I recently wrote a post on how to visualize network graphs of Reddit subreddits.
One of the reasons I’ve been researching the topic is to find a good way to facilitate discovery of lesser-known subreddits, as Reddit is doing a terrible job at it (although they have been trying a few new experiments very recently). As it turns out, invoking graph theory is overkill. Even fancy machine learning approaches like collaborative filtering, while powerful, may not be required to help Redditors discover new things.
Finding Related Subreddits
Let’s say we have two sets: Set A, where A represents the number of active users in a given subreddit, and set B, where B is the set of active users in a subreddit. The intersection of Sets A and B (A ∩ B) represents users who are active in both subreddits.
Using BigQuery, I can get the comment data from ALL public Reddit subreddits, as otherwise this technique would not work well using any smaller subset. The network graph edgelist conveniently gives (A ∩ B), obtained as described in my previous post, which calculates the number of active users for all pairs of subreddits (defining “active users” as users who have made a comment in at least 5 unique threads in a given subreddit within the past 6 months).
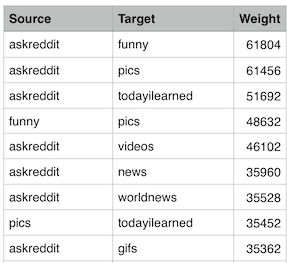
In this case, we can filter the edgelist to only allow intersections where there are at least 10 active users; this prevents including dead and personal subreddits.
We can run another similar query to get the number of active users for each subreddit.
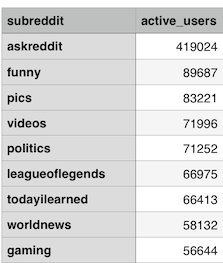
After that, for a given subreddit A, find:
(A ∩ B) / (B)
for all subreddits B where (A ∩ B) > 0 (i.e. only neighbors of A). This computation takes less than a second. Additionally, the output is always a percentage between 0% and 100%. For the visualizations, we plot the Top 15 subreddits with the highest overlap of the specified subreddit A (and color the bars with a nice viridis palette to provide another easy way to perceive relative magnitude of relatedness).
The methodology may sound arbitrary, but the results are very interesting. Here’s a chart of the top related subreddits for /r/aww, one of the most popular places on the internet for cat pictures.
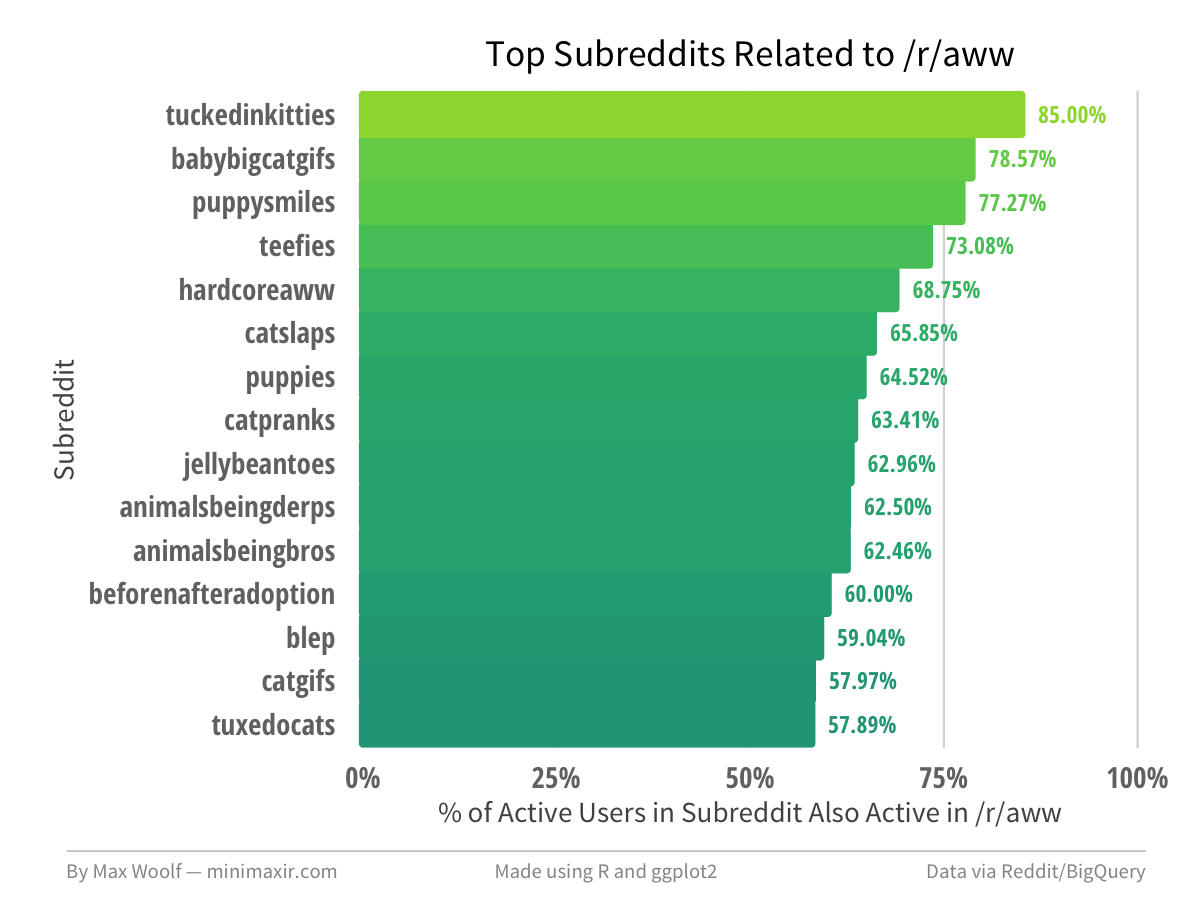
I have honestly never heard of any of these subreddits before. But yet, by analyzing public user activity alone, I found a few new places to get more cute pics.
