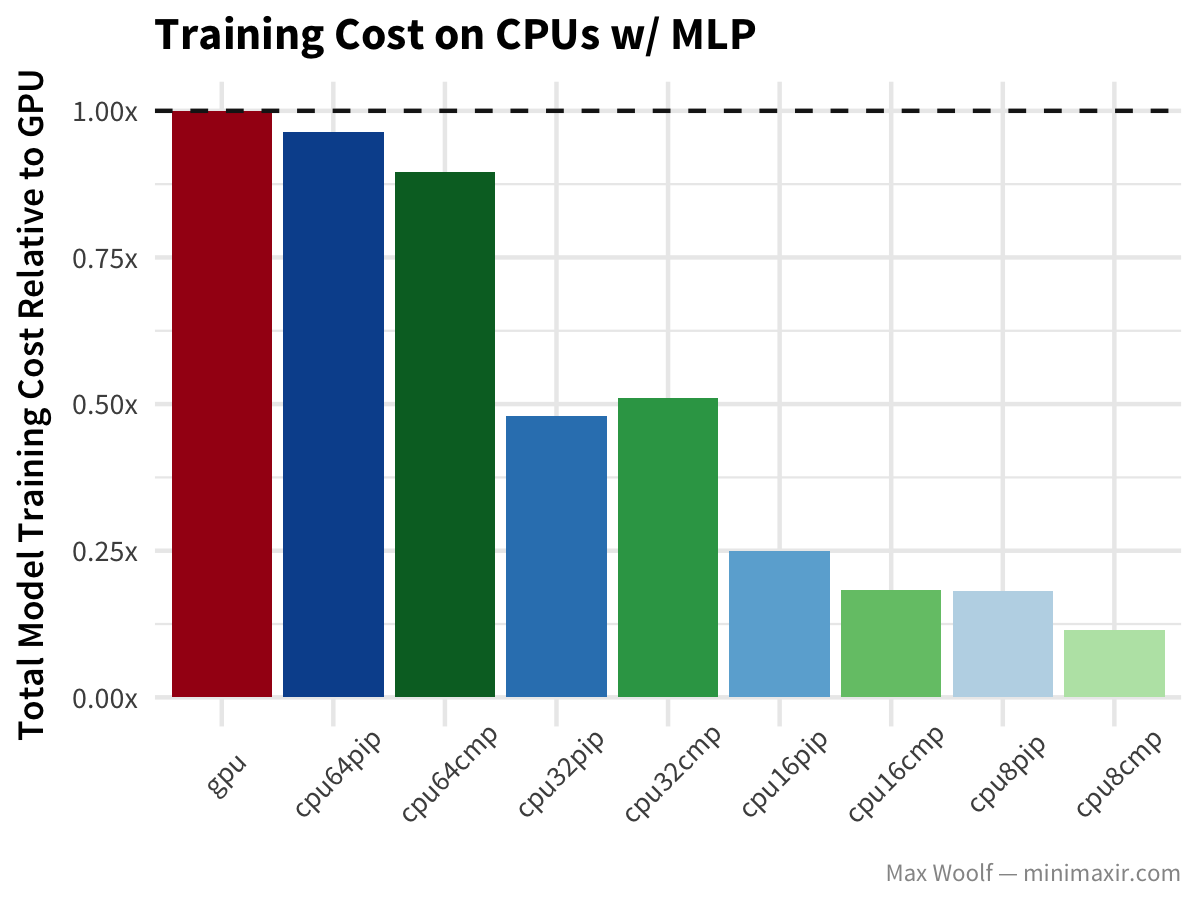
Lower CPU counts are much more cost-effective for this problem, when going as low as possible is better.
Now, let’s look at the same dataset with a convolutional neural network (CNN) approach for digit classification:
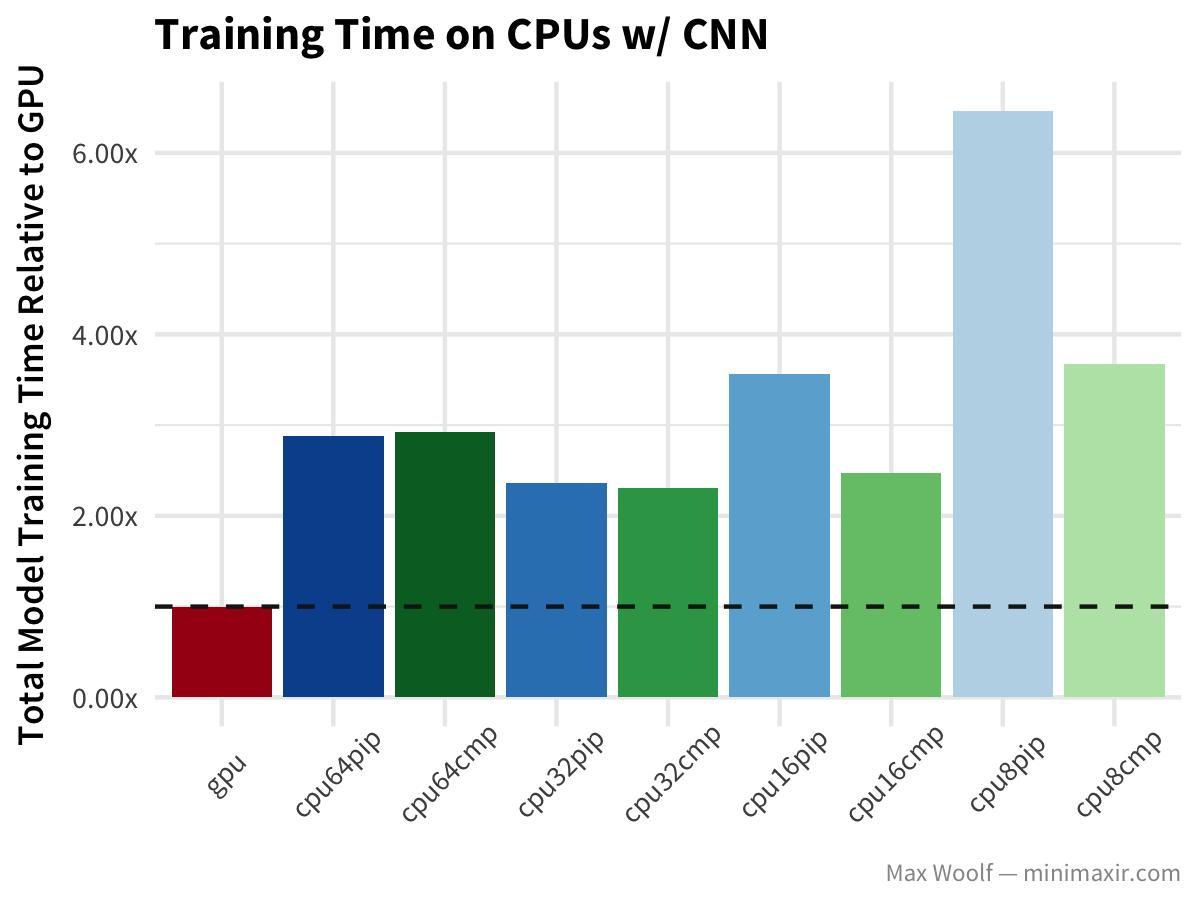
