Deep learning is the biggest, often misapplied buzzword nowadays for getting pageviews on blogs. As a result, there have been a lot of shenanigans lately with deep learning thought pieces and how deep learning can solve anything and make childhood sci-fi dreams come true.
I’m not a fan of Clarke’s Third Law, so I spent some time checking out deep learning myself. As it turns out, with modern deep learning tools like Keras, a higher-level framework on top of the popular TensorFlow framework, deep learning is easy to learn and understand. Yes, easy. And it definitely does not require a PhD, or even a Computer Science undergraduate degree, to implement models or make decisions based on the output.
However, let’s try something more expansive than the stereotypical deep learning tutorials.
Characters Welcome
Word embeddings have been a popular machine learning trick nowadays. By using an algorithm such as Word2vec, you can obtain a numeric representation of a word, and use those values to create numeric representations of higher-level representations like sentences/paragraphs/documents/etc.

However, generating word vectors for datasets can be computationally expensive (see my earlier post which uses Apache Spark/Word2vec to create sentence vectors at scale quickly). The academic way to work around this is to use pretrained word embeddings, such as the GloVe vectors collected by researchers at Stanford NLP. However, GloVe vectors are huge; the largest one (840 billion tokens at 300D) is 5.65 GB on disk and may hit issues when loaded into memory on less-powerful computers.
Why not work backwards and calculate character embeddings? Then you could calculate a relatively few amount of vectors which would easily fit into memory, and use those to derive word vectors, which can then be used to derive the sentence/paragraph/document/etc vectors. But training character embeddings traditionally is significantly more computationally expensive since there are 5-6x the amount of tokens, and I don’t have access to the supercomputing power of Stanford researchers.
Why not use the existing pretrained word embeddings to extrapolate the corresponding character embeddings within the word? Think “bag-of-words,” except “bag-of-characters.” For example, from the embeddings from the word “the”, we can infer the embeddings for “t”, “h,” and “e” from the parent word, and average the t/h/e vectors from all words/tokens in the dataset corpus. (For this post, I will only look at the 840B/300D dataset since that is the only one with capital letters, which are rather important. If you want to use a dataset with smaller dimensionality, apply PCA on the final results)
I wrote a simple Python script that takes in the specified pretrained word embeddings and does just that, outputting the character embeddings in the same format. (for simplicity, only ASCII characters are included; the extended ASCII characters are intentionally omitted due to compatibility reasons. Additionally, by construction, space and newline characters are not represented in the derived dataset.)

You may be thinking that I’m cheating. So let’s set a point-of-reference. Colin Morris found that when 16D character embeddings from a model used in Google’s One Billion Word Benchmark are projected into a 2D space via t-SNE, patterns emerge: digits are close, lowercase and uppercase letters are often paired, and punctuation marks are loosely paired.
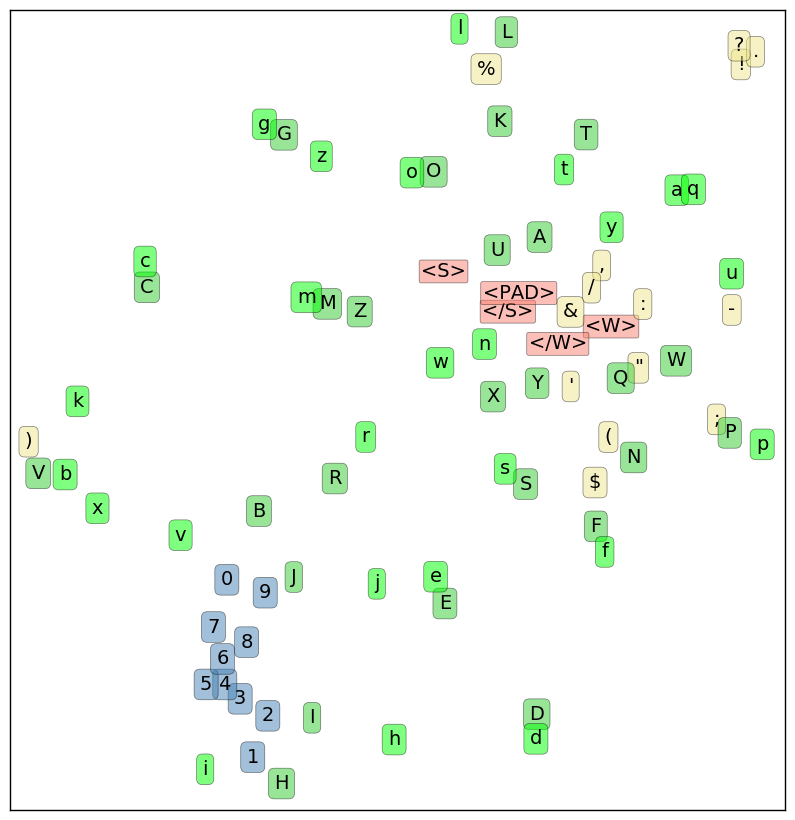
Let’s do that for my derived character embeddings, but with R and ggplot2. t-SNE is difficult to use for high-dimensional vectors as combinations of parameters can result in wildly different output, so let’s try a couple projections. Here’s what happens when my pretrained projections are preprojected from 300D to 16D via PCA whitening, and setting perplexity (number of optimal neighbors) to 7.