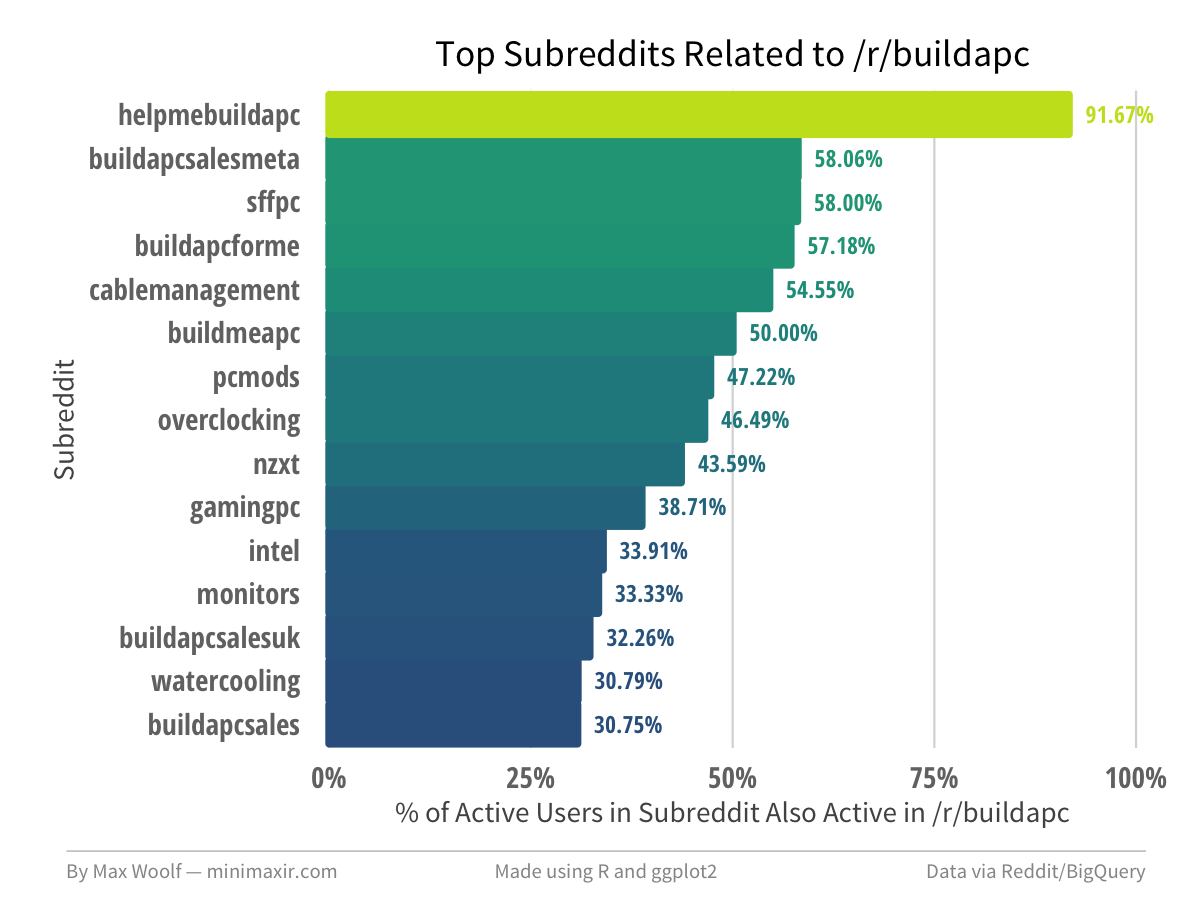
This methodology is excellent for finding subreddit-specific subsubreddits which may not be documented. The related subreddits for /r/buildapc offer more places to get PC building advice.
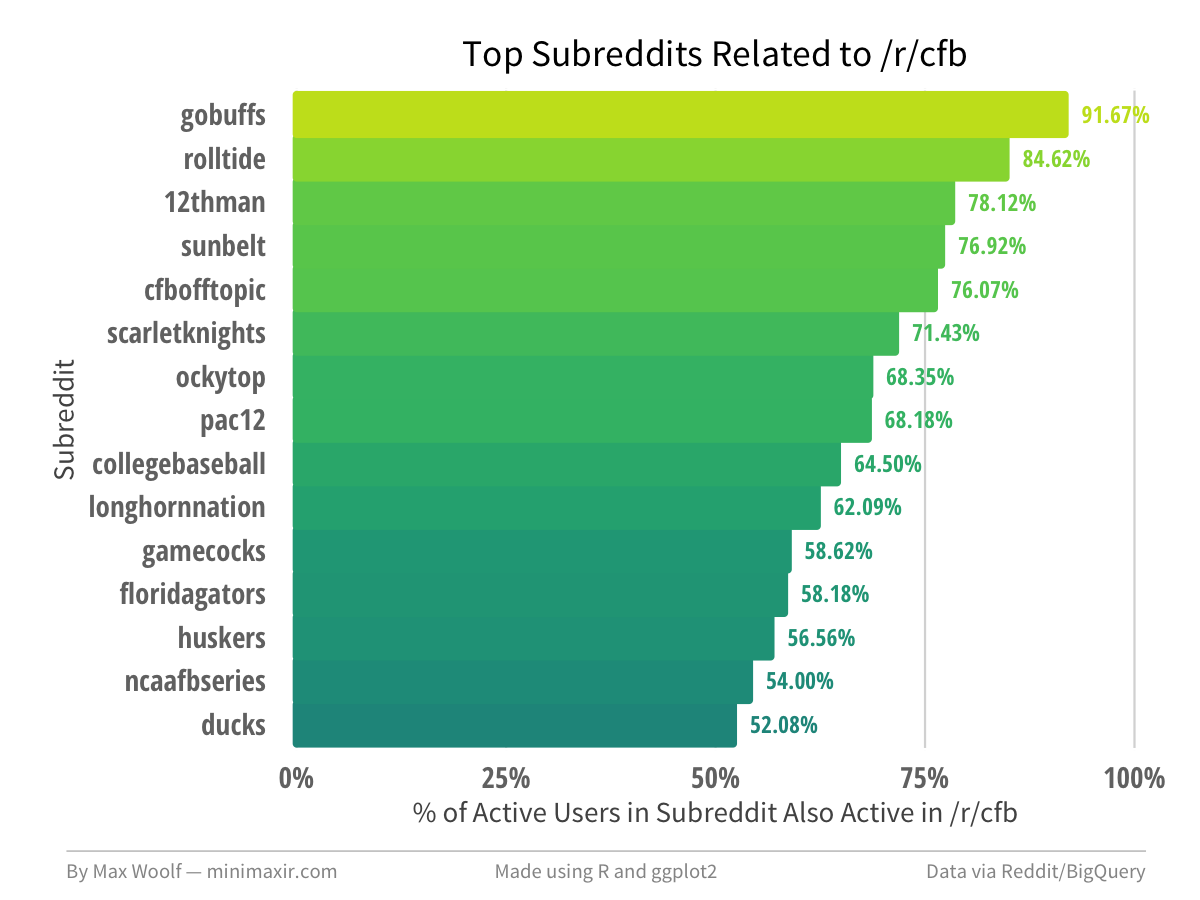
Related subreddits for sport-specific subreddits, like /r/cfb (college football) include the corresponding teams.