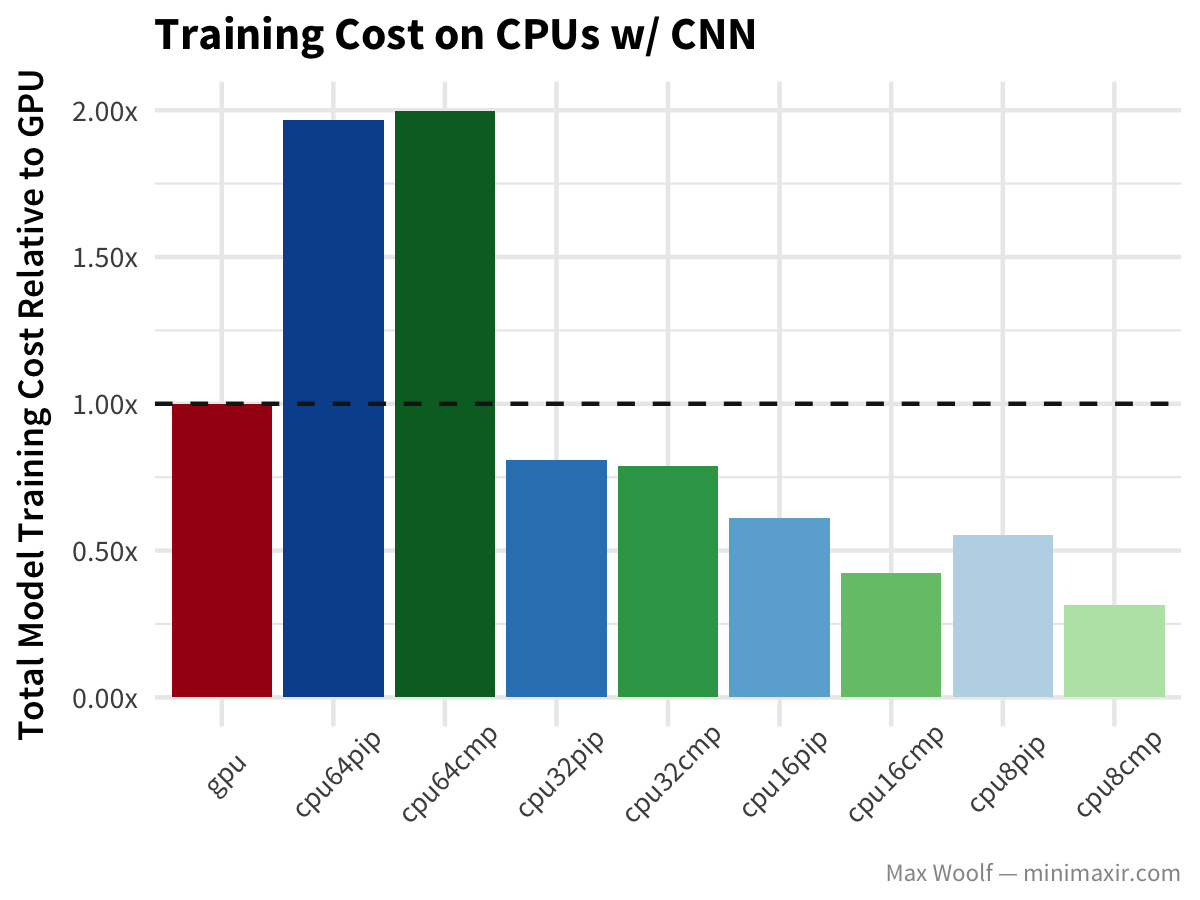
GPUs are unsurprisingly more than twice as fast as any CPU approach at CNNs, but cost structures are still the same, except that 64 vCPUs are worse than GPUs cost-wise, with 32 vCPUs training even faster than with 64 vCPUs.
