Instagram uses hashtags as a method of categorizing images and videos. A user can tag an image with, for example, #snowy, and all other Instagram app users can see a mosaic of photos from all users which have that tag. Many less-than-honest Instagram users spam tags which are not particularly relevant to their photo in order to maximize the potential exposure.

At a maximum of 30 tags per image, spamming large numbers of tags should theoretically have a huge impact on the image’s reach. In fact, there are sketchy websites that provide premade lists of popular hashtags for you to spam. But does spamming #tags in an Instagram image actually lead to a increase in the number of Likes on an image?
Using the Instagram API, I’ve retrieved about 120,000 images, split evenly between pictures tagged with #sunny, #rainy, and #snowy, to get a good range of neutral picture types. Here’s the distribution of the number of tags on photos from that data set:
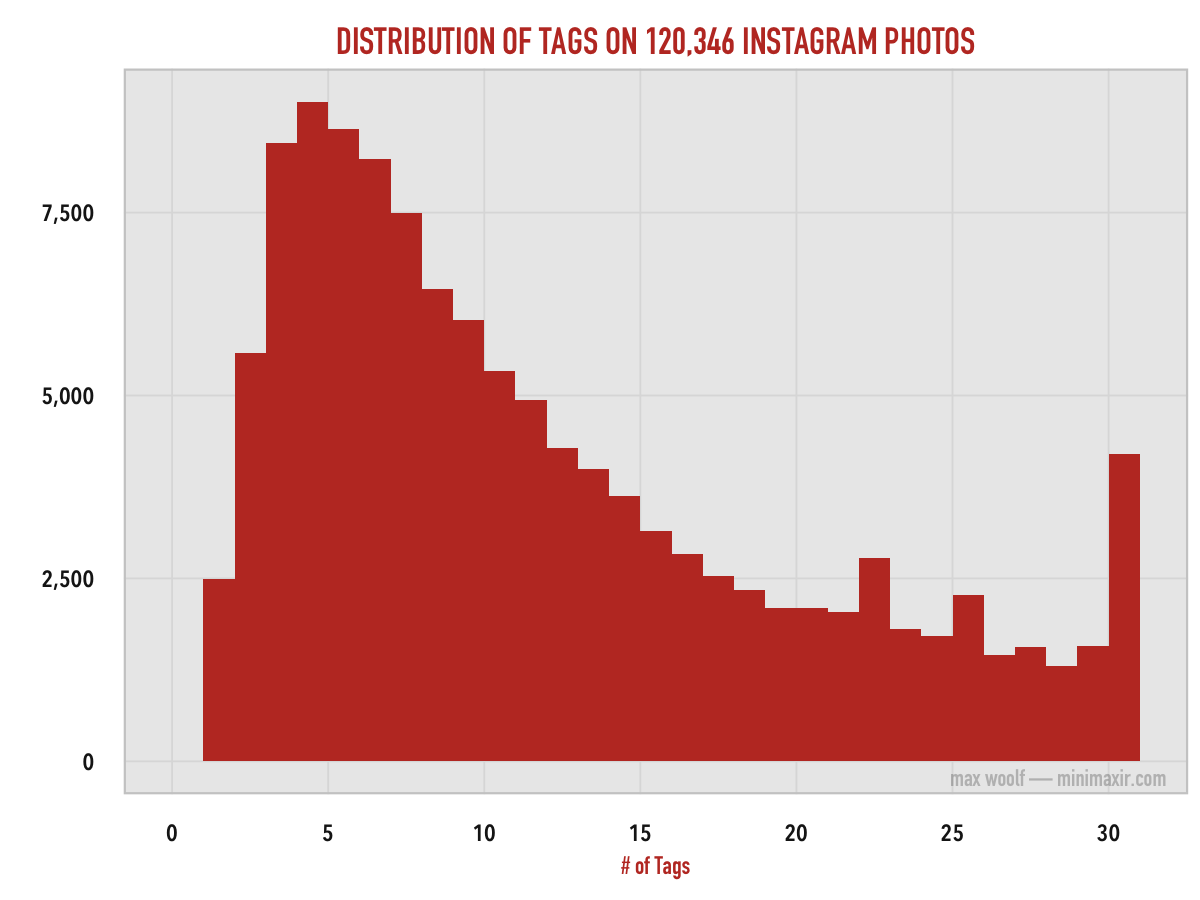
The majority of Instagram photos have around 5 tags, which is a reasonable amount for a user quickly classifying a photo within the photo caption. However, it’s clear that there are many tag abusers, with a noticeable spike of the number of Instagram photos which have the maximum of 30 #tags. (the statistical average is 11.45 tags, with a standard deviation of 8.01)
The distribution of Likes as heavily skewed as you would expect when viewed normally, but when the distribution is viewed on a logarithmic scale, the shape becomes closer to a bell curve:
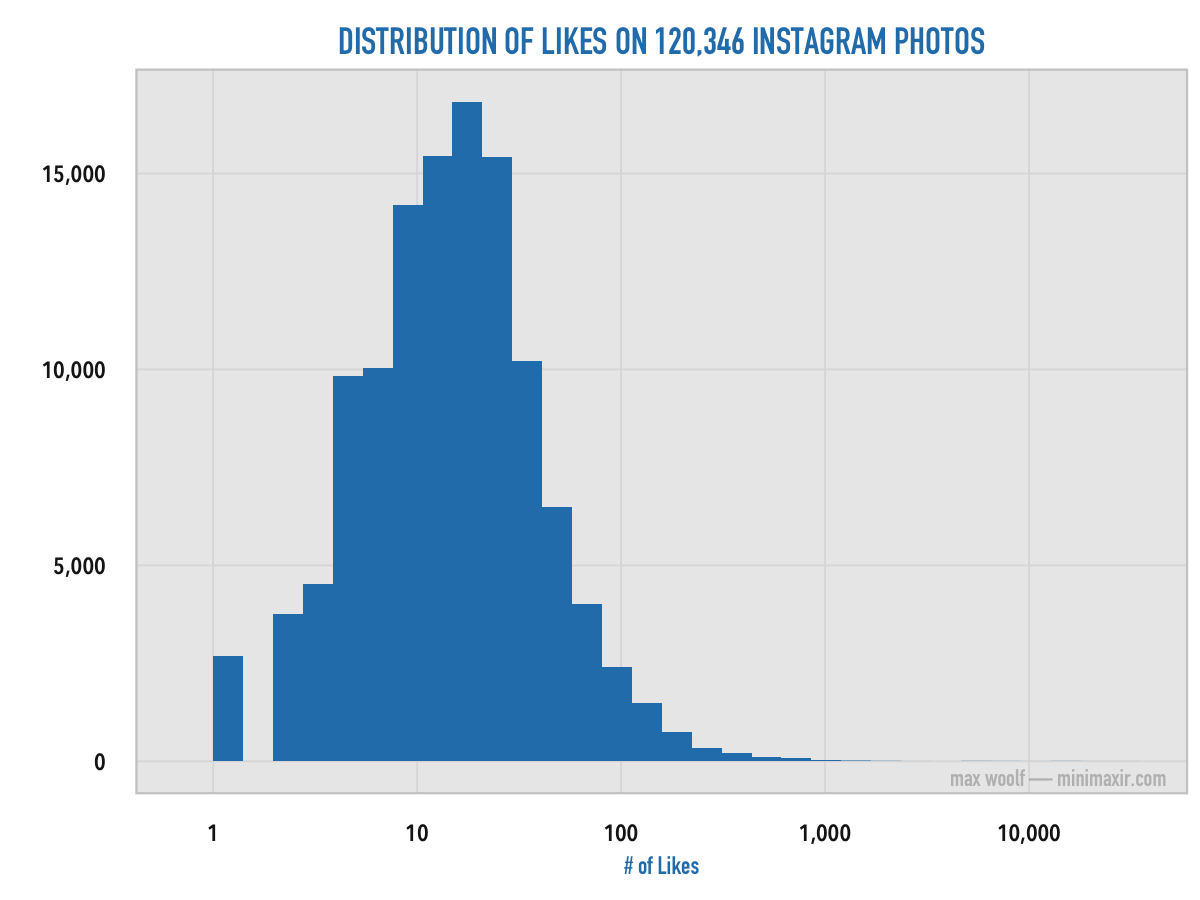
The statistical average of Likes on Instagram photos is 26.19 Likes, with a standard deviation of 154.07; the high standard deviation is caused by the few photos with thousands of Likes.
If you analyze the distribution of Likes for each discrete number of tags, the results are more telling.