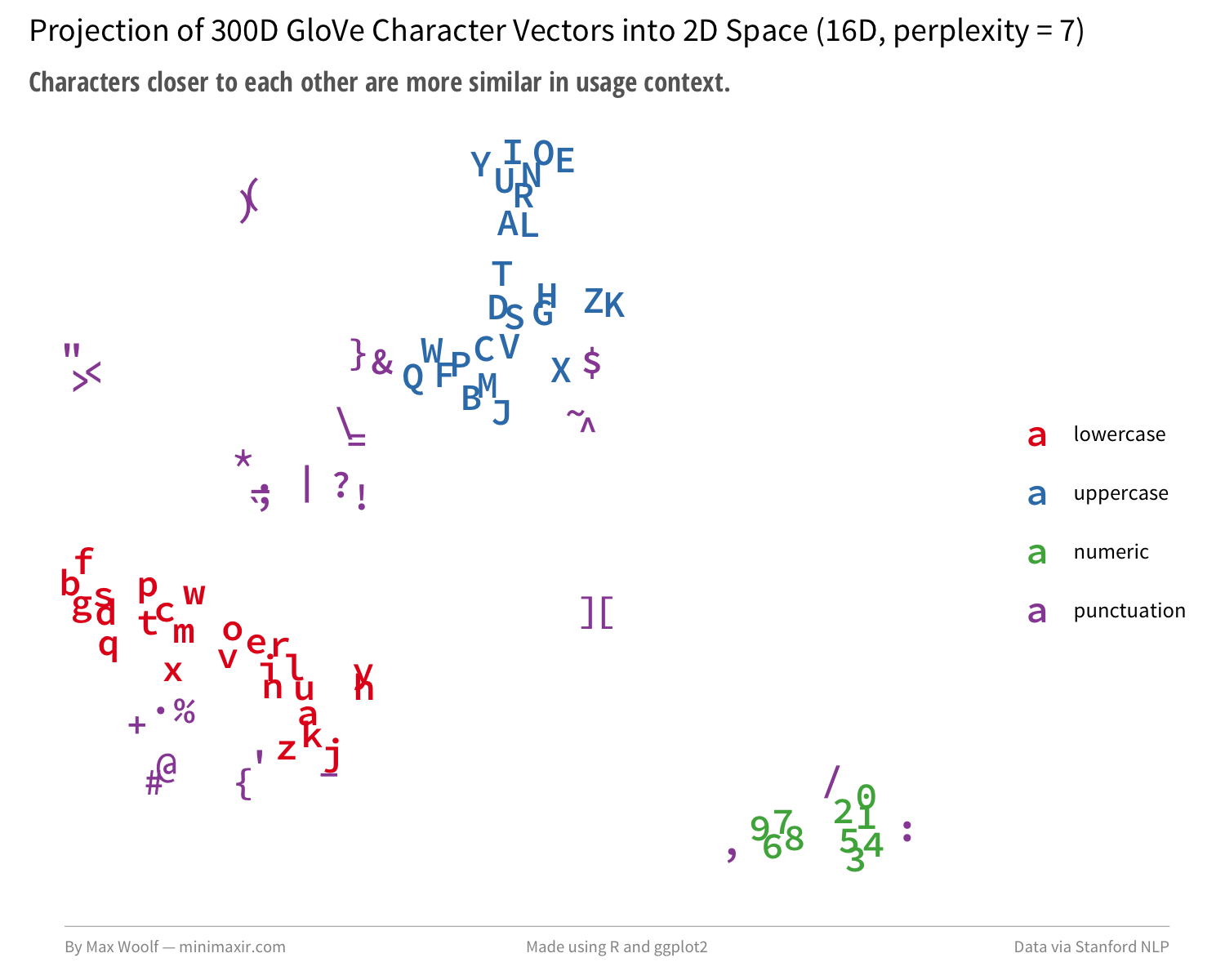
The algorithm manages to separate and group lowercase, uppercase, and numerals rather distinctly. Quadrupling the dimensionality of the preprocessing step to 64D and changing perplexity to 2 generates a depiction closer to the Google model projection:
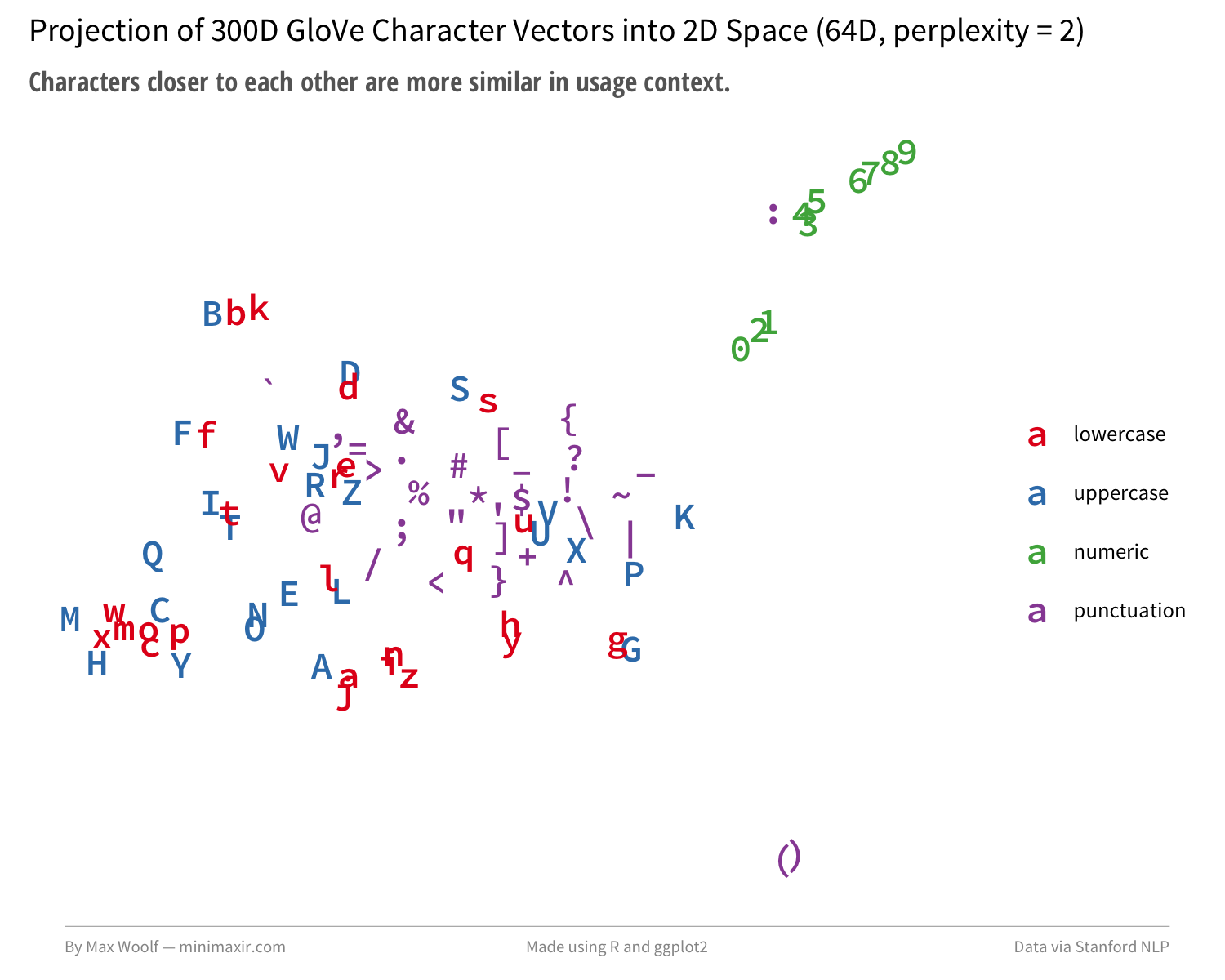
My pretrained character embeddings trick isn’t academic, but it’s successfully identifying realistic relationships. There might be something here worthwhile.
The Coolness of Deep Learning
Keras, maintained by Google employee François Chollet, is so good that it is effectively cheating in the field of machine learning, where even TensorFlow tutorials can be replaced with a single line of code. (which is important for iteration; Keras layers are effectively Lego blocks). A simple read of the Keras examples and documentation will let you reverse-engineer most the revolutionary deep learning clickbait thought pieces. Some create entire startups by changing the source dataset of the Keras examples and pitch them to investors none-the-wiser, or make very light wrappers on top the examples for teaching tutorial videos and get thousands of subscribers on YouTube.