Let’s go deeper with CNNs and look at the CIFAR-10 image classification dataset, and a model which utilizes a deep covnet + a multilayer perceptron and ideal for image classification (similar to the VGG-16 architecture).
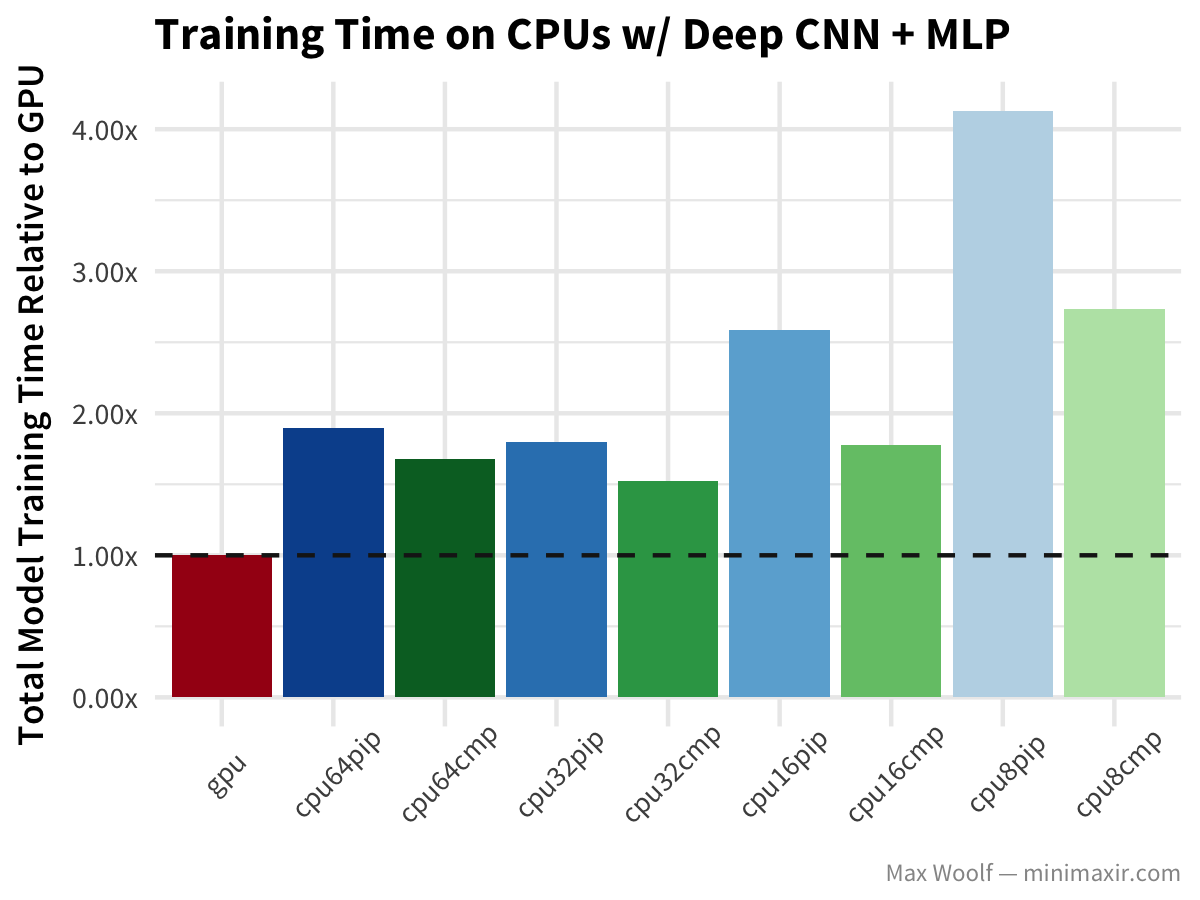
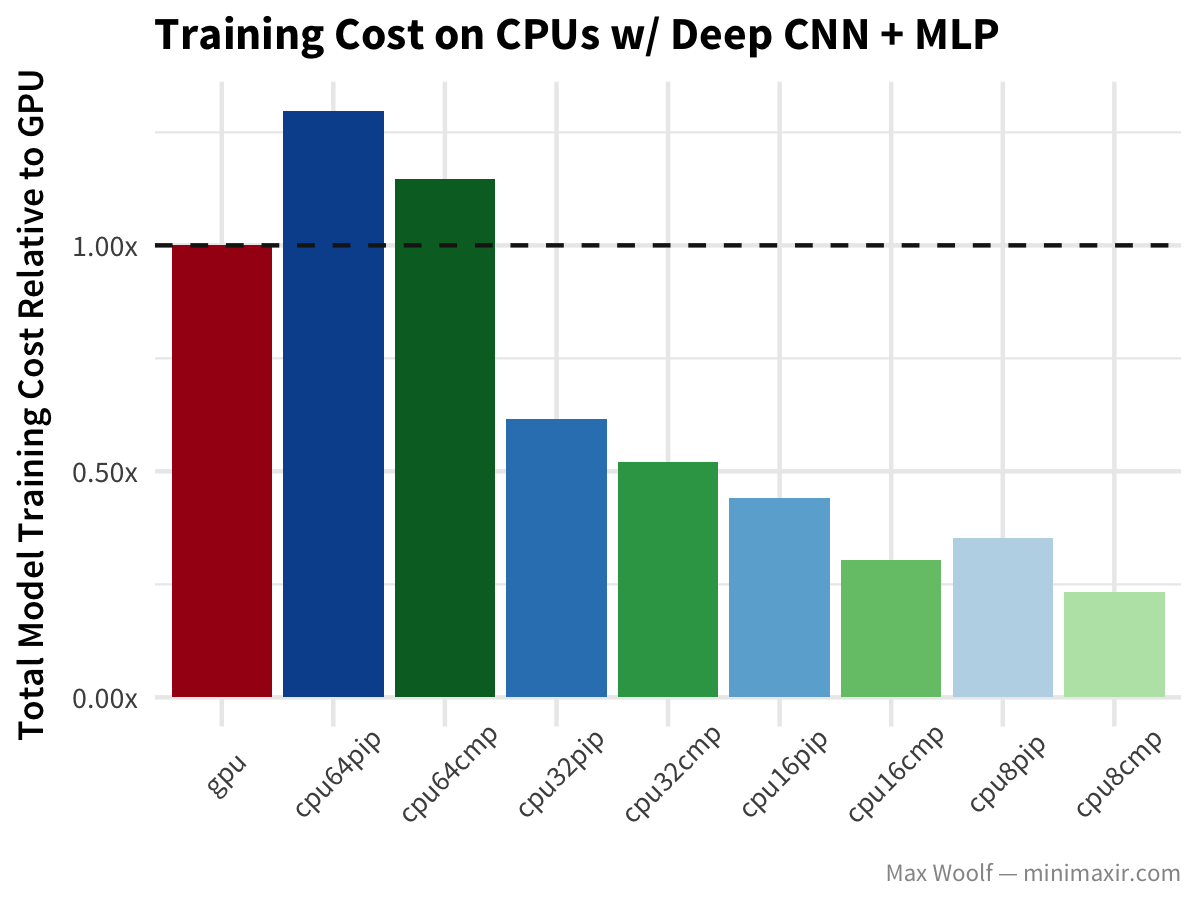
Similar behaviors as in the simple CNN case, although in this instance all CPUs perform better with the compiled TensorFlow library.
