UPDATE April 2018: Due to changes Facebook has made to the Graph API, the API will no longer return every post as noted in this article
One of the first data scrapers I wrote for the purpose of statistical analysis was a Facebook Graph API scraper, in order to determine which words are the most important in a Facebook Page status update. However, the v2.0 update to the Facebook API unsurprisingly broke the scraper.
Now that v2.4 of the Graph API is released, I gave the Facebook Graph API another look. Turns out, it’s pretty easy to scrape and make into a spreadsheet for easy analysis, although like with any other scrapers, there are a large number of gotchas.
Feasibility
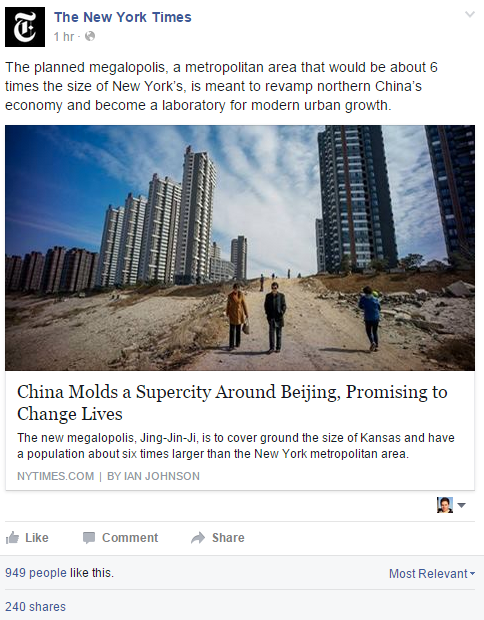
In order to determine if I can sanely scrape a website, I have to do a bit of research. How much data from a Facebook status update can we actually scrape?
Fortunately, Facebook’s Graph API documentation is pretty good. We need data from the /page node, and from there, we can access data from the /feed edge.
Between the two nodes, we have access to id, which is a unique identifer that can be used to create a link back to the update itself (e.g. https://www.facebook.com/5281959998_10150628170209999) message, the text of the update; link, the URL which the update is linking; name, the title of the webpage of the link, type, an identifier if the update is text, a photo, or a video; and created_time, when the update is published.
Accessing the numerical counts of likes, comments, and shares is less explicit in the documentation. Fortunately, StackOverflow has the answer: you need to request likes.limit(1).summary(true) instead of normal likes.
There’s no indication that there’s a Rate Limit, oddly. Since we can query 100 updates at a time, the scraper will be efficient enough that it’s unlikely to hit any extreme API limits.
Now that we know we can get all the relevant data from the sample status update, we can build a Facebook post scraper.
Data Scrappy
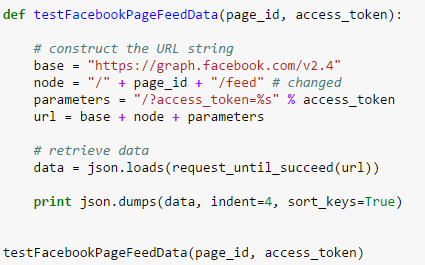
I have created an IPython notebook hosted on GitHub with detailed code, code comments, and sample output for each step of the scraper development. I strongly recommend giving it a look.
First, we need to see how to actually access the API. It’s no longer a public API, and it requires user authentication via access tokens. Users can get Short-Term tokens, but as their name suggests, they expire quickly, so they are not recommended. The Graph API allows a neat trick; by concatenating the App ID from a user-created App and the App Secret, you create an access token which never expires. Of course, this is a major security risk, so create a separate app for the sole purpose of scraping, and reset your API Secret if it becomes known.
Let’s say we want to scrape the New York Times’ Facebook page. We would send a request to https://graph.facebook.com/v2.4/nytimes?access_token=XXXXX and we would get:
{
"id": "5281959998",
"name": "The New York Times"
}
i.e., the page metadata. Sending a request to /nytimes/feed results in what we want:
{
"data": [
{
"created_time": "2015-07-20T01:25:01+0000",
"id": "5281959998_10150628157724999",
"message": "The planned megalopolis, a metropolitan area that would be about 6 times the size of New York\u2019s, is meant to revamp northern China\u2019s economy and become a laboratory for modern urban growth."
},
{
"created_time": "2015-07-19T22:55:01+0000",
"id": "5281959998_10150628161129999",
"message": "\"It\u2019s safe to say that federal agencies are not where we want them to be across the board,\" said President Barack Obama's top cybersecurity adviser. \"We clearly need to be moving faster.\""
}
]
}
Now we get the post data. But not much of it. In Graph API v2.4, the default behavior is to return very, very little metadata for statuses in order to reduce bandwidth, with the expectation that the user will request the necessary fields.
So let’s request all the fields we want. This results in a very long URL not shown here which causes the posts feed to have all the data we need:
{
"comments": {},
"summary": {
"order": "ranked",
"total_count": 31
},
"created_time": "2015-07-20T01:25:01+0000",
"id": "5281959998_10150628157724999",
"likes": {
"data": {},
"summary": {
"total_count": 278
}
},
"link": "http://nyti.ms/1Jr6LhU",
"message": "The planned megalopolis, a metropolitan area that would be about 6 times the size of New York’s, is meant to revamp northern China’s economy and become a laboratory for modern urban growth.",
"name": "China Molds a Supercity Around Beijing, Promising to Change Lives",
"shares": {
"count": 50
},
"type": "link"
}
Post Processing
Great! Now we just have to process each post. Which is easier said than done.
If you’re an avid Facebook user, you know that not all of these attributes are not guaranteed to exist. Status updates may not have text or links. Since we’re making a spreadsheet with an enforced schema, we need to validate that a field exists before attempting to process it.