I prefer to parse documentation/examples as a proof-of-concept, but never as gospel. Examples are often not the most efficient ways to implement a solution to a problem, just merely a start. In the case of Keras’s text generator example, the initial code was likely modeled after the 2015 blog post The Unreasonable Effectiveness of Recurrent Neural Networks by Andrej Karpathy and the corresponding project char-rnn. There have been many new developments in neural network architecture since 2015 that can improve both speed and performance of the text generation model as a whole.
What Text to Generate?
The Keras example uses Nietzsche writings as a data source, which I’m not fond of because it’s difficult to differentiate bad autogenerated Nietzsche rants from actual Nietzsche rants. What I want to generate is text with rules, with the algorithm being judged by how well it follows an inherent structure. My idea is to create Magic: The Gathering cards.

Inspired by the @RoboRosewater Twitter account by Reed Milewicz and the corresponding research and articles, I aim to see if it’s possible to recreate the structured design creativity for myself.
Even if you are not familiar with Magic and its rules, you can still find the card text of RoboRosewater cards hilarious:

Occasionally RoboRosewater, using a weaker model, produces amusing neural network trainwrecks:

More importantly, all Magic cards have an explicit structure; they have a name, mana cost in the upper-right, card type, card text, and usually a power and toughness in the bottom-right.