The fasttext algorithm, used here on the IMDb reviews dataset to determine whether a review is positive or negative, classifies text extremely quickly relative to other methods.
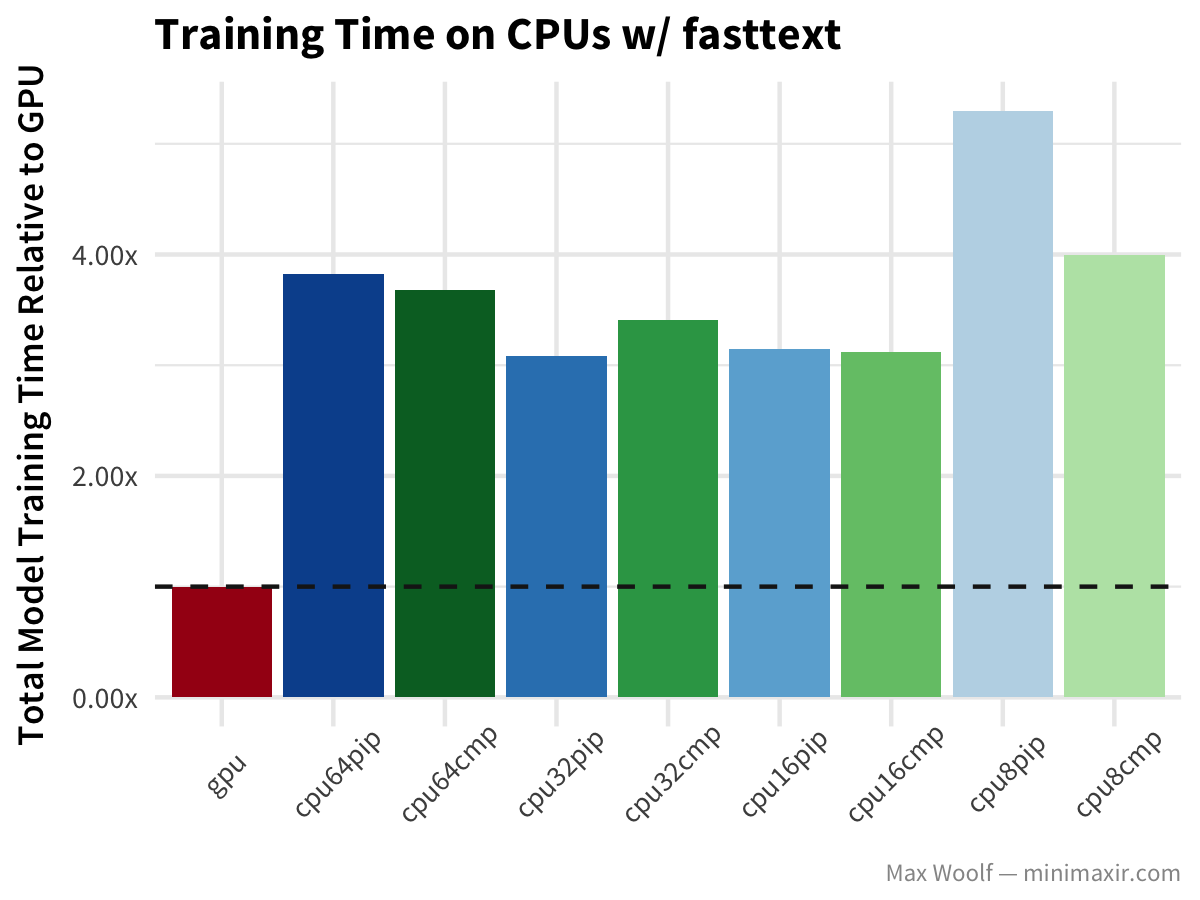
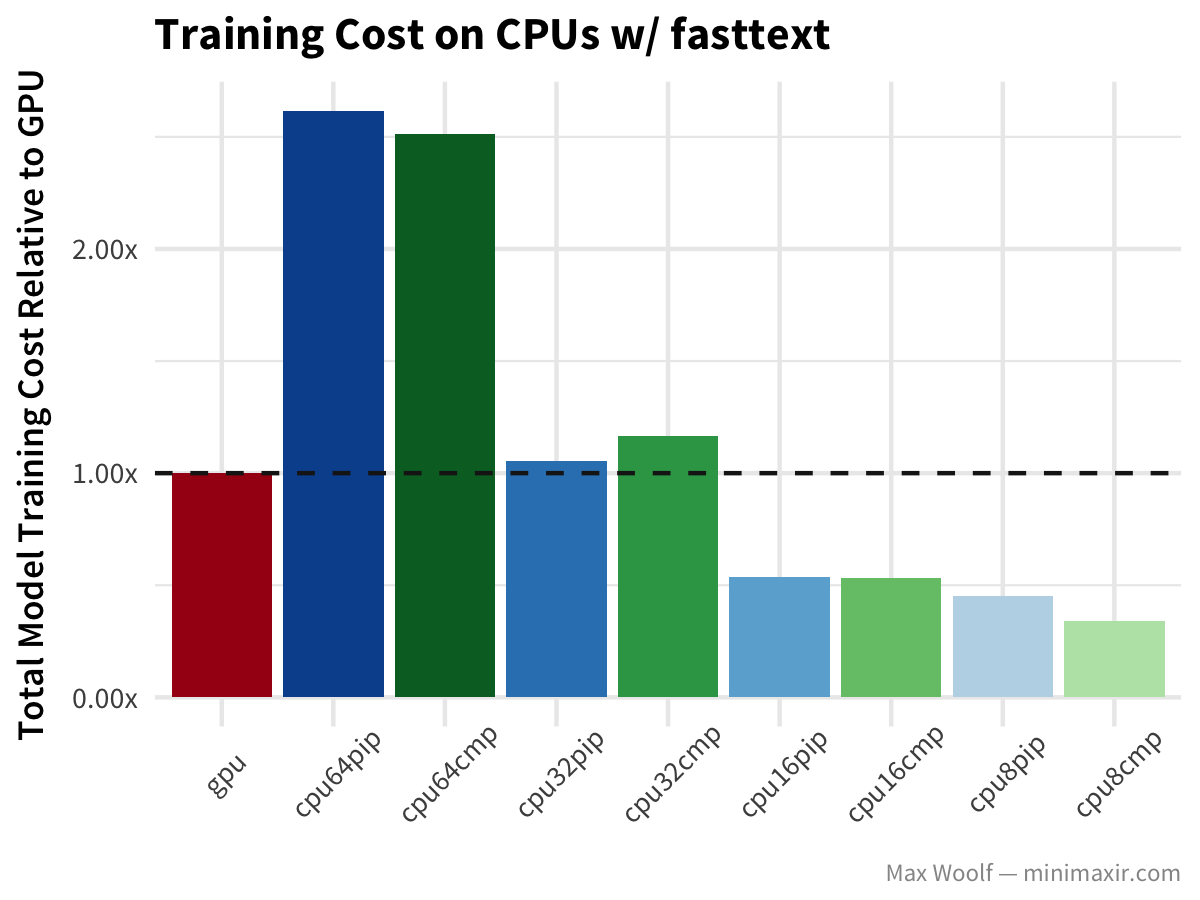
In this case, GPUs are much, much faster than CPUs. The benefit of lower numbers of CPU isn’t as dramatic; although as an aside, the official fasttext implementation is designed for large amounts of CPUs and handles parallelization much better.
The Bidirectional long-short-term memory (LSTM) architecture is great for working with text data like IMDb reviews, but after my previous benchmark article, commenters on Hacker News noted that TensorFlow uses an inefficient implementation of the LSTM on the GPU, so perhaps the difference will be more notable.