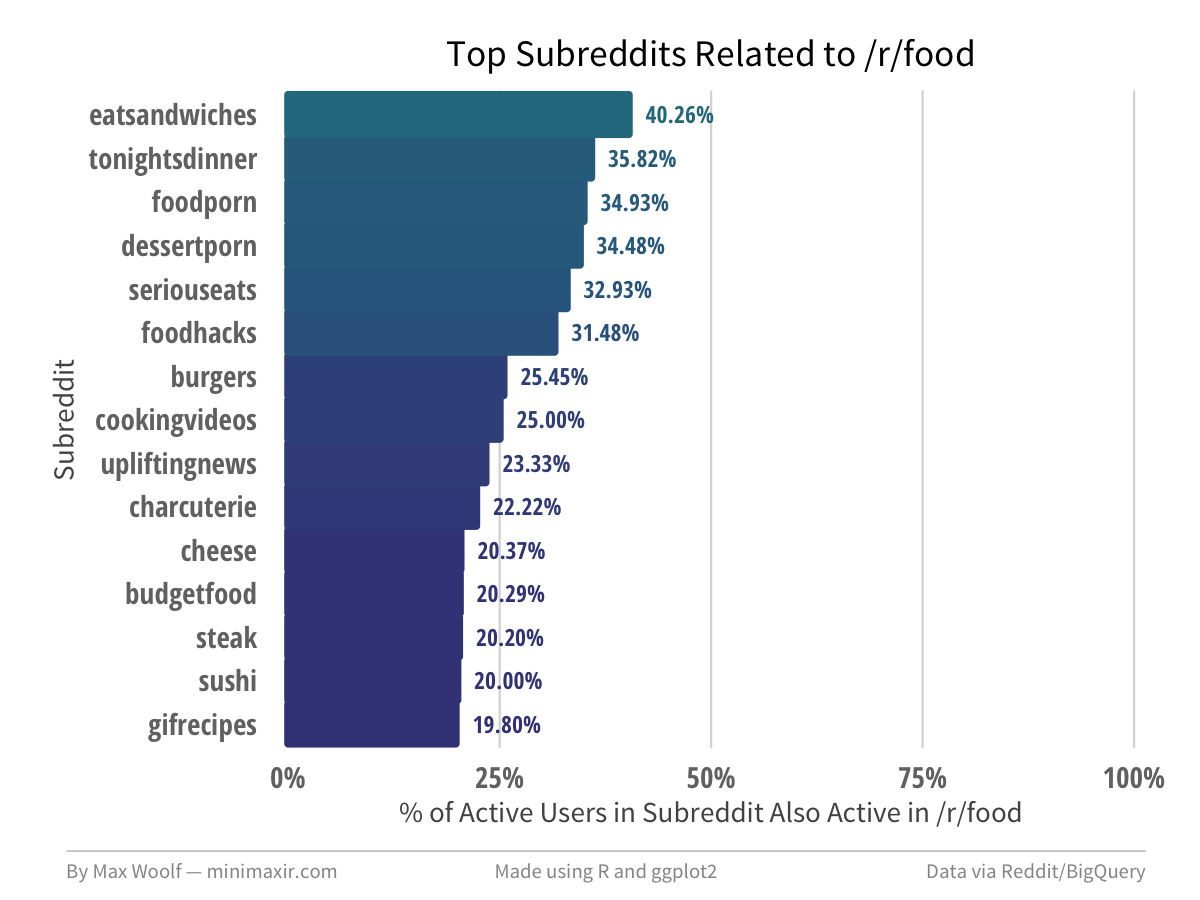
/r/food related subreddits list a surprising number of subreddits dedicated to specific foods.