I wrote another Python script to parse all Magic card data from MTG JSON into an encoding which matches this architecture, where each section transition has its own symbol delimiter, along with other encoding simplicities. For example, here is the card Dragon Whelp in my encoding:
[Dragon Whelp@{2}{R}{R}#Creature — Dragon$Flying|{R}: ~ gets +1/+0 until end of turn. If this ability has been activated four or more times this turn, sacrifice ~ at the beginning of the next end step.%2^3]
These card encodings are all combined into one .txt file, which will be fed into the model.
Building and Training the Model
The Keras text generation example operates by breaking a given .txt file into 40-character sequences, and the model tries to predict the 41st character by outputting a probability for each possible character (108 in this dataset). For example, if the input based on the above example is ['D', 'r', 'a', 'g', ..., 'D', 'r', 'a', 'g'] (with the latter Drag being part of the creature type), the model will optimize for outputting a probability of 1.0 of o; per the categorical crossentropy loss function, the model is rewarded for assigning correct guesses with 1.0 probability and incorrect guesses with 0.0 probabilities, penalizing half-guesses and wrong guesses.
Each possible 40-character sequence is collected, however only every other third sequence is kept; this prevents the model from being able to learn card text verbatim, plus it also makes training faster. (for this model, there are about 1 million sequences for the final training). The example uses only a 128-node long-short-term-memory (LSTM) recurrent neural network (RNN) layer, popular for incorporating a “memory” into a neural network model, but the example notes at the beginning it can take awhile to train before generated text is coherent.
There are a few optimizations we can make. Instead of supplying the characters directly to the RNN, we can first encode them using an Embedding layer so the model can train character context. We can stack more layers on the RNN by adding a 2-level multilayer perceptron: a meme, yes, but it helps, as the network must learn latent representations of the data. Thanks to recent developments such as batch normalization and rectified linear activations for these Dense layers, they can both be trained without as much computational overhead, and thanks to Keras, both can be added to a layer with a single line of code each. Lastly, we can add an auxiliary output via Keras’s functional API where the network makes a prediction based on only the output from the RNN in addition to the main output, which forces it to work smarter and ends up resulting in a significant improvement in loss for the main path.
The final architecture ends up looking like this:
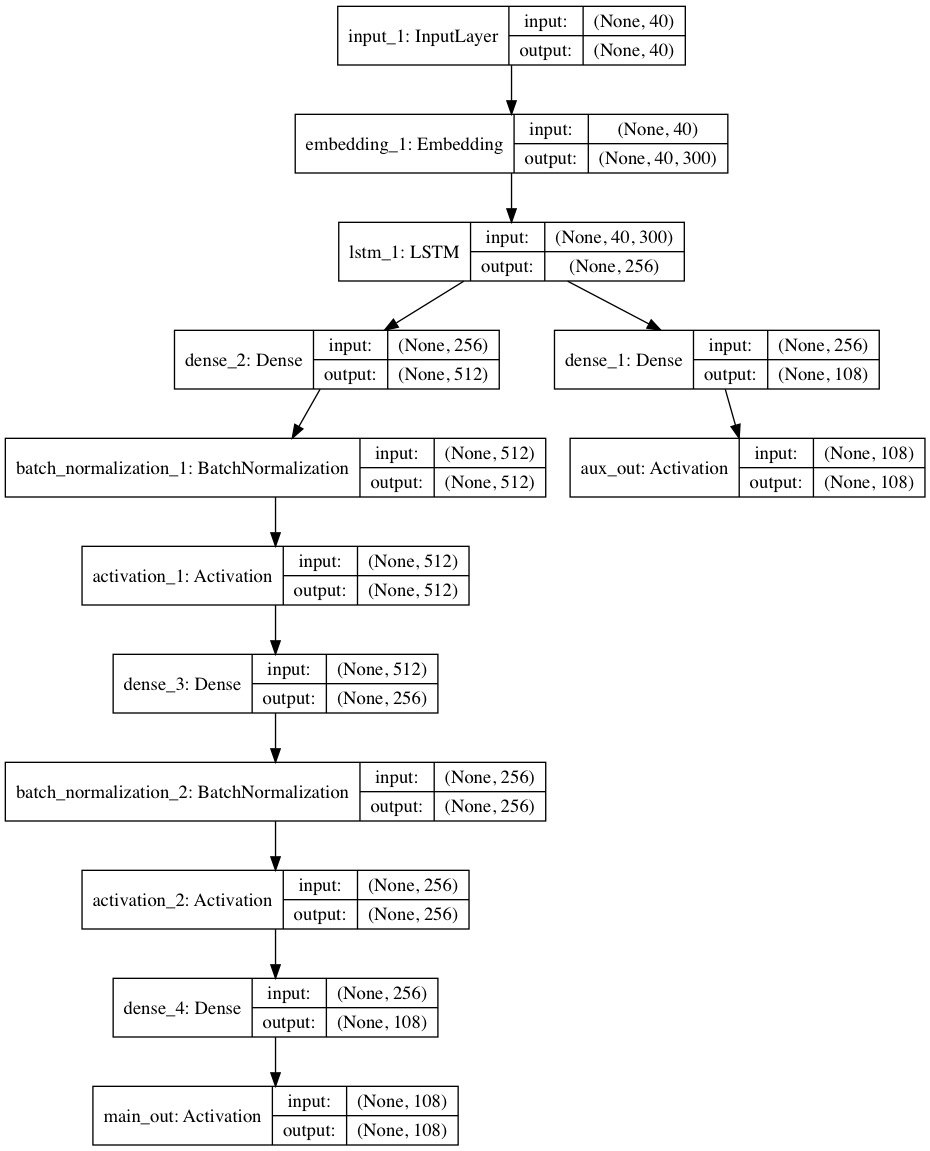
And because we added an Embedding layer, we can load the pretrained 300D character embeds I made earlier, giving the model a good start in understanding character relationships.