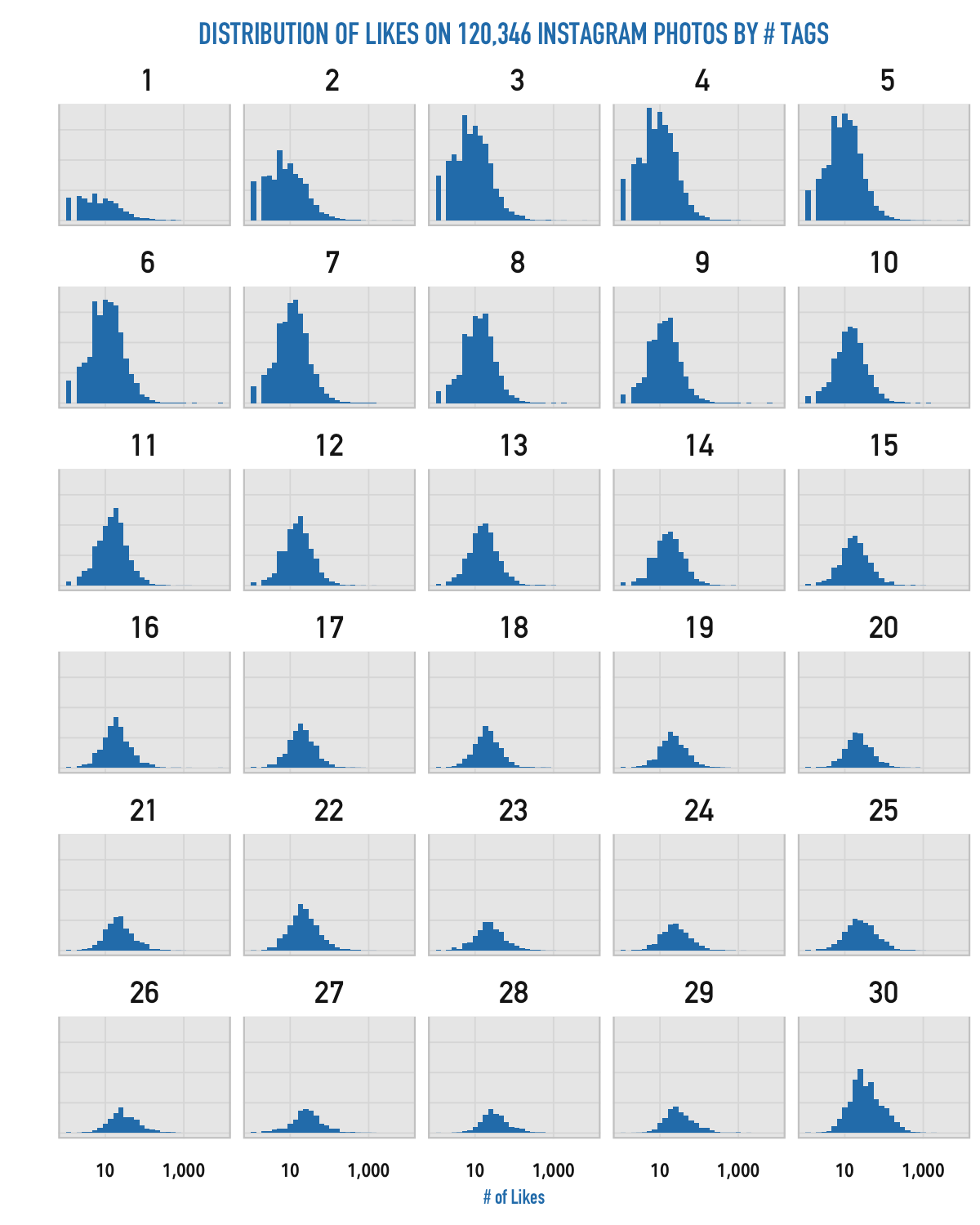
As the number of tags increases, the distribution of Likes shifts toward right, with very, very few photos with less than 10 likes. However, due to the logarithmic scaling, it’s hard to tell if the center of the distibution (where the average number of Likes is approximately located) is shifting significantly.
Regression Analysis
A simple linear regression of log(Likes) on tags can tell us of the if an increase in the number of tags corresponds to an increase in the number of Likes.