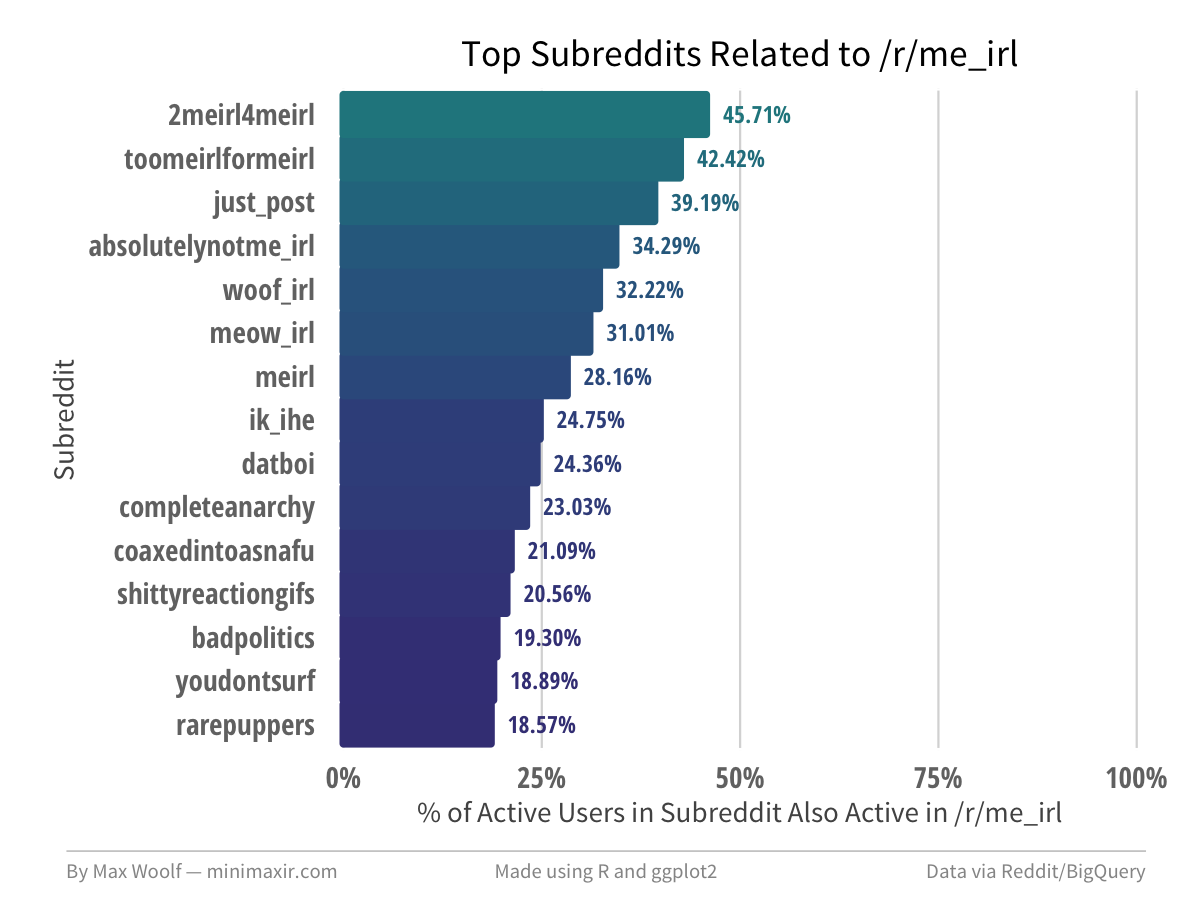
There is a surprising amount of depth to the /r/me_irl network.
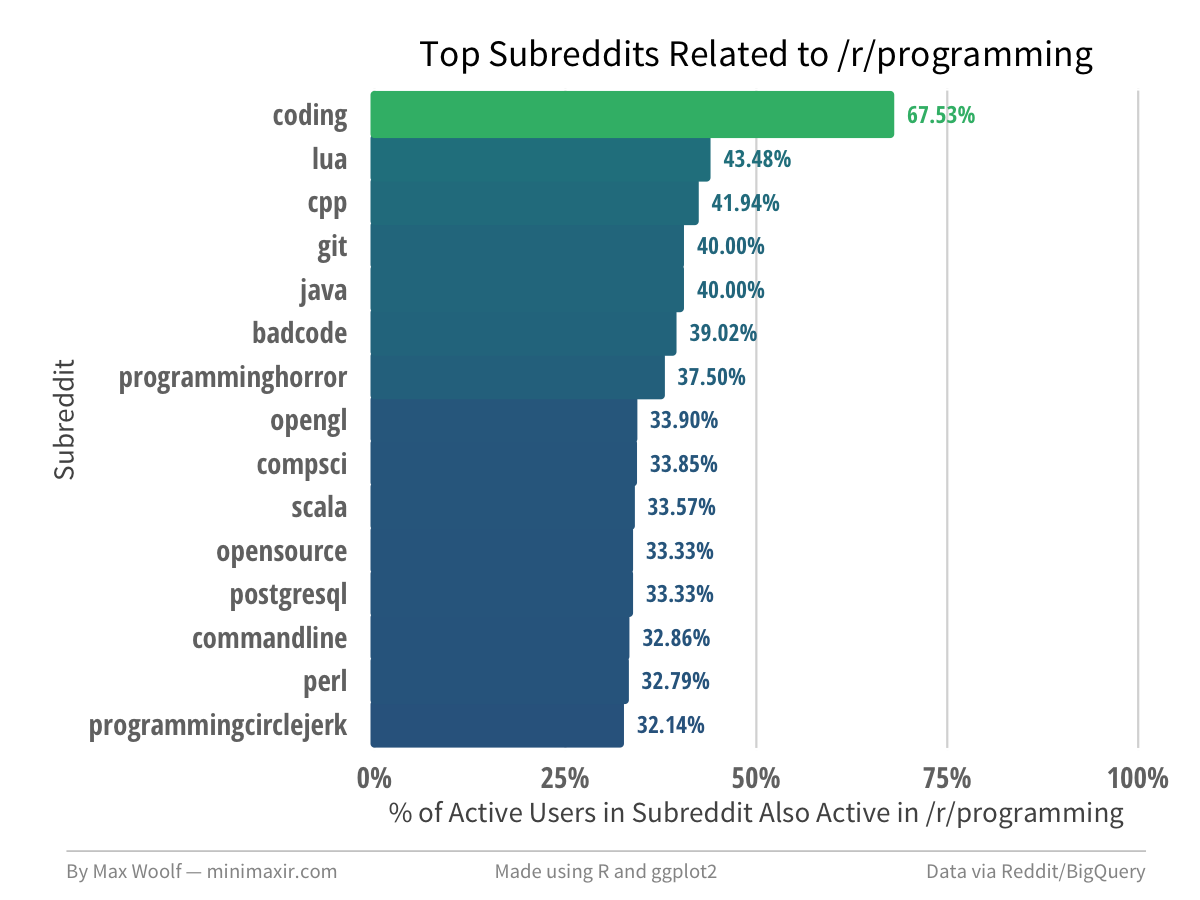
The chart for /r/programming can tell you which subreddits exist for specific programming languages and technologies.