The goal of the training is to minimize the total loss of the model. (but for evaluating model performance, we only look at the loss of the main output). The model is trained in epochs, where the model sees all the input data atleast once. During each epoch, batches of size 128 are loaded into the model and evaluated, calculating a batch loss for each; the gradients from the batch are backpropagated into the previous layers to improve them. While training with Keras, the console reports an epoch loss, which is the average of all the batch losses so far in the current epoch, allowing the user to see in real time how the model improves, and it’s addicting.
Keras/TensorFlow works just fine on the CPU, but for models with a RNN, you’ll want to consider using a GPU for performance, specifically one by nVidia. Amazon has cloud GPU instances for $0.90/hr (not prorated), but very recently, Google announced GPU instances of the same caliber for ~$0.75/hr (prorated to the minute), which is what I used to train this model, although Google Compute Engine requires configuring the GPU drivers first. For 20 epochs, it took about 4 hours and 20 minutes to train the model while spending $3.26, which isn’t bad as far as deep learning goes.
Making Magic
After each epoch, the original Keras text generation example takes a sentence from the input data as a seed and predicts the next character in the sequence according to the model, then uses the last 40 characters generated for the next character, etc. The sampling incorporates a diversity/temperature parameter which allows the model to make suboptimal decisions and select characters with lower natural probabilities, which allows for the romantic “creativity” popular with neural network text generation.
With the Magic card dataset and my tweaked model architecture, generated text is coherent after the 1st epoch! After about 20 epochs, training becomes super slow, but the predicted text becomes super interesting. Here are a few fun examples from a list of hundreds of generated cards. (Note: the power/toughness values at the end of the card have issues; more on that later).
With low diversity, the neural network generated cards that are oddly biased toward card names which include the letter “S”. The card text also conforms to the rules of the game very well.
[Reality Spider@{3}{G}#Creature — Elf Warrior$Whenever ~ deals combat damage to a player, put a +1/+1 counter on it.%^]
[Dark Soul@{2}{R}#Instant$~ deals 2 damage to each creature without flying.%^]
[Standing Stand@{2}{G}#Creature — Elf Shaman${1}{G}, {T}: Draw a card, then discard a card.%^]
In contrast, cards generated with high diversity hit the uncanny valley of coherence and incoherence in both text and game mechanic abuse, which is what makes them interesting.
[Portrenline@{2}{R}#Sorcery$As an additional cost to cast ~, exile ~.%^]
[Clocidian Lorid@{W}{W}{W}#Instant$Regenerate each creature with flying and each player.%^]
[Icomic Convermant@{3}{G}#Sorcery$Search your library for a land card in your graveyard.%1^1]
The best-of-both-worlds cards are generated from diversity parameters between both extremes, and often have funny names.
[Seal Charm@{W}{W}#Instant$Exile target creature. Its controller loses 1 life.%^]
[Shambling Assemblaster@{4}{W}#Creature — Human Cleric$When ~ enters the battlefield, destroy target nonblack creature.%1^1]
[Lightning Strength@{3}{R}#Enchantment — Aura$Enchant creature|Enchanted creature gets +3/+3 and has flying, flying, trample, trample, lifelink, protection from black and votile all damage unless you return that card to its owner's hand.%2^2]
[Skysor of Shadows@{7}{B}{B}{B}#Enchantment$As ~ enters the battlefield, choose one —|• Put a -1/-1 counter on target creature.%2^2]
[Glinding Stadiers@{4}{W}#Creature — Spirit$Protection from no creatures can't attack.%^]
[Dragon Gault@{3}{G}{U}{U}#Creature — Kraven$~'s power and toughness are 2.%2^2]
All Keras/Python code used in this blog post, along with sample Magic card output and the trained model itself, is available open-source in this GitHub repository. The repo additionally contains a Python script which lets you generate new cards using the model, too!
Visualizing Model Performance
One thing deep learning tutorials rarely mention is how to collect the loss data and visualize the change in loss over time. Thanks to Keras’s utility functions, I wrote a custom model callback which collects the batch losses and epoch losses and writes them to a CSV file.