The “\u2019"s in the message correspond to a smart quote apostrophe. Since this a possibility, along with other unicode characters, the message and link names must be encoded in UTF-8 to prevent errors.
The time format is another issue. The date follows the ISO 8601 standard for UTC times. However, most spreadsheet programs will not able to parse it as a Date value. Also, since the NYT is based in the USA (specifically, New York), it may be helpful for time-based statistical analysis to convert the time to Eastern Standard Time while fixing the date format.
There’s also an unexpected precaution that must be taken whenever scraping data sets. These APIs do not expect users to be accessing very, very old data. As a result, there’s a high probability of the API server actually hitting an error sometime during the scrape, such as a HTTP Status 500 or HTTP Status 502. These server errors are temporary, so a helper function must be used to attempt to retrieve data until it is actually successful.
Putting it All Together
Now we have a full plan for scraping, we query each page of Facebook Page Statuses (100 statuses maximum per page), process all statuses on that page and writing the output to a CSV file, and navigate to the next page, and repeat until no more statuses left.
This can be done with a for-loop within a while loop. In addition, I also recommend counting the number of posts processed and taking a timestamp every-so-often to ensure that the program has not stalled.
And that’s it! You can access the complete scraper in this GitHub repository, along with all other scripts mentioned in this article. Once you have the CSV file, you can import it into nearly every statistical program and have fun with it. (You can download a .zip of the NYTimes data here [4.6MB])
Say, for example, what would happen if we compared the Median Likes of the New York Times with a certain other journalistic website that’s the master of social media?
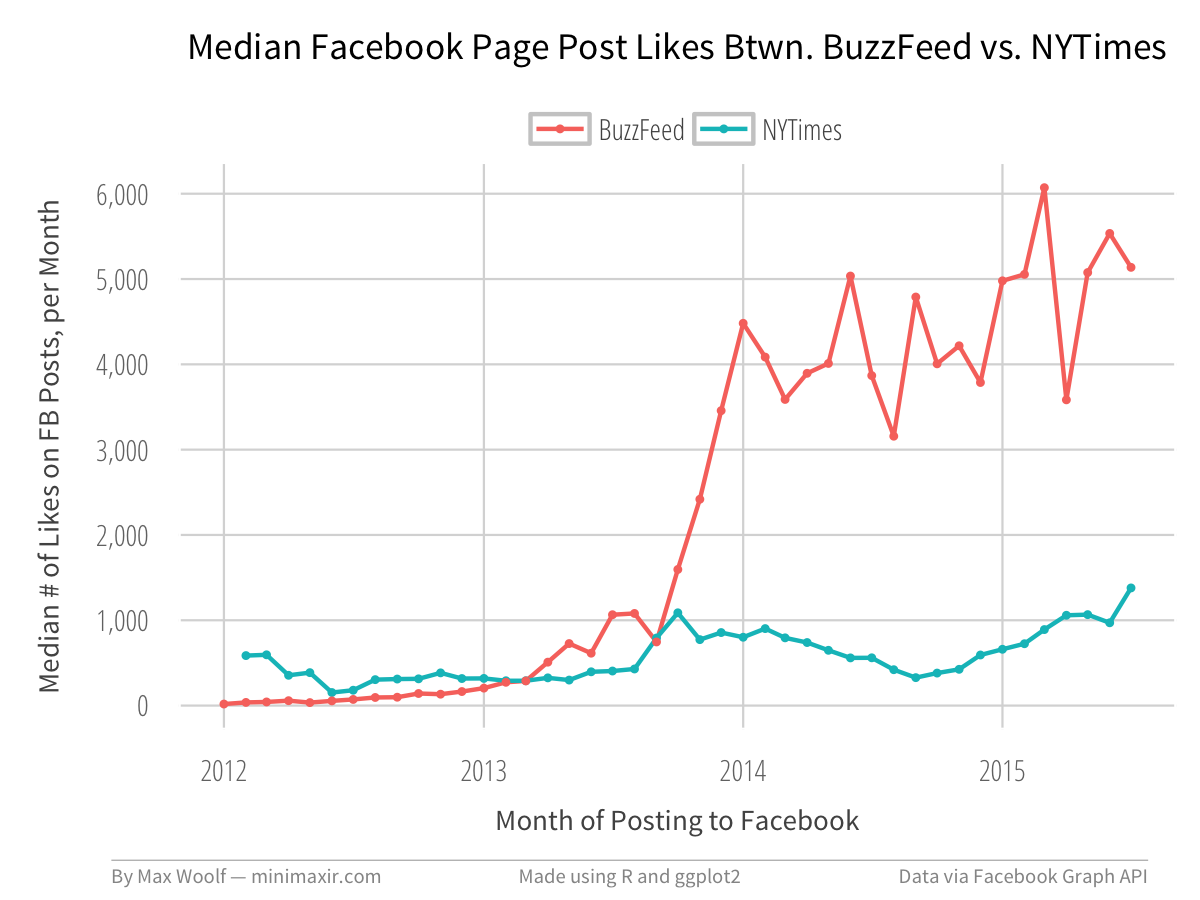
There may be more practical reasons for analyzing data on Facebook Posts, such as quantifying the growth and success of your own page, or that of your competitors. But the data is easy to get and is very useful.
Although, in fairness, the scraper is not perfect and still has room for improvement. With CNN’s Facebook Page post data, for example, somehow the scraper skips all posts from 2013. Although in that case, I blame Facebook.
You can access all resources used in this blog post at this GitHub repository.
If you haven’t, I strongly recommend looking at the IPython Notebook for more detailed coding methodology.
And, as an experiment, I’ve made an IPython notebook with the R kernel showing how I made the NYT-BuzzFeed chart!