The methodology can also reveal a lack of related subreddits, by the large contrast between subreddits with high relatedness and low relatedness. For example, while /r/cfb may have large numbers of obviously-related subreddits as a sports subreddit, /r/golf has only 2.
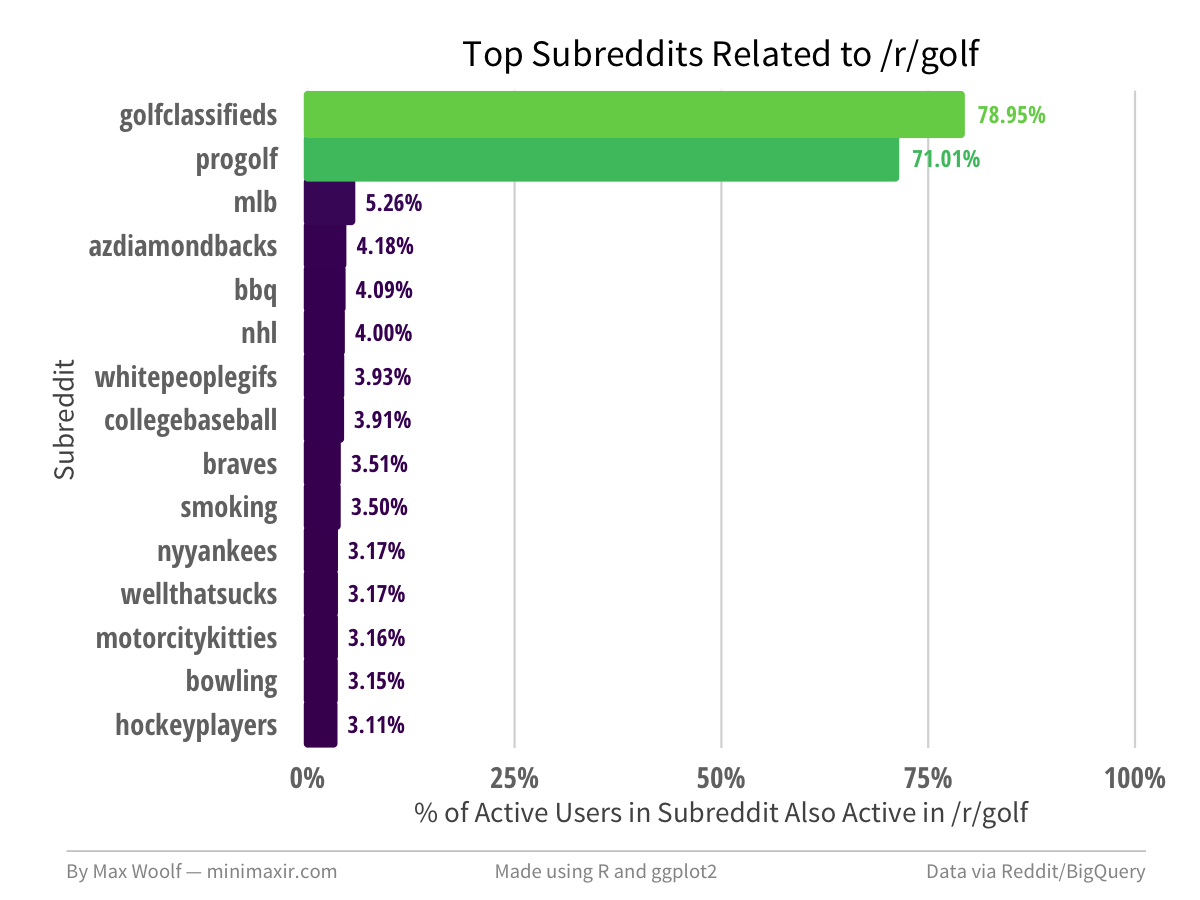
You can view Related Subreddit charts for the Top 200 Subreddits in this GitHub repository.
Finding Similar Subreddits
Another method for finding related subreddits would be to find subreddits with similar communities. An academic approach to finding similarity between sets is the Jaccard Index. Using the same set A and set B definitions above, the formula now becomes:
(A ∩ B) / [(A) + (B) - (A ∩ B)]
which outputs the Jaccard Index, between 0 and 1. This formula only requires a few tweaks to the original code. The results from this computation tell a different story.