{% comment %} In addition to being able to generate images of neural network models as above, Keras has many useful utility functions which I added to the example, such as a callback to save the model while training, and a callback to log the losses to a CSV file. {% endcomment %}
Using R and ggplot2, I can plot the batch loss at every 50th batch to visualize how the model converges over time.
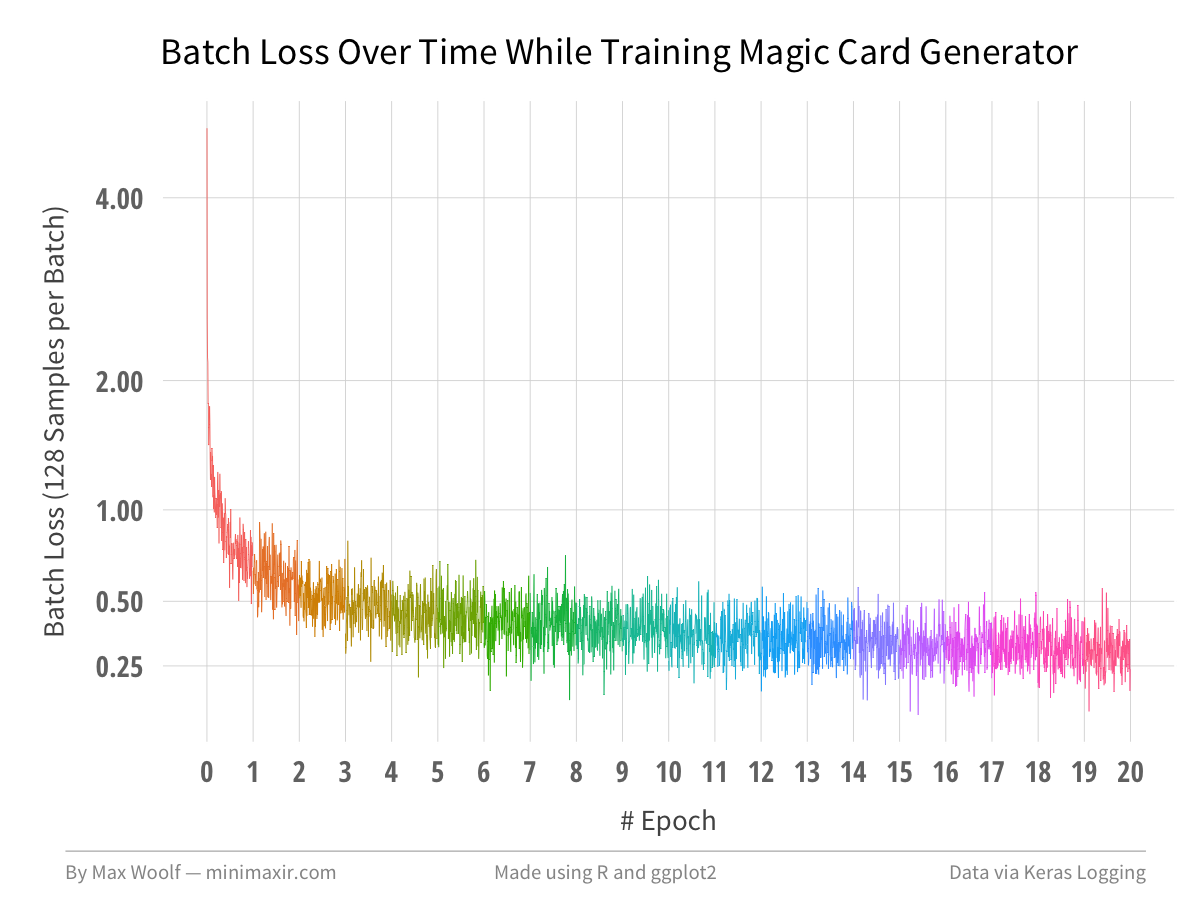
After 20 epochs, the model loss ends up at about 0.30 which is more-than-low-enough for coherent text. As you can see, there are large diminishing returns after a few epochs, which is the hard part of training deep learning models.
Plotting the epoch loss over the batches makes the trend more clear.