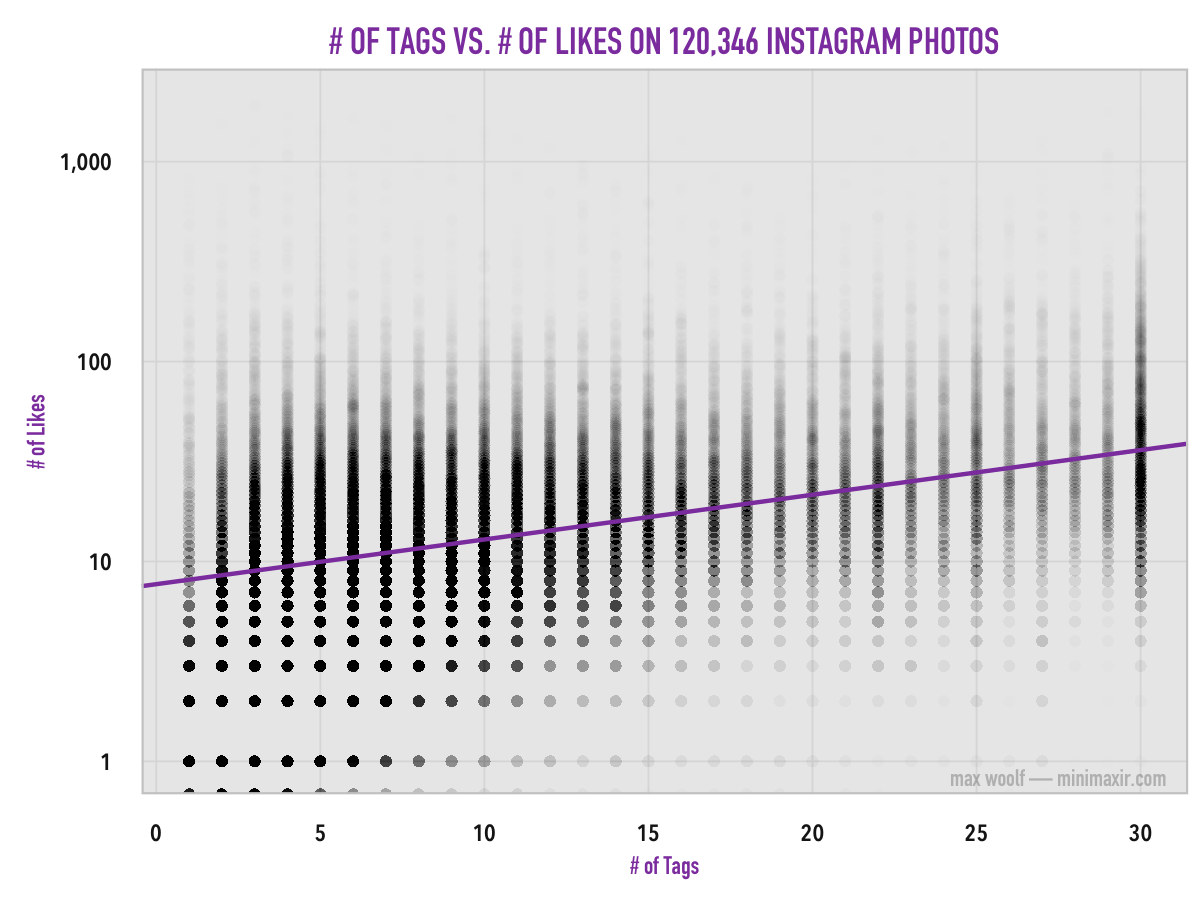
There is indeed a very strong positive relationship between Tags and Likes, with a p-value < 2e-16 for the tag regression coefficient. But tags alone doesn’t explain the variance of Likes particularly well (R2 = 15.47%) due to the heavy variance of Likes in the raw data, even after using a logarithmic transformation. However, due to the logarithmic transformation, it’s difficult to easily determine the relative difference in the amount of Likes between using 1 tag on an Instagram photo and using 30 tags.