Here are the most-similar subreddits to /r/aww:
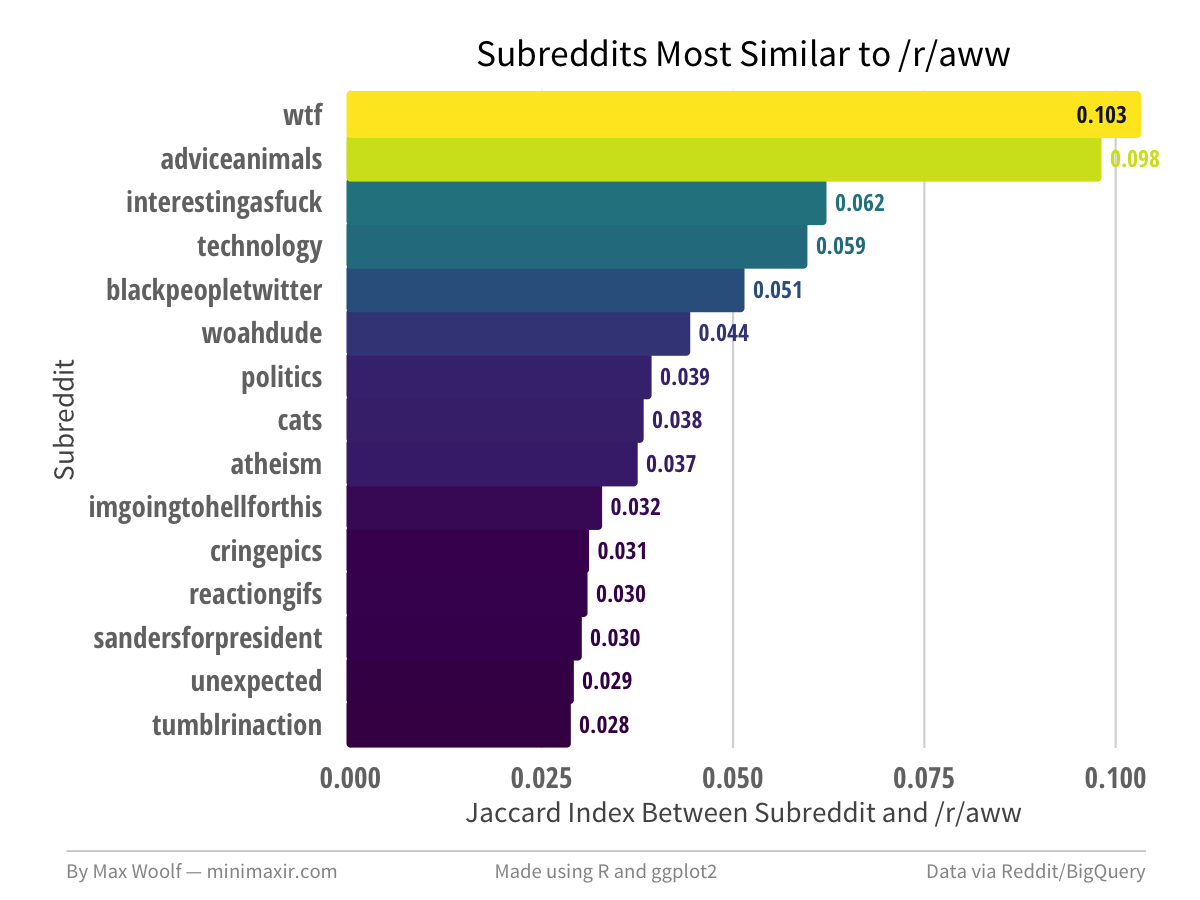
In this implementation, the default Reddit subreddits must be removed from the results, as the communities of default subreddits are largely similar to most others by design. Even former defaults like /r/adviceanimals and /r/technology still have large amounts of holdout users which skew the results. As /r/aww is a mass-appeal subreddit, it makes sense that the communities are similar to other mass-appeal subreddits.
The magnitude of the Jaccard Index measures the strength of the similarity. Most subreddit relationships have a low Jaccard Index, but the relative magnitude between all subreddit neighbors illustrate comparisons for potential related subreddits regardless (this is also the reason why the x-axis is not fixed across plots). The subreddit relationship with the highest absolute similarity is /r/arrow and /r/flashtv at 0.345, which make sense given the massive overlap between the two CW television shows.
The Jaccard Index is more useful for finding similar subreddits to niche subreddits. Let’s try a few of the subreddits mentioned previously and see how the results changed.
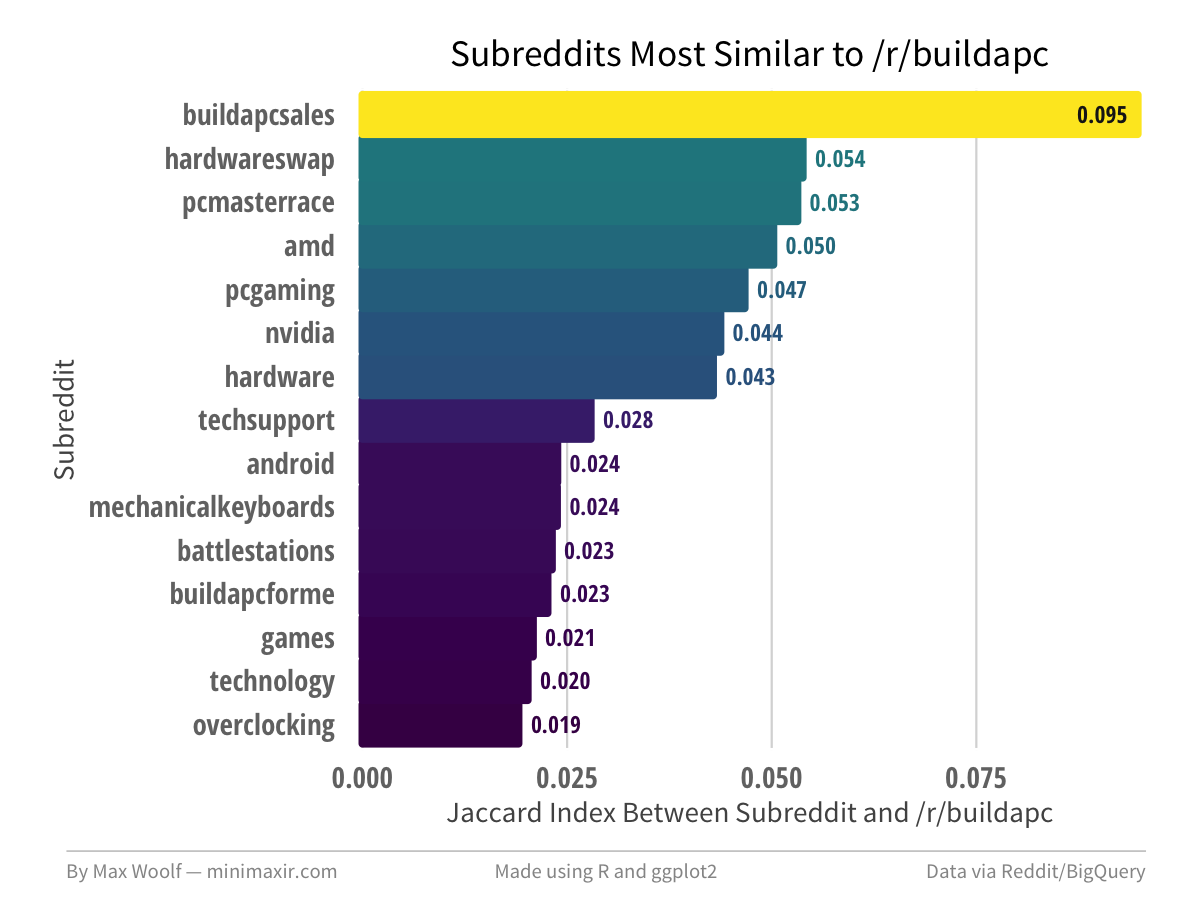
/r/buildapc is a niche, and the output identifies well-established subreddits, unlike with the previous related-subreddit methodology.