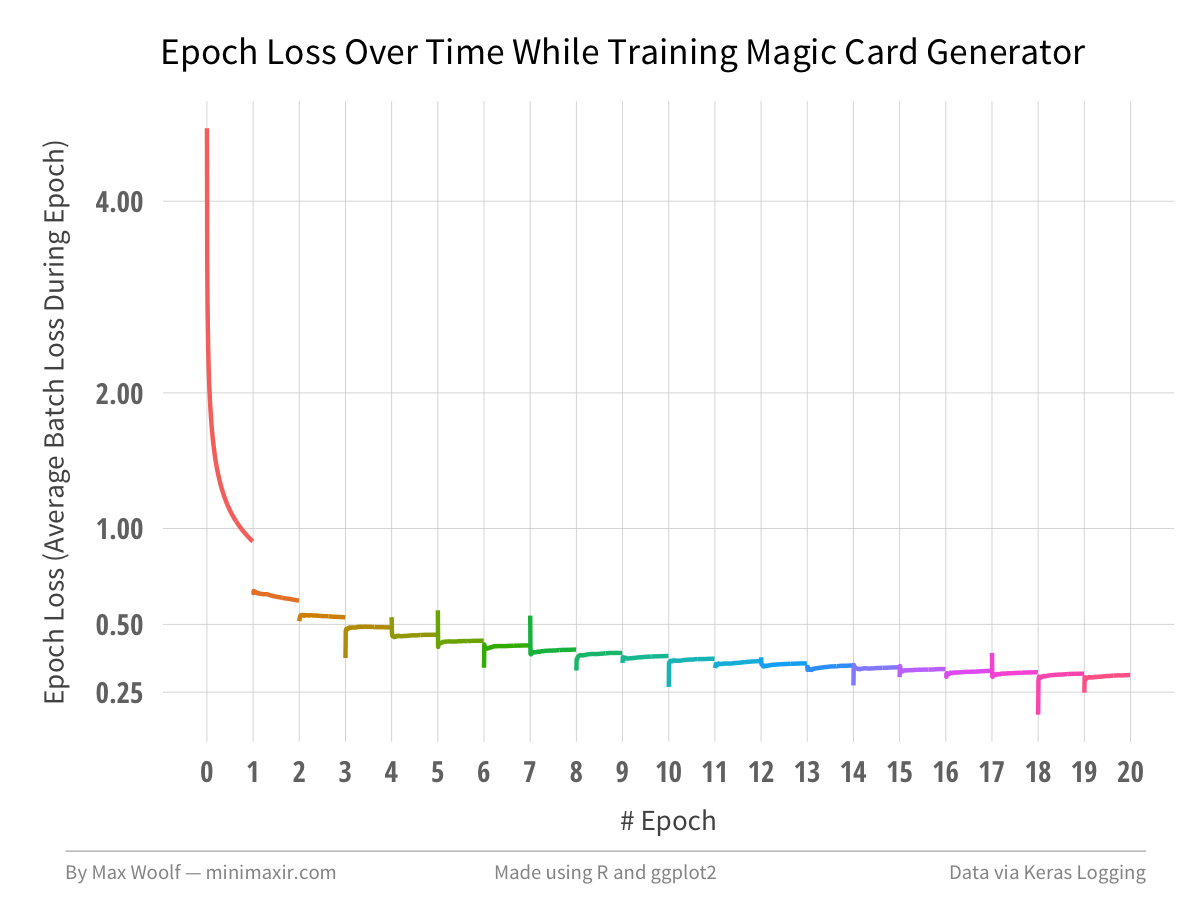
In order to prevent early convergence, we can make the model more complex (i.e. stack more layers unironically), but that has trade-offs, both in training and predictive speed, the latter of which is important if using deep learning in a production application.
Lastly, as with the Google One Billion Words benchmark, we can extract the trained character embeddings from the model (now augmented with Magic card context!) and plot them again to see what has changed.
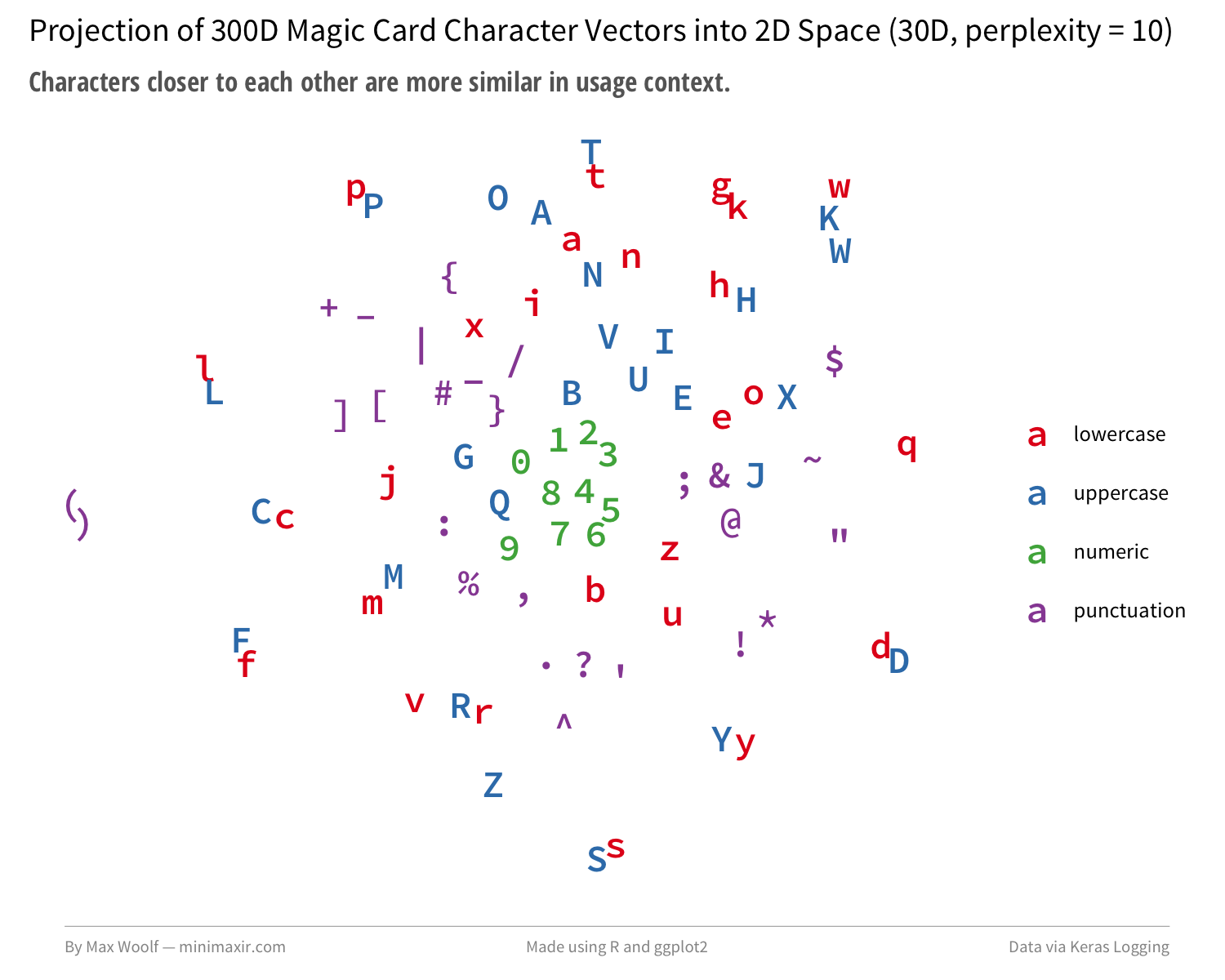
There are more pairs of uppercase/lowercase characters, although interestingly there isn’t much grouping with the special characters added as section breaks in the encoding, or mechanical uppercase characters such as W/U/B/R/G/C/T.
Next Steps
After building the model, I did a little more research to see if others solved the power/toughness problem. Since the sentences are only 40 characters and Magic cards are much longer than 40 characters, it’s likely that power/toughness are out-of-scope for the model and it cannot learn their exact values. Turns out that the intended solution is to use a completely different encoding, such as this one for Dragon Whelp:
|5creature|4|6dragon|7|8&^^/&^^^|9flying\{RR}: @ gets +&^/+& until end of turn. if this ability has been activated four or more times this turn, sacrifice @ at the beginning of the next end step.|3{^^RRRR}|0N|1dragon whelp|
Power/toughness are generated near the beginning of the card. Sections are delimited by pipes, with a numeral designating the corresponding section. Instead of numerals being used card values, carets are used, which provides a more accurate quantification of values. With this encoding, each character has a singular purpose in the global card context, and their embeddings would likely generate more informative visualizations. (But as a consequence, the generated cards are harder to parse at a glance).
The secondary encoding highlights a potential flaw in my methodology using pretrained character embeddings. Trained machine learning models must be used apples-to-apples on similar datasets; for example, you can’t accurately perform Twitter sentiment analysis on a dataset using a model trained on professional movie reviews since Tweets do not follow AP Style guidelines. In my case, the Common Crawl, the source of the pretrained embeddings, follows more natural text usage and would not work analogously with the atypical character usages in either of the Magic card encodings.