Using the raw, untransformed data, this is a chart of the average number of Likes on photos from the sample data for each discrete number of tags, with 95% confidence intervals* for each measure:
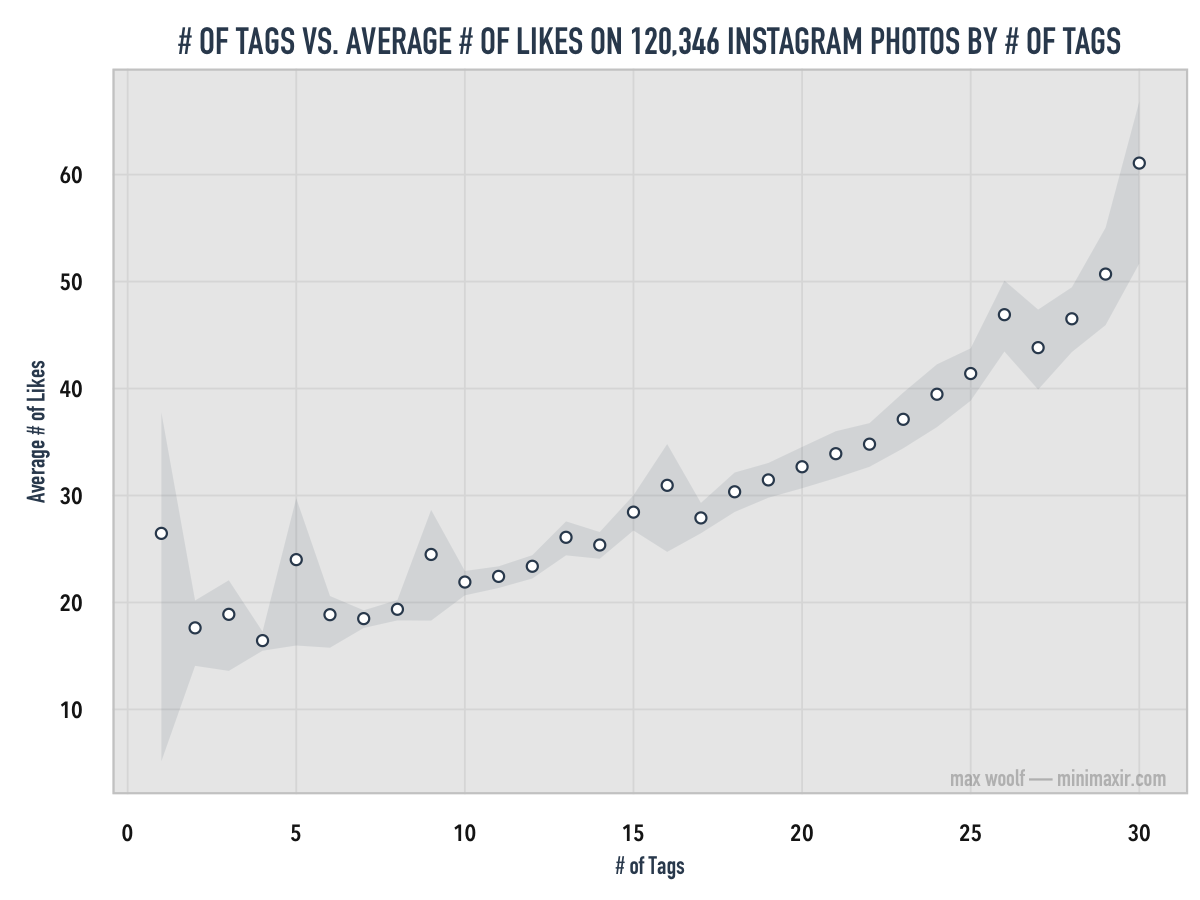
Instagram photos which have the maximum of 30 #tags receive, on average, about three times as many Likes than photos with only a few tags. Most of the averages are well-bounded, too, which indicate that the per-tag-Like-averages are well-representative of all Instagram photos.
The strong deviations from the trend (and larger confidence intervals) at 1, 5, and 9 tags are due to large outliers which skew the average. Indeed, there are many other factors in determining the expected number of Likes for an Instagram photo (e.g. the popularity of the person who posted the photo), some of which I hope to cover in a future blog post. :)
In the meantime, if you want more Likes on your filtered photos, spam those hashtags. You won’t be guaranteed to gets lots of Likes, but the odds will greatly be in your favor.
All charts were created using R and ggplot2.
You can download a copy of the Instagram data set here. [2MB zipped CSV]
*95% confidence intervals for each per-tag-Like-average were generated using bootstrap resampling of the raw data, and recalculating each average on the resampled data. This was repeated 5,000 times to generate upper and lower bounds.