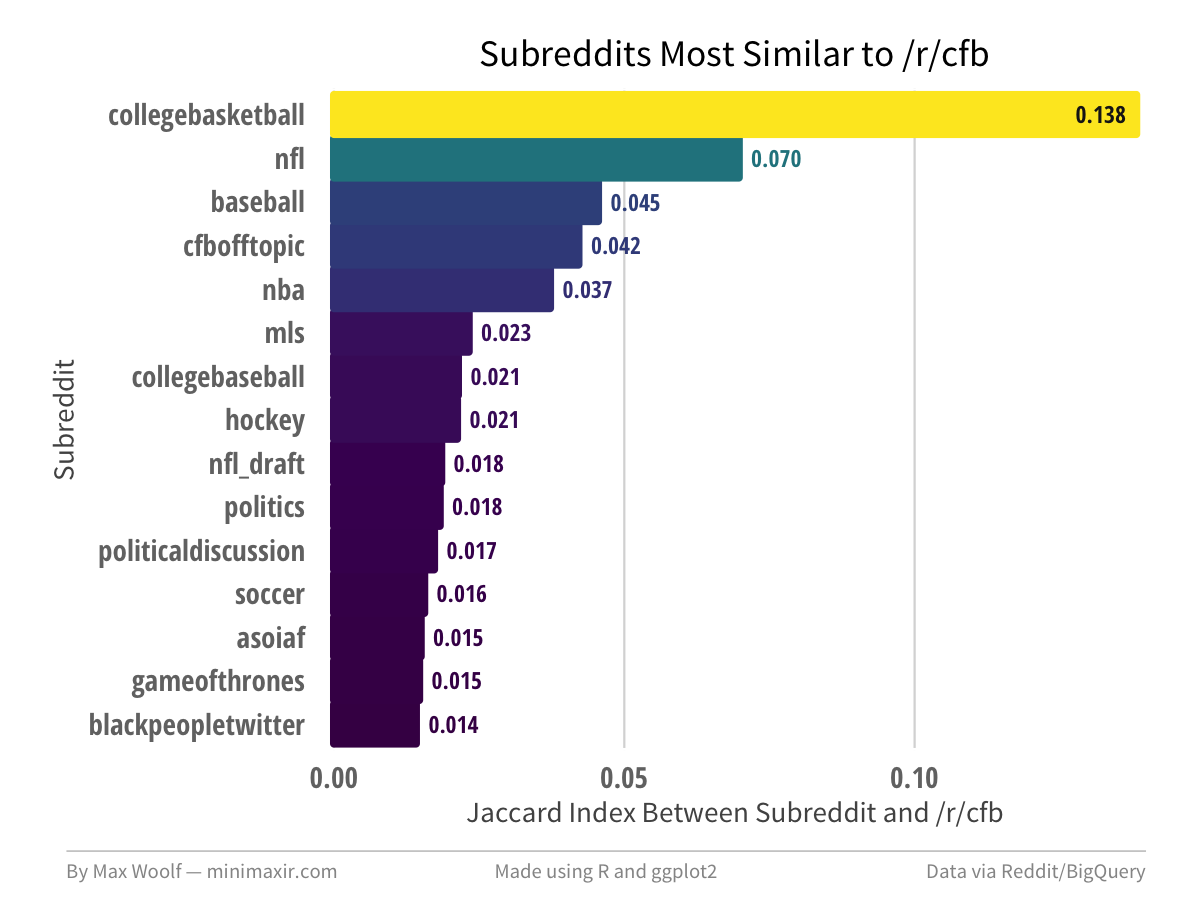
The subreddit most similar to /r/cfb (college football) is /r/collegebasketball!
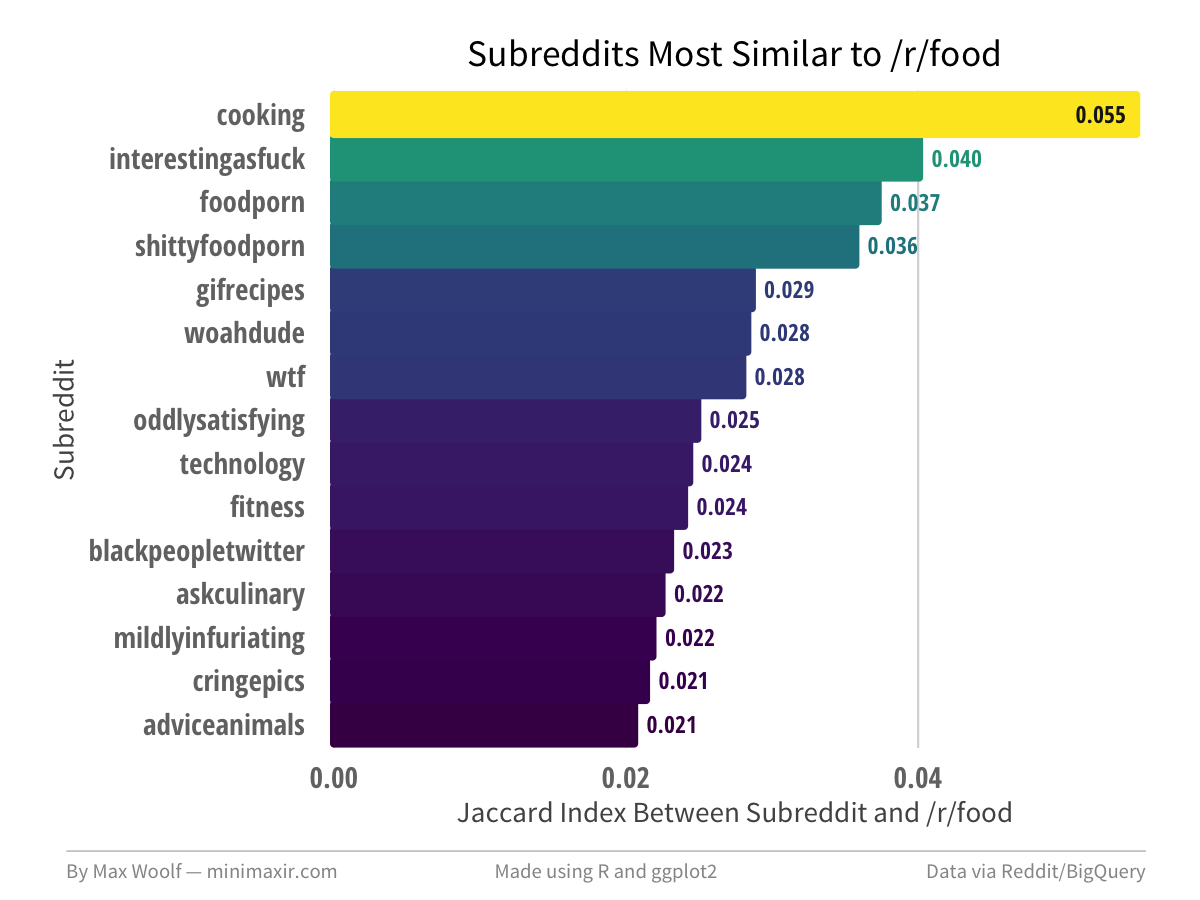
The subreddit most similar to /r/food is /r/cooking!