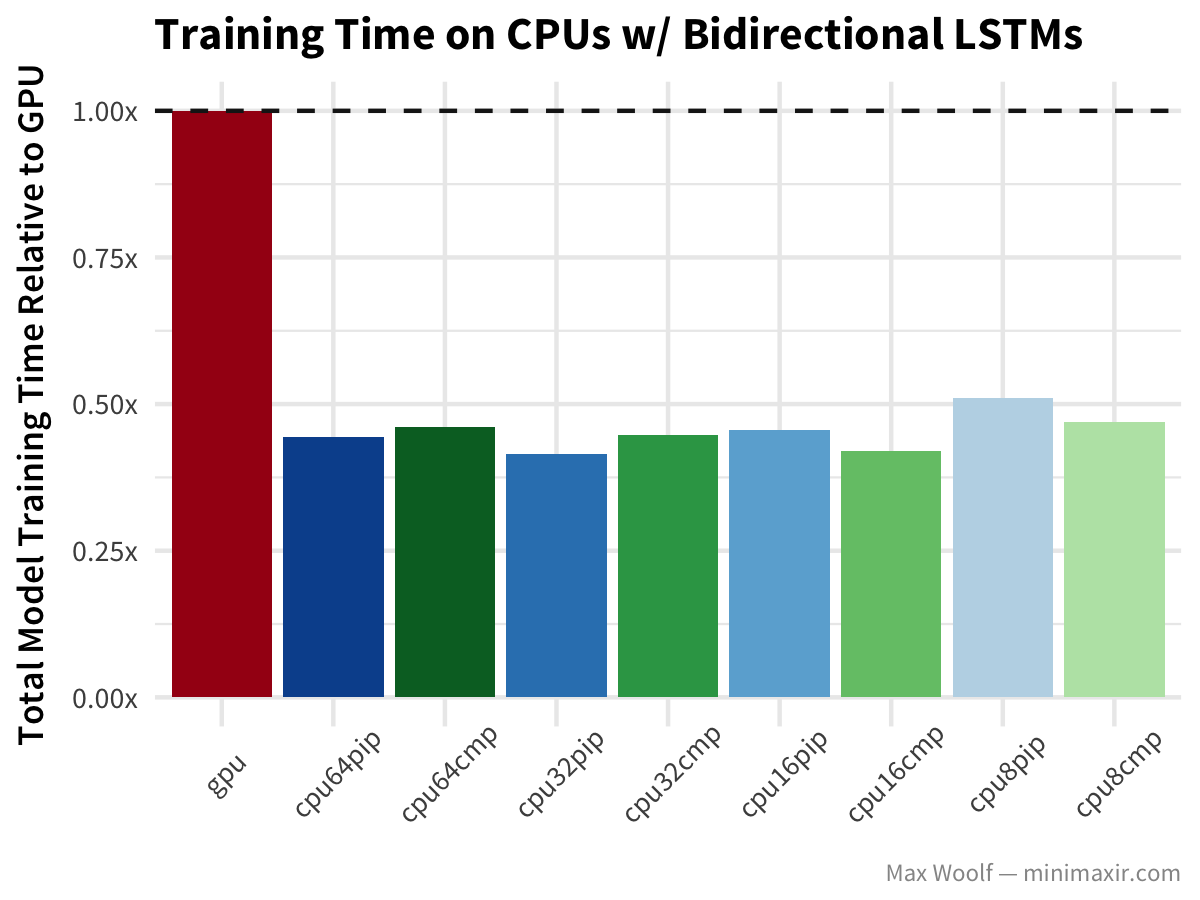
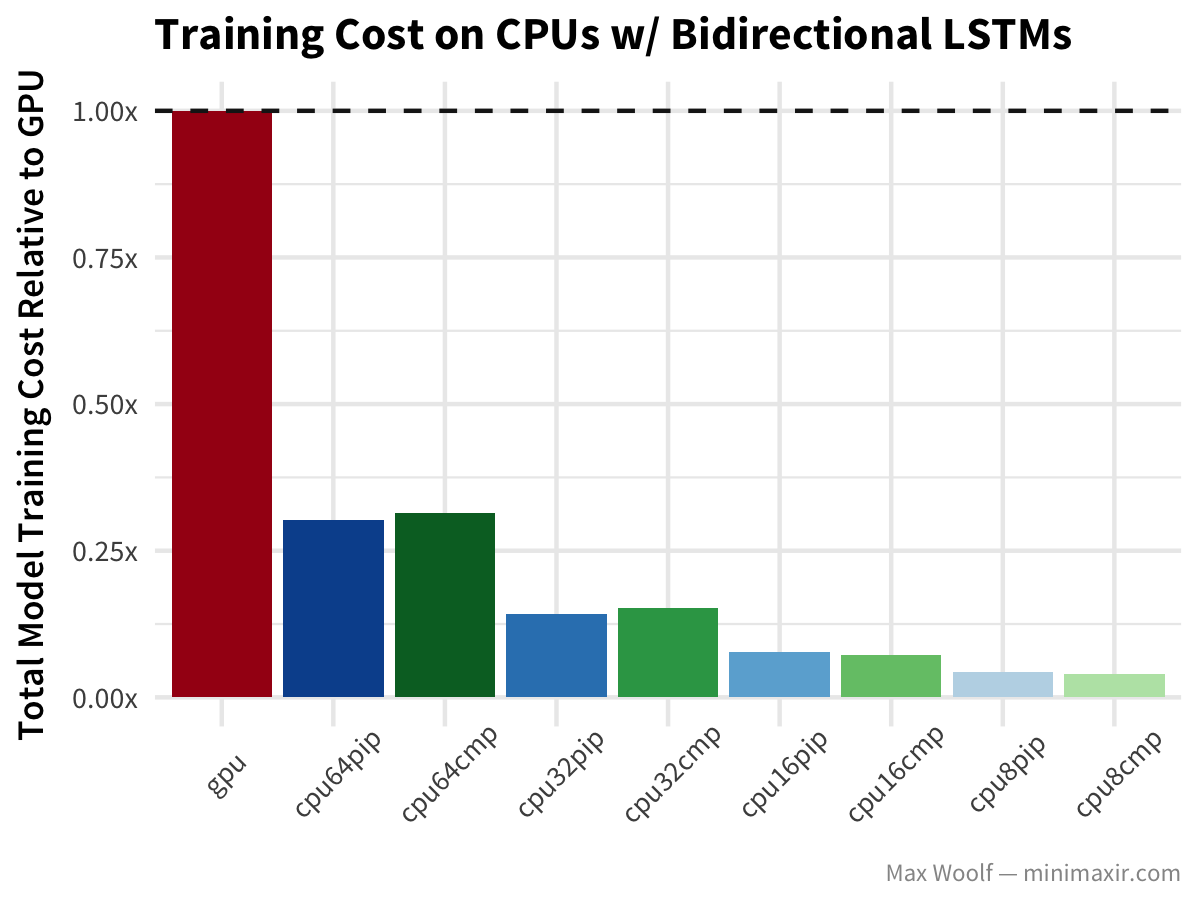
Wait, what? GPU training of Bidirectional LSTMs is twice as slow as any CPU configuration? Wow. (In fairness, the benchmark uses the Keras LSTM default of implementation=0 which is better on CPUs while implementation=2 is better on GPUs, but it shouldn’t result in that much of a differential)
Lastly, LSTM text generation of Nietzsche’s writings follows similar patterns to the other architectures, but without the drastic hit to the GPU.
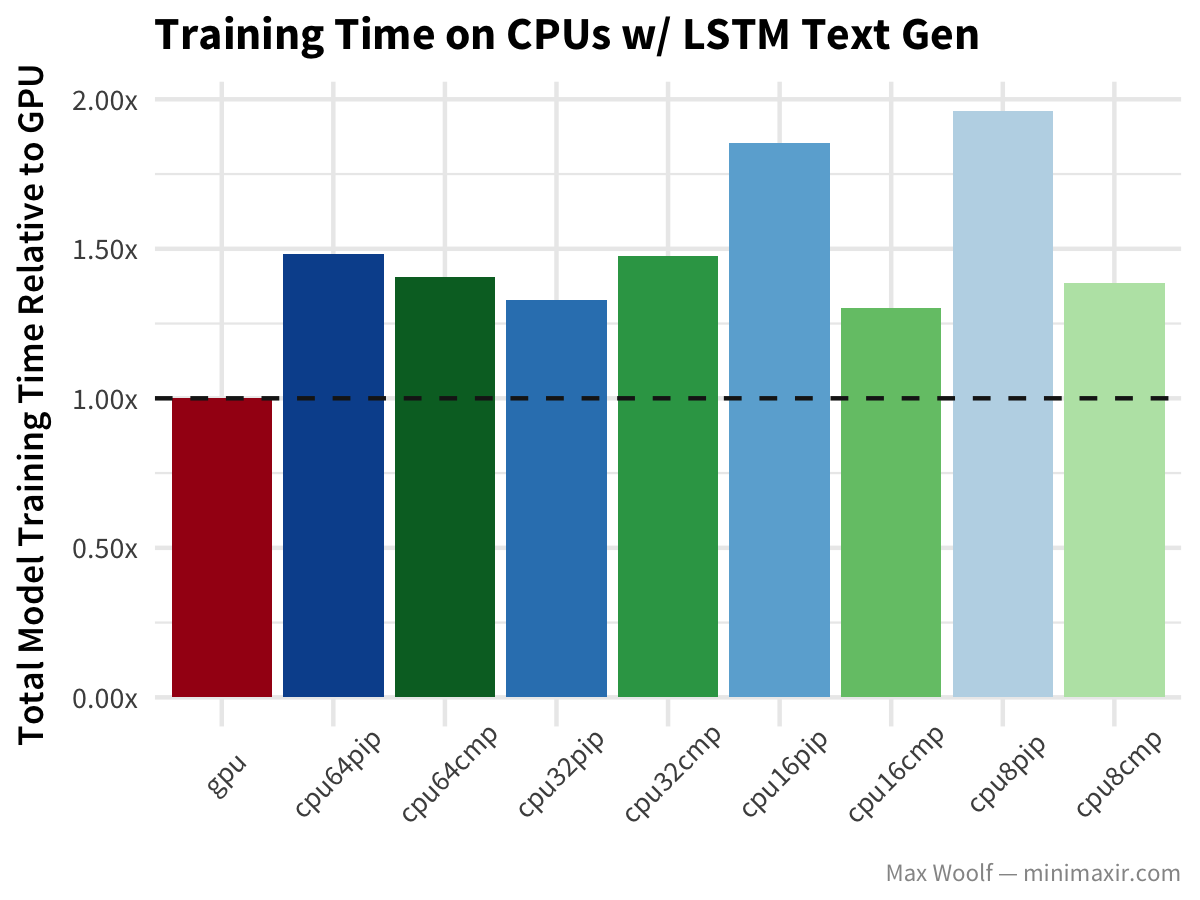
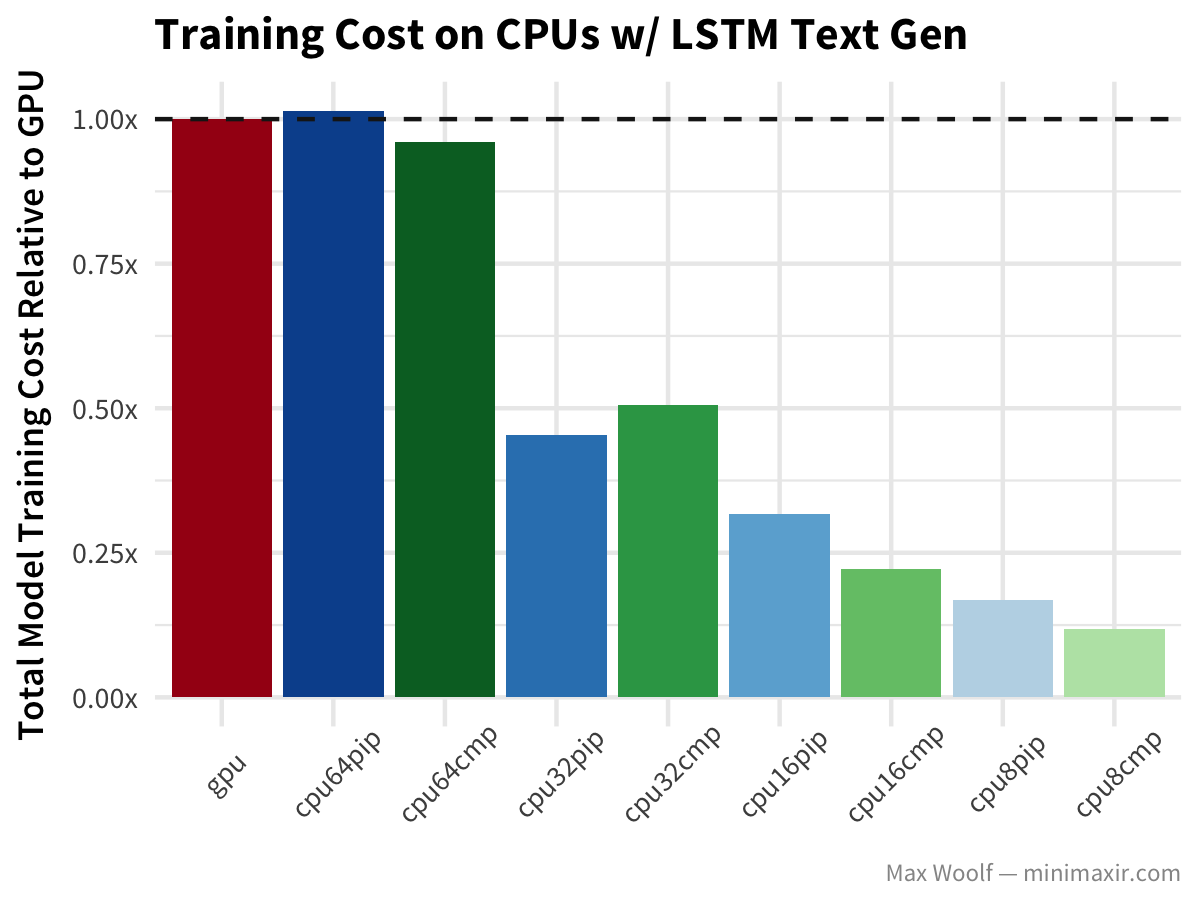
Conclusion
As it turns out, using 64 vCPUs is bad for deep learning as current software/hardware architectures can’t fully utilize all of them, and it often results in the exact same performance (or worse) than with 32 vCPUs. In terms balancing both training speed and cost, training models with 16 vCPUs + compiled TensorFlow seems like the winner. The 30%-40% speed boost of the compiled TensorFlow library was an unexpected surprise, and I’m shocked Google doesn’t offer a precompiled version of TensorFlow with these CPU speedups since the gains are nontrivial.
It’s worth nothing that the cost advantages shown here are only possible with preemptible instances; regular high-CPU instances on Google Compute Engine are about 5x as expensive, and as a result eliminate the cost benefits completely. Hooray for economies of scale!
A major implicit assumption with the cloud CPU training approach is that you don’t need a trained model ASAP. In professional use cases, time may be too valuable to waste, but in personal use cases where someone can just leave a model training overnight, it’s a very, very good and cost-effective option, and one that I’ll now utilize.
All scripts for running the benchmark are available in this GitHub repo. You can view the R/ggplot2 code used to process the logs and create the visualizations in this R Notebook.