There’s still a lot of work to be done in terms of working with both pretrained character embeddings and improving Magic card generation, but I believe there is promise. The better way to make character embeddings than my script is to do it the hard way and train then manually, maybe even at a higher dimensionality like 500D or 1000D. Likewise, for Magic model building, the mtg-rnn instructions repo uses a large LSTM stacked on a LSTM along with 120/200-character sentences, both of which combined make training VERY slow (notably, this was the architecture of the very first commit for the Keras text generation example, and was changed to the easily-trainable architecture). There is also promise in a variational autoencoder approach, such as with textvae.
This work is potentially very expensive and I am strongly considering setting up a Patreon in lieu of excess venture capital to subsidize my machine learning/deep learning tasks in the future.
At minimum, working with this example gave me a sufficient application of practical work with Keras, and another tool in my toolbox for data analysis and visualization. Keras makes the model-construction aspect of deep learning trivial and not scary. Hopefully, this article justifies the use of the “deep learning” buzzword in the headline.
It’s also worth mentioning that I actually started working on automatic text generation 6 months ago using a different, non-deep-learning approach, but hit a snag and abandoned that project. With my work on Keras, I found a way around that snag, and on the same Magic dataset with the same input construction, I obtained a model loss of 0.03 at 20% of the cloud computing cost in about the same amount of time. More on that later.
The code for generating the R/ggplot2 data visualizations is available in this R Notebook, and open-sourced in this GitHub Repository.
You are free to use the automatic text generation scripts and data visualizations from this article however you wish, but it would be greatly appreciated if proper attribution is given to this article and/or myself!