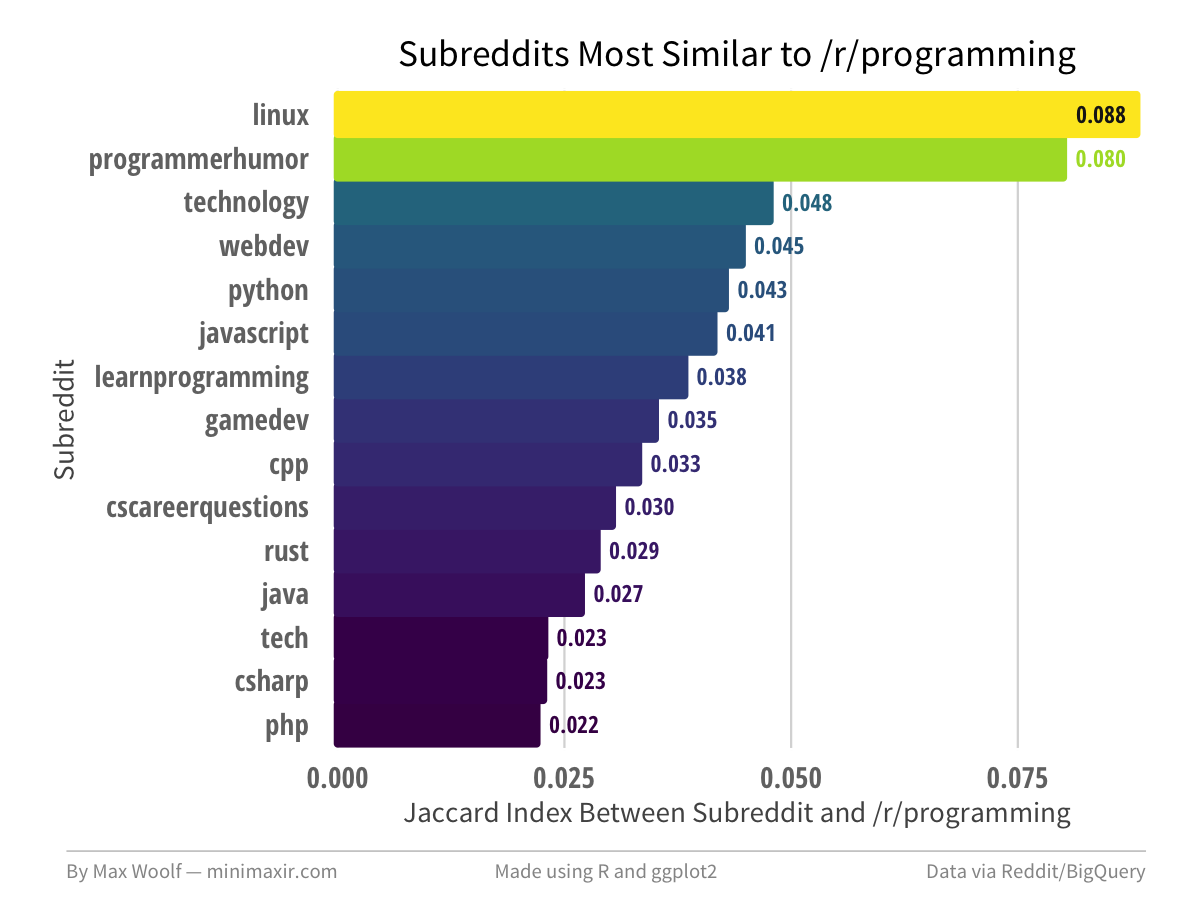
The subreddit most similar to /r/programming is /r/linux! (of course)
You can view the Similar Subreddit charts for the Top 200 Subreddits in this GitHub repository.
Again, Reddit has significantly better internal data for identifying user activity between subreddits, such as voting patterns and clickthrough tracking. But the results shown using these two set methodologies are pretty good for using public data. In fact, these two set approaches can theoretically work with any set of categorized, settable data, which may give me a few ideas for new blog posts in the future.
And there’s still the fancy machine learning approaches to try.
As always, the full code used to process the comment data and generate the visualizations is available in this Jupyter notebook, open-sourced on GitHub.
If you do find any other interesting trends in the related/similar charts of other subreddits and write about it, it would be greatly appreciated if proper attribution is given back to this post and/or myself. Thanks!
